
在人工智能迅速发展的今天,深度神经网络广泛应用于各个研究领域并取得了巨大的成功,但也同样面 临着诸多挑战.首先,为了解决复杂的问题和提高模型的训练效果,模型的网络结构逐渐被设计得深而复杂,难以 适应移动计算发展对低资源、低功耗的需求.知识蒸馏最初作为一种从大型教师模型向浅层学生模型迁移知识、提 升性能的学习范式被用于模型压缩.然而随着知识蒸馏的发展,其教师学生的架构作为一种特殊的迁移学习方 式,演化出了丰富多样的变体和架构,并被逐渐扩展到各种深度学习任务和场景中,包括计算机视觉、自然语言处 理、推荐系统等等.另外,通过神经网络模型之间迁移知识的学习方式,可以联结跨模态或跨域的学习任务,避免知 识遗忘;还能实现模型和数据的分离,达到保护隐私数据的目的.知识蒸馏在人工智能各个领域发挥着越来越重要 的作用,是解决很多实际问题的一种通用手段.本文将近些年来知识蒸馏的主要研究成果进行梳理并加以总结,分析该领域所面临的挑战,详细阐述知识蒸馏的学习框架,从多种分类角度对知识蒸馏的相关工作进行对比和分析, 介绍了主要的应用场景,在最后对未来的发展趋势提出了见解.

随着深度神经网络的崛起和演化,深度学习在 计算机视觉、自然语言处理、推荐系统等 各个人工智能的相关领域中已经取得了重大突破. 但是,深度学习在实际应用过程中的也存在着一些 巨大的挑战.首先,为了应对错综复杂的学习任务, 深度学习的网络模型往往会被设计得深而复杂:比 如早期的LeNet模型只有5层,发展到目前的通用 的ResNet系列模型已经有152层;伴随着模型的 复杂化,模型的参数也在逐渐加重.早期的模型参数 量通常只有几万,而目前的模型参数动辄几百万.这 些模型的训练和部署都需要消耗大量的计算资源, 且模型很难直接应用在目前较为流行的嵌入式设备 和移动设备中.其次,深度学习应用最成功的领域是 监督学习,其在很多任务上的表现几乎已经超越了 人类的表现.但是,监督学习需要依赖大量的人工标 签;而要实现大规模的标签任务是非常困难的事情, 一方面是数据集的获取,在现实场景中的一些数据 集往往很难直接获取.比如,在医疗行业需要保护患 者的隐私数据,因而数据集通常是不对外开放的.另 一方面,大量的用户数据主要集中在各个行业的头 部公司的手中,一些中小型公司无法积累足够多的 真实用户数据,因此模型的效果往往是不理想的;此 外,标注过程中本身就需要耗费很大的人力、物力、 财力,这将极大限制人工智能在各个行业中的发展 和应用.最后,从产业发展的角度来看,工业化将逐 渐过渡到智能化,边缘计算逐渐兴起预示着AI将 逐渐与小型化智能化的设备深度融合,这也要求模 型更加的便捷、高效、轻量以适应这些设备的部署. 针对深度学习目前在行业中现状中的不足, Hinton等人于2015首次提出了知识蒸馏(Knowledge Distillation,KD)[10],利用复杂的深层网络模型向浅 层的小型网络模型迁移知识.这种学习模型的优势在于它能够重用现有的模型资源,并将其中蕴含的 信息用于指导新的训练阶段;在跨领域应用中还改 变了以往任务或场景变化都需要重新制作数据集和 训练模型的困境,极大地节省了深度神经网络训练 和应用的成本.通过知识蒸馏不仅能够实现跨领域 和跨模态数据之间的联合学习还能将模型和知识 表示进行分离,从而在训练过程中将教师模型作为 “黑盒”处理,可以避免直接暴露敏感数据,达到隐私 保护效果.
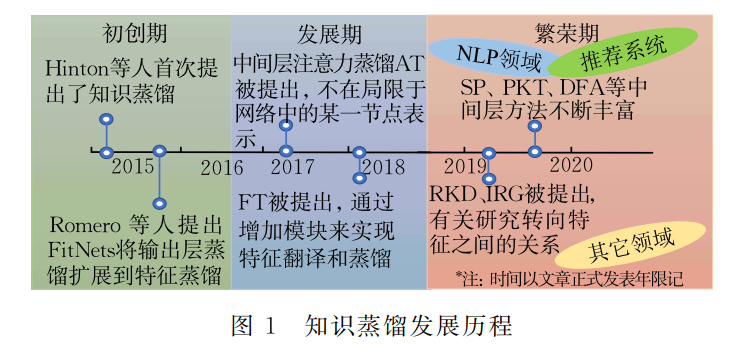
知识蒸馏作为一种新兴的、通用的模型压缩和 迁移学习架构,在最近几年展现出蓬勃的活力,其发 展历程也大致经历了初创期,发展期和繁荣期.在初 创期,知识蒸馏从输出层逐渐过渡到中间层,这时期 知识的形式相对简单,较为代表性的中间层特征蒸 馏的方法为Hints.到了发展期,知识的形式逐 渐丰富、多元,不再局限于单一的节点,这一时期较 为代表性的蒸馏方法有AT、FT.在2019年前 后,知识蒸馏逐渐吸引了深度学习各个领域研究人 员的目光,使其应用得到了广泛拓展,比如在模型应 用上逐渐结合了跨模态、跨领域、持续学习、隐私保护等;在和其他领域交叉过程 中又逐渐结合了对抗学习、强化学习、元 学习、自动机器学习、自监督学习等. 如下图1为知识蒸馏的发展历程和各个时期较为代 表性的工作.
知识蒸馏虽然有了较为广阔的发展,但是在其 发展过程和实际应用中也同样面临着这一些挑战;知识蒸馏的挑战主要可以分为实际应用中面临的挑 战和模型本身理论上的挑战.应用中的挑战主要有 模型问题、成本问题;而理论上面存在的主要挑战也 是目前深度学习普遍存在的一些挑战,包括模型的 不可解释性等: 模型问题.在实际工业应用中针对不同的任务 教师模型多样,而如果教师和学生模型不匹配,可能 会使学生模型无法模仿深层大容量的教师模型,即 大模型往往不能成为更好的老师.因此,应用中需要 考虑深层模型和浅层模型之间的容量差距,选择相 匹配的教师学生模型. 成本问题.模型训练过程对超参数较为敏感以及 对损失函数依赖较大,而相关原因很难用原理去解 释,需要大量的实验,因而模型的试错成本相对较高. 可解释性不足.关于知识蒸馏的原理解释主要 是从输出层标签平滑正则化、数据增强等角度出发, 而关于其他层的方法原理解释相对不足;目前,虽然 关于泛化边界的研究也在兴起,但是并不能全面解 释知识的泛化问题,还需要有更进一步的探究,才能 保证理论的完备性.
目前,知识蒸馏已经成为一个热门的研究课题, 关于知识蒸馏的论文和研究成果非常丰富.各种新 方法、新任务、新场景下的研究纷繁复杂,使得初学 者难以窥其全貌.当前已有两篇关于知识蒸馏的综 述,均发表于2021年.相较于前者,本文在 分类上作了进一步细化,如在知识形式上,本文关注 到了参数知识及蒸馏中常见的中间层的同构和异构 问题;虽然该文献中也提及了基于图的算法,但是本 文以为基于图形式构建的知识表示是一种新兴的、 独立的、特殊的知识形式,单独归为一类更为合理. 相较于后者[40]本文在结构分类上更加宏观,以知识 形式、学习方式和学习目的为主要内容将知识蒸馏 的基础解析清楚,而后在此基础之上对其交叉领域 和主要应用进行展开.本文的主要贡献可总结如下:(1)结构较为完善,分类更加细化.对于知识的 分类,本文是依据知识蒸馏的发展脉络对其进行归 类并细化,增加了中间层知识、参数知识、图表示知 识,完整地涵盖了目前知识的全部形式.在文章的结 构上,既保证了分类的综合性,又避免了过多分类造 成的杂糅,更为宏观. (2)对比详细,便于掌握.本文以表格的方式对 同的方法之间的优缺点、适用场景等进行详细的总 结对比,以及对比了不同知识形式蒸馏的形式化方 法,使得读者能够快速准确地区分其中的不同点.(3)内容完整,覆盖全面.本文遵循了主题式分 类原则不仅分析了单篇文献,还分析相关领域中知 识蒸馏的重要研究.除此之外,本文以独立章节对知 识蒸馏的学习目的,原理和解释,发展趋势等方面做 了较为全面的阐释. 本文接下来将从知识蒸馏的整体框架从发,并 对其各个分类进行详细的阐述,使得读者能够从宏 观上对知识蒸馏有更全面的了解,以便更好地开展 相关领域的学习与研究.本文将按照以下结构组织:第2节首先介绍知识蒸馏的理论基础及分类;第3~6节分别按照知识传递形式、学习方式、学习 目的、交叉领域的顺序,从4个不同角度对知识蒸馏 的相关工作进行分类和对比,并分析不同研究方向 面临的机遇和挑战;第7节列举知识蒸馏在计算机 视觉、自然语言处理、推荐系统等领域的一些应用性 成果;第8节对知识蒸馏的原理和可解释性方面的 工作进行梳理;最后,对知识蒸馏在深度学习场景 下的未来发展趋势提出一些见解,并进行全文总结.
理论基础及分类**
知识蒸馏本质上属于迁移学习的范畴,其主要 思路是将已训练完善的模型作为教师模型,通过控 制“温度”从模型的输出结果中“蒸馏”出“知识”用于 学生模型的训练,并希望轻量级的学生模型能够学 到教师模型的“知识”,达到和教师模型相同的表现. 这里的“知识”狭义上的解释是教师模型的输出中 包含了某种相似性,这种相似性能够被用迁移并辅 助其他模型的训练,文献[10]称之为“暗知识”;广义 上的解释是教师模型能够被利用的一切知识形式, 如特征、参数、模块等等.而“蒸馏”是指通过某些 方法(如控制参数),能够放大这种知识的相似性,并 使其显现的过程;由于这一操作类似于化学实验中 “蒸馏”的操作,因而被形象地称为“知识蒸馏”.
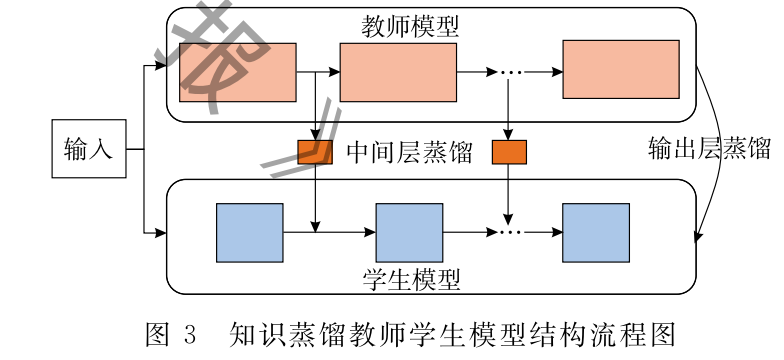
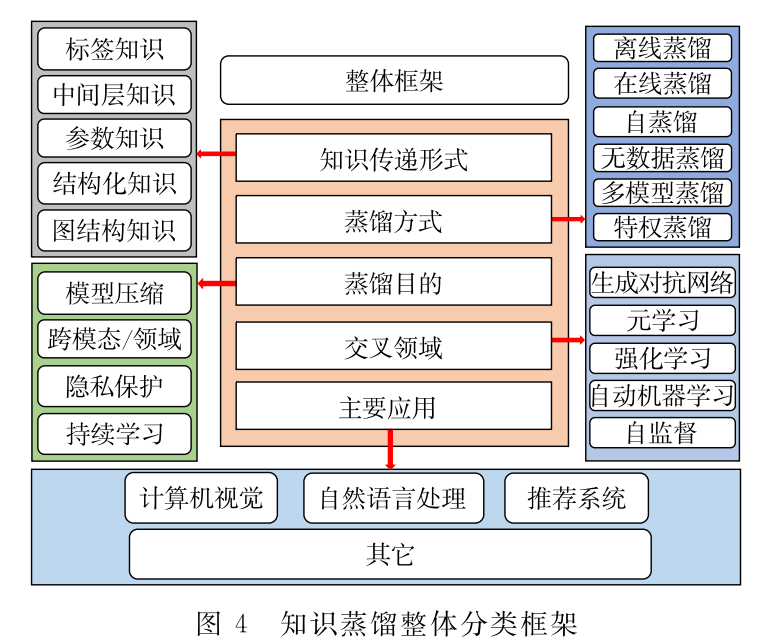
如图3是知识蒸馏模型的整体结构.其由一个 多层的教师模型和学生模型组成,教师模型主要负 责向学生模型传递知识,这里的“知识”包括了标签 知识、中间层知识、参数知识、结构化知识、图表示知 识.在知识的迁移过程中,通过在线或离线等不同的 学习方式将“知识”从教师网络转移到了学生网络. 为了便于读者快速学习和对比其中的差异,作者将 不同知识传递形式下的蒸馏方法的形式化表示及其 相关解释整理为表1所示结果.此外,本文对知识蒸 馏相关研究进行了总结,主要从知识传递形式、学习 的方式、学习的目的、交叉领域、主要应用等方面对 其进行分类,其分类框架如图4所示,具体内容将在 后续的文章中展开.

知识传递形式
知识蒸馏方法的核心在于“知识”的设计、提取和 迁移方式的选择,通常不同类型的知识来源于网络模 型不同组件或位置的输出.根据知识在教师学生模型 之间传递的形式可以将其归类为标签知识、中间层知 识、参数知识、结构化知识和图表示知识.标签知识一 般指在模型最后输出的logits概率分布中的软化目标 信息;中间层知识一般是在网络中间层输出的特征图 中表达的高层次信息;参数知识是训练好的教师模型 中存储的参数信息;结构化知识通常是考虑多个样本 之间或单个样本上下文的相互关系;图表示知识一般 是将特征向量映射至图结构来表示其中的关系,以满 足非结构化数据表示的学习需求.本节主要对蒸馏知 识的5类传递形式加以介绍,理清主流的知识蒸馏基础 方法,后面介绍的各类蒸馏方法或具体应用都是以此 为基础.相关的优缺点和实验对比,见表2~表4所示.



学习方式
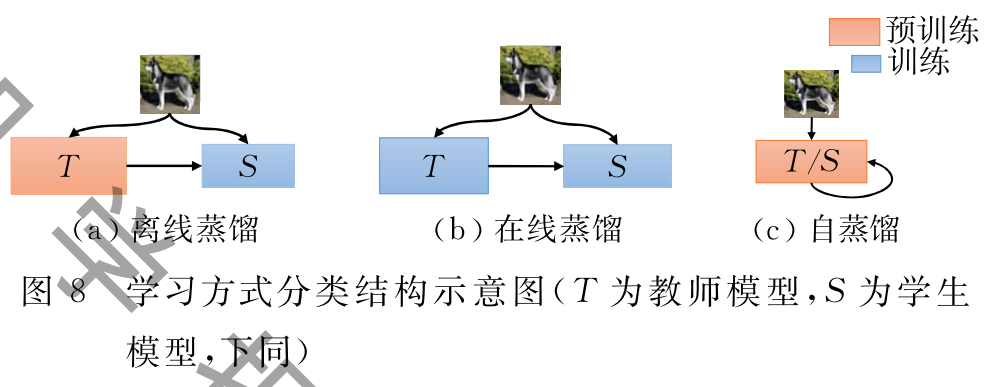
类似于人类教师和学生间的学习模式,神经网 络的知识蒸馏学习方式也有着多种模式.其中,学生 模型基于预训练好的、参数固定的教师模型进行蒸 馏学习被称为离线蒸馏.相应 地,教师和学生模型同时参与训练和参数更新的模 式则称为在线蒸馏.如果学生 模型不依赖于外在模型而是利用自身信息进行蒸馏 学习,则被称为自蒸馏学习,如图7 所示.一般而言,蒸馏框架都是由一个教师模型和一 个学生模型组成,而有多个模型参与的蒸馏称为多模型蒸馏;目前,大部分 蒸馏框架都是默认源训练数据集可用的,但最近的 很多研究在不使用任何已知数据集的情况下实现 蒸馏,这类统称为零样本蒸馏(又称为无数据蒸馏,).特别地,出于一些 隐私保护等目的,教师模型可以享有一些特权信息而 学生模型无法访问,在这种约束下,形成特权蒸馏 学习.接下来,将分别介绍不同蒸馏学习方式的代表性工作.
主要应用
**计算机视觉 **
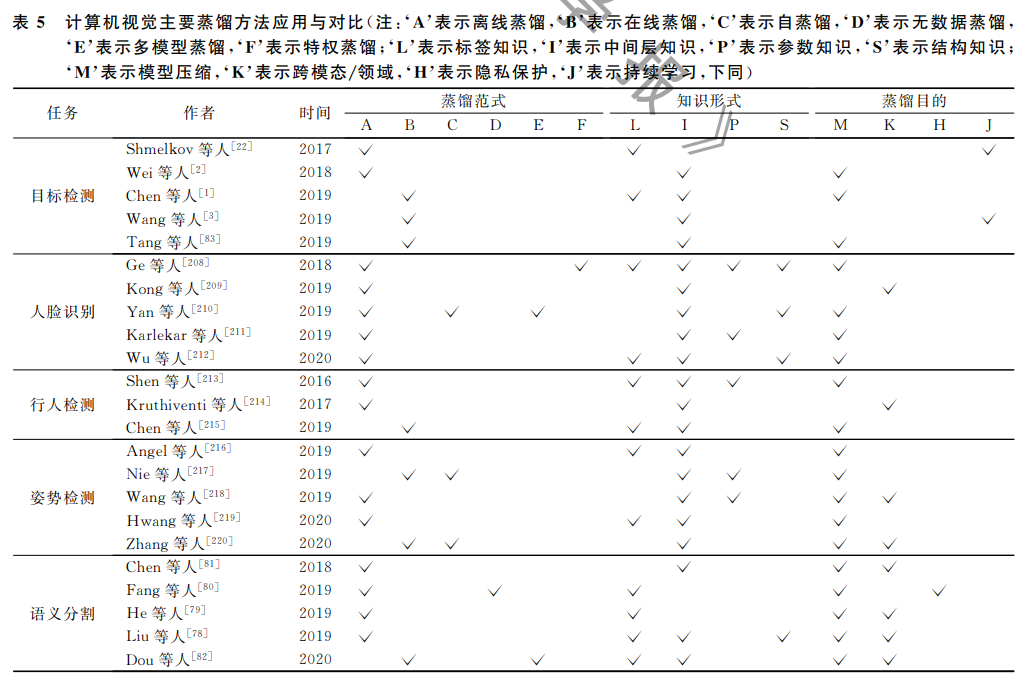
计算机视觉一直是人工智能的研究热点领域之 一.近年来,知识蒸馏被广泛应用于各种视觉任务达 到模型压缩、迁移学习和隐私保护等目标.虽然知识 蒸馏的应用十分广泛,但是由于各个研究方向的热 度不同,所以相关研究的论文数量也会有很大的差异.本文重点引用了知识蒸馏在视觉上的热点方向, 并列举相关论文的方法供读者查阅学习,而对于其 他一些方向可能存在取舍.目前,应用知识蒸馏的视 觉研究主要集中在视觉检测和视觉分类上.视觉检 测主要有目标检测、人脸识别、行人检测、姿势检测;而视觉分类的研究热点主要是语义分割,如表5所 示.另外,视觉中还有一些其他应用比如视频分 类[105]、深度估计和光流/场景流估计[169]等等.
**自然语言处理 **
自然语言处理(NaturalLanguageProcess, NLP)的发展非常迅速,从RNN、LSTM、ELMo再 到如今非常热门的BERT,其模型结构逐渐变的非 常的深而复杂,需要耗费大量的资源和时间.这样的 模型几乎无法直接部署.因而,获得轻量级、高效、有 效的语言模型显得极为迫切.于是,知识蒸馏在 NLP领域也得到了极大的重视.目前,结合知识蒸 馏较为广泛的NLP任务主要有机器翻译(Neural MachineTranslation,NMT),问答系统(Question AnswerSystem,QAS)等领域.如表6,本节列举了 知识蒸馏结合神经机器翻译和问答系统的代表性的 研究工作.另外,BERT模型在近些年被广泛应用于 NLP的各个领域,其重要性不言而喻,因此,我们在 表6中一并列举并在下面对其作详细介绍.
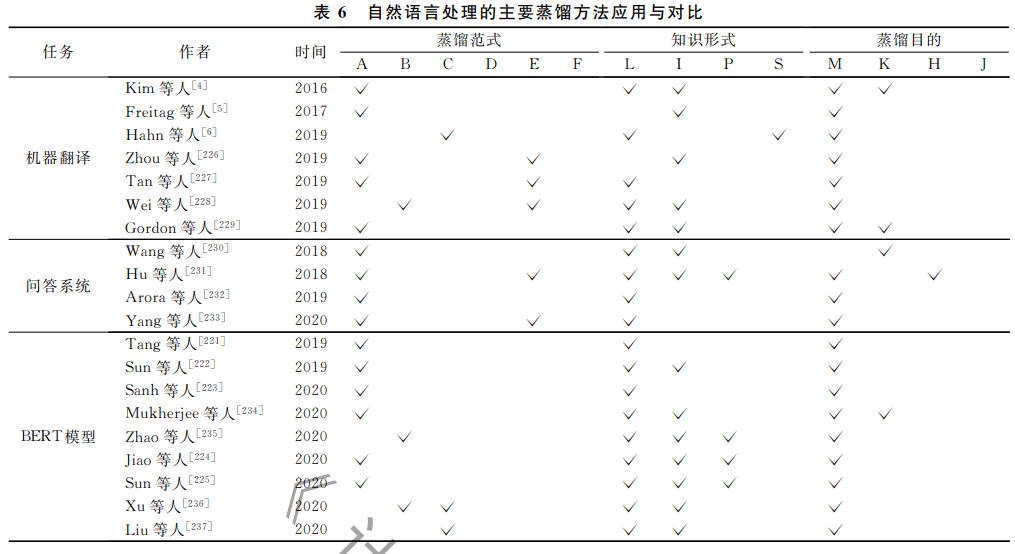
BERT模型是近年来自然语言中,应用最广泛的 工具之一,它是由双向编码器表示的Transformer模 型组成.由于其强大的编码表示能力,目前在自然语 言的各个任务中被广泛应用.但是,BERT模型结构 非常复杂,参数量巨大,很难直接应用于模型的训 练.目前的应用主要采用的预训练加微调的方法,因 此,对BERT模型的压缩显得尤为必要.目前,这方 面的研究已经吸引的很多研究者的关注.提出的方法 主要有剪枝、量化、蒸馏、参数共享、权重分解.但是, 量化对模型的提升效果有限,权重分解和参数共 享等工作相对较少.因此,主要工作集中在剪枝和 蒸馏.此处将主要介绍表中列举的较为经典的几种 模型.首先,知识蒸馏结合BERT较早的方法是 DistilledBiLSTM[221]于2019年提出,其主要思想是 将BERTlarge蒸馏到了单层的BiLSTM中,其效果 接近EMLO,其将速度提升15倍的同时使模型的参 数量减少100倍.后来的研究方法逐渐丰富,如 BERTPKD[222]主要从教师的中间层提取丰富的知 识,避免在蒸馏最后一层拟合过快的现象.Distill BERT[223]在预训练阶段进行蒸馏,能够将模型尺寸减 小40%,同时能将速度能提升60%,并且保留教师模 型97%的语言理解能力,其效果好于BERTPKD. TinyBERT[224]提出的框架,分别在预训练和微调阶 段蒸馏教师模型,得到了速度提升9.4倍但参数量 减少7.5倍的4层BERT,其效果可以达到教师模 型的96.8%.同样,用这种方法训出的6层模型的 性能超过了BERTPKD和DistillBERT,甚至接近BERTbase的性能.上述介绍的几种模型都利用了 层次剪枝结合蒸馏的操作.MobileBERT[225]则主要 通过削减每层的维度,在保留24层的情况下,可以 减少4.3倍的参数同时提升4倍速度.在GLUE上 也只比BERTbase低了0.6个点,效果好于Tiny BERT和DistillBERT.此外,MobileBERT与Tiny BERT还有一点不同,就是在预训练阶段蒸馏之后, 直接在推测缺乏MobileBERT有一点不同,就是在 预训练阶段蒸馏之后,直接在MobileBERT上用任 务数据微调,而不需要再进行微调阶段的蒸馏,更加 便捷.
综上,BERT压缩在近些年的发展还是较为显 著的.这些方法对后BERT时代出现的大型预训练 模型的如GPT系列等单向或双向Transformer模 型的压缩具有很大借鉴意义.
推荐系统
近些年,推荐系统(RecommenderSystems,RS) 被广泛应用于电商、短视频、音乐等系统中,对各个 行业的发展起到了很大的促进作用.推荐系统通 过分析用户的行为,从而得出用户的偏好,为用户 推荐个性化的服务.因此,推荐系统在相关行业中 具有很高的商业价值.深度学习应用于推荐系统 同样面临着模型复杂度和效率的问题.但是,目前 关于推荐系统和知识蒸馏的工作还相对较少.本文 在表7中整理了目前收集到的相关文献,可供研究 人员参考.

总结
近年来,知识蒸馏逐渐成为研究热点而目前绝 大多数优秀的论文都是以英文形式存在,关于系统 性介绍知识蒸馏的中文文献相对缺失;并且知识蒸 馏发展过程中融入了多个人工智能领域,相关文献 纷繁复杂,不易于研究人员对该领域的快速、全面地 了解.鉴于此,本文对知识蒸馏的相关文献进行了分 类整理和对比,并以中文形式对知识蒸馏领域的研 究进展进行了广泛而全面的介绍.首先介绍了知识 蒸馏的背景和整体框架.然后分别按照知识传递的 形式、学习方式、学习目的、交叉领域的结合对知识 蒸馏的相关工作进行了分类介绍和对比,分析了各 类方法的优缺点和面临的挑战,并对研究趋势提出 了见解.本文还从计算机视觉、自然语言处理和推荐 系统等方面概述了知识蒸馏在不同任务和场景的具 体应用,对知识蒸馏原理和可解释性的研究进行了 探讨.最后,从4个主要方面阐述了对知识蒸馏未来 发展趋势的分析. 知识蒸馏通过教师学生的结构为深度神经网 络提供了一种新的学习范式,实现了信息在异构或 同构的不同模型之间的传递.不仅能够帮助压缩模 型和提升性能,还可以联结跨域、跨模态的知识,同 时避免隐私数据的直接访问,在深度学习背景下的 多种人工智能研究领域具有广泛的应用价值和研究 意义.目前,有关知识蒸馏的中文综述性文章还比较 缺失.希望本文对知识蒸馏未来的研究提供有力的 借鉴和参考.



