论文浅尝 | When a Knowledge Base Is Not Enough

Citation: Savenkov,D., & Agichtein, E. (2016). When a Knowledge Base Is Not Enough: QuestionAnswering over Knowledge Bases with External Text Data. International ACM SIGIRConference on Research and Development in Information Retrieval (pp.235-244).ACM.
论文下载地址:http://140.122.184.128/presentation/16-11-08/When%20a%20Knowledge%20Base%20Is%20Not%20Enough-Question%20Answering%20over%20Knowledge%20Bases%20with%20External%20Text%20Data.pdf
项目相关地址:http://ir.mathcs.emory.edu/projects/text2kb/
动机
对于基于知识图谱的事实性问答(KBQA),每一个问题,都可以被转换为某个三元组事实,该事实由主语、谓语、宾语组成。对于传统的KBQA问题,这三个子任务都局限于知识图谱的范围内,即利用各种知识图谱上的技术来提高识别精度、映射准确率。但由于问题的文本很短,往往只有十几个字,甚至几个字,这样就为实体消歧、谓词消歧带来困难;同时,对于候选答案的排序来说,如果单单只考虑答案的类型与问句意图是否匹配、或者答案文本与问题文本是否相似,由于问题文本短、提供的信息相对有限,利用这些信息去进行答案排序,往往并不是很准确。
因此,为了解决这个问题,本文提出的方法,以目前KBQA效果最好的系统为基础,分别在实体链接、谓词映射和候选答案排序这三个子任务中,加入了外部文本,以提高效果。外部文本包括wiki文本、搜索引擎返回的文档、社区问答样本(CQA)和爬虫抓取的网页语料。利用这些外部语料,可以找到更多的候选实体、利用CQA的答案上下文更加精确地筛选谓词、利用问答对的上下文语料设计更加精确的方法来对候选答案打分,从而有力地提高了KBQA的精度。经过实验证明,增加了外部文本的系统,比传统KBQA系统或基于纯文档检索的QA系统,对于事实性问答任务的效果更好。
贡献
文章的贡献有:
(1)设计了利用外部文本进行实体链接、谓词映射、候选答案打分的KBQA模型;
(2)对于实体链接、谓词映射、候选答案打分这三个任务,结合外部文本,分别提出了改进算法,以提高这三个任务的效果;
(3)加入外部文本的KBQA系统,取得了state-of-art的实验效果;
方法
⒈本文首先介绍了baseline的KBQA系统Aqqu,再介绍如何利用外部文本,对这个系统加以改进。Aqqu系统,是一个基于KBQA的问答系统,其工作模块被分为典型的三块:实体识别/链接、谓词映射、候选答案评分。
对于实体链接,Aqqu对于某种特定词性下的所有宽度的mention,都视为entity mention,并且使用实体名词典将短语映射为实体;Aqqu保留所有的候选实体指称,并且附上实体的参数作为参考(比如该实体指称在训练集中出现的次数、或者p(entity|mentiontext)的得分)。
对于谓词映射,Aqqu通过检索候选实体附近的邻居节点,并且使用人工事先编写的模板,来建立候选查询,每个查询都有问题实体、谓词和答案占位符。WebQuestions中的大部分答案都在候选实体的两跳范围之内,并且相关的查询语句基本上由三种模板来表达。
对于候选答案评分,Aqqu对于每一对候选答案,都生成三组特征:第一个候选答案的特征,第二个候选答案的特征,以及这两个特征的差别;然后利用随机森林模型来做分类,第一个候选答案的特征优于第二个,则记为正类,否则为负类;为了减少ranking的数量,Aqqu使用了一个简化筛选模型,将明显不正确的答案筛去。
⒉引入外部文本,将Aqqu系统扩展为Text2KB系统。
对于实体链接,Text2KB将整个问题作为一个query,利用Bing WebSearch API搜索相关网页,或使用Lucene在wikipedia的页面搜索相关文档,并抽取出top-10的文档以及摘录(snippet)。当使用搜索引擎来找相关网页时,找到top-10的摘录后,统计摘录中与问题文本足够近似的实体指称出现的频数,频数越高,说明这个实体指称更有可能是问题的一个主题实体。只有实体指称与问题文本(非停用词)的Jaro-Winkler编辑距离小于等于0.2的实体指称,才能加入主题实体列表,如下式1.1所示。
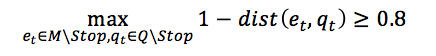
对于谓词映射,Text2KB使用弱标记的问答对来计算问题术语和谓词之间的相关度,来扩展谓词的同义词集合。Text2KB使用了Yahoo! WebScope L6数据集中的440W个问答对来做训练。首先根据问题实体和答案实体,从知识图谱中得到连接这两个实体的谓词,以这种远程监督的方法来标记出每一个问答对和谓词的映射关系。由此,对每一个问答对,可以得到问题术语-谓词的关系。对于整个440W个问答对进行全局统计后,可以利用PMI算法计算出每一个问题实体-谓词的PMI数值。
在Text2KB中,将候选谓词与问题术语的PMI值都计算出来,并取最小PMI、平均PMI、最大PMI值,为候选答案的ranking特征,且以此作为谓词映射的参考。
对于候选答案评分,Text2KB利用知识图谱中所有与候选答案实体有关的信息,以及外部文本信息,来提高候选答案打分的准确性。
对于候选答案评分,关键是考察候选答案与问句是否类型匹配。在文本中,与问题相关的段落里,会找到许多相关的实体,而这些实体的上下文就是用文本来表达实体之间的关系,这些关系不一定需要与KB中的关系重合,它们可以表达任意两个实体之间的关系,由此可以拓展KB。为此,Text2KB使用clueweb12为文本语料,freebase为实体语料,用来识别出文档对应于问句中的实体指称,并统计出文档中一对实体指称的上下文中,terms出现的次数。统计时,除了统计问句中分割问题实体的terms之外,对于实体指称的上下文窗口内(如100个字符之内)的terms,也一起统计。如下图1所示,对于这样一篇文档,可以知道实体指称“Rielle Hunter”与实体指称“John Edwards”的上下文之间,出现了term“sorry、affair、memoir”等,这些词语组合起来,就一定程度上表示了Rielle和John这两个实体之间的关系。
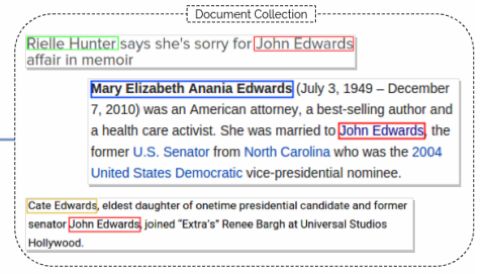
图1 检索到的相关文档示例
如下图2所示为一些实体之间的关系,关系用高频词来表示。
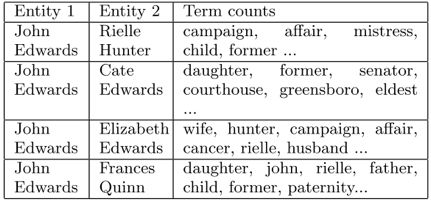
图2 文档中一对实体周围出现的高频词语示例
利用上述的统计,可以由此计算候选答案的评分,公式如下(1.3)所示:
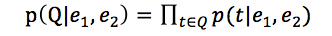
上式表示,若问题中有实体,候选答案有实体,根据上文统计出来的实体指称-terms的统计频数,对每一个候选答案(可能包含几个答案实体),计算问题中term的出现频率之积,并取所有问题实体-答案实体的最小值、平均值、最大值为候选答案的ranking特征。
同之前的谓词匹配一样,首先根据term的频次(可以根据总频次做归一化),对term的词向量进行加权和,得到entity1-entity2的对应词向量表示;再将entity1-entity2的对应词向量与问句所有的非实体指称tokens进行余弦计算,得到最小值、平均值、最大值为候选答案的ranking特征。
实验
从图3所示的表格可以见到,Text2KB的方法,比KBQA系统、以及纯文本检索系统(OpenQA、YodaQA),都有明显的提升。
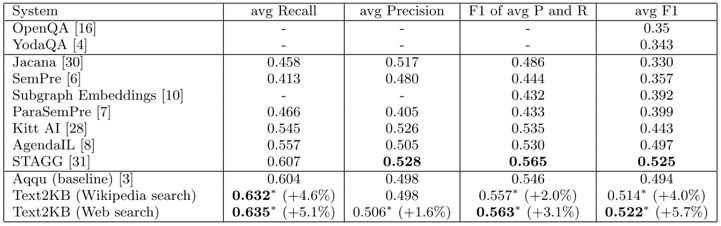
另外,从下图4可见,Text2KB的各个模块,都会对问答效果有提升。

图4 Text2KB各模块的作用
图4中,T表示使用各种特征来做候选答案评分;T表示加入了考虑时间范围的模板;wiki表示使用维基百科文档为文本来源,web表示使用搜索引擎检索的网页为文本来源;wikient表示使用维基百科摘录来做实体链接,webent表示使用搜索引擎检索的摘录来做实体链接;CQA是基于社区问答,利用远程监督的方法计算PMI值,对谓词映射做提升;CL是统计文档中一对实体上下文中的词频,来考察候选答案与问句是否类型匹配。从表中可见,当把所有的模块都加上,此时效果最佳;另外,文本来源于网页的QA效果,要由于文本来源于维基百科的,这是由于维基百科本来就是网页搜索的一个子集,所以很自然地,效果比网页检索要差。
总结
这篇文章,主要有三个主要工作:利用外部文本来进行问题意图识别和候选答案打分、利用社区问答(CQA)来做谓词映射、利用一对实体周边上下文的文本片段来做候选答案打分。这些工作组合起来,会对KBQA系统有很大的提升。此外,这些工作都可以利用文本来进行工程化地实现,并不涉及复杂的神经网络模型,在应用或项目中,容易实现。
论文笔记整理:花云程,东南大学博士,研究方向为自然语言处理、深度学习、问答系统。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。



