牛津大学提出全新生成式模型「SQAIR」,用于移动目标的视频理解

作者:Adam R. Kosiorek、Hyunjik Kim、Ingmar Posner、Yee Whye Teh
来源:arxiv、雷克世界
导语:可以这样说,对移动目标的视频分析和理解是很复杂的,最近,牛津大学(University of Oxford)的科学家们提出了一种全新的具有可解释性的深度生成式模型——SQAIR,它是一种通过为每一个目标进行参与、推理、重复等操作进行视频理解和目标检测的模型。它能够在整个帧序列中可靠地发现和追踪目标,且能够基于当前帧生成未来的帧。
在本文中,我们提出了序列参与、推理、重复(Sequential Attend, Infer, Repeat,SQAIR),这是一种用于可移动目标视频的具有可解释性的深度生成式模型。它可以在整个帧序列中可靠地发现和追踪目标,还能够基于当前帧生成未来的帧,从而模拟目标的预期运动。这是通过在模型的潜在变量中显示地对目标的存在、位置和外观进行编码实现的。SQAIR保留了其前任的所有优点,参与、推理、重复(AIR,Eslami等人于2016年提出),包括以无监督的方式进行学习,并解决其缺点。我们使用移动的多MNIST数据集来显示AIR在检测重叠或部分遮挡目标时所存在的局限性,并展示SQAIR是如何通过利用目标的时间一致性来克服这些缺点的。最后,我们还将SQAIR应用于现实世界的行人闭路电视(Closed-Circuit Television,CCTV)数据,在那里,它学习以一种无监督的方式可靠地检测、追踪和生成步行的行人。
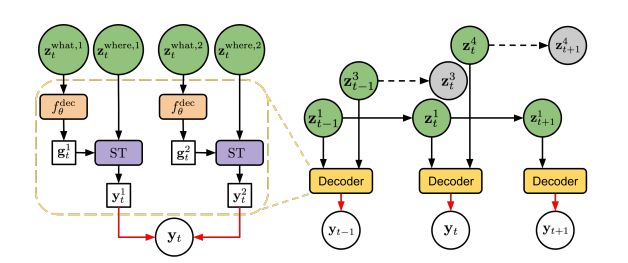
图1:左:在AIR中的生成;右:在SQAIR中的生成。
可以这样说,在他们的环境中识别目标并理解他们之间关系的能力是人类智力的基石(Kemp和Tenenbaum于2008年提出)。可以说,在这样做的过程中,我们依赖于空间和时间一致性的概念,这个概念引发了一个期望,即目标不会凭空出现,也不会自发地消失,并且它们可以通过诸如位置、外观以及一些解释它们随着时间的演变的动态行为进行描述。我们认为这种一致性的概念可以被看作是一种归纳偏差(inductive biases),可以提高我们学习的效率。同样,我们认为将这种对时空一致性的偏差引入到我们的模型中应该会大大减少学习所需的监督量。
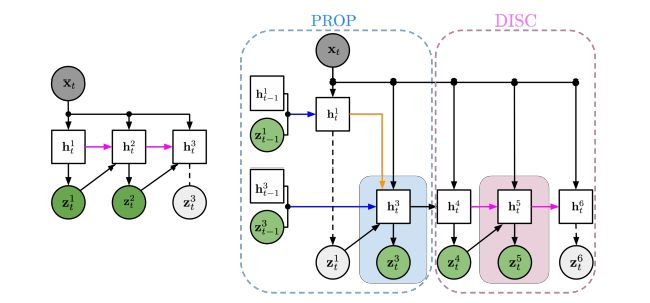
图2:左:AIR中的推理;右:SQAIR中从传播(PROP)阶段开始的推理。
实现这种归纳偏差的一种方式是通过模型结构。尽管最近在深度学习方面所取得的成功表明,即使没有明确地为模型赋予那种具有可解释性的结构,这种进步也是可以取得的(LeCun和Bengio等人于2015年提出),但最近的研究表明,将这种结构引入深度模型确实可以导致有利的归纳偏差从而提高性能表现,如卷积神经网络(LeCun和Boser等人于1989年提出),或那些需要关系推理的任务(Santoro等人于2017年提出)。除此之外,结构还可以通过显著提高泛化能力、数据效率(Jacobsen等人于2016年提出),或将其能力扩展到非结构化输入(Graves等人于2016年提出),从而使神经网络能够在新的环境中有用。
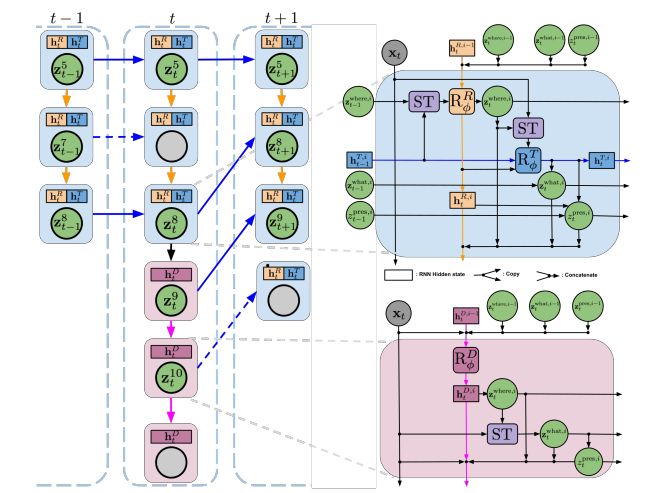
图3:左:SQAIR中PROP和DISC之间的交互;右:单一传播块(顶部)和发现块(底部)中的信息流。
由Eslami等人于2016年所引进的参与、推理、重复(AIR)是这种结构化概率模型(structured probabilistic model)的一个显著示例,它依赖于深度学习并承认有效的摊销推理(amortized inference)。在没有任何监督的情况下进行训练,AIR能够将一个可视化的场景分解为其构成组件,并生成大量(已学习)的潜变量,而这些变量能够明确地对每个目标的位置和外观进行编码。虽然这种方法令人鼓舞,但它对单一(以及固有的静态)场景建模的聚焦导致出现了许多局限性。例如,它通常将两个靠的很近的目标合并为一个目标,因为没有时间上下文可用于对它们进行区分。

图4:输入图像(顶部)和带有明显闪光位置的SQAIR重构(底部)。
同样,我们研究证明,AIR也很难识别部分遮挡的目标,例如当它们超出场景框架的边界时(参见图5)。

图5:输入,具有明显闪光位置的重构以及闪光重构AIR(左)和SQAIR(右)。SQAIR可以通过聚合时间信息来对部分可视化和重叠的目标进行建模。
在此研究中,我们的贡献是通过引入一个序列版本来减轻AIR的缺点,即对帧序列进行建模,使其能够随着时间的推移发现和追踪目标,并在未来产生令人信服的帧外推(extrapolations of frames)。我们通过利用时间信息来学习一个更丰富、更有能力的生成式模型来实现这一目标。具体而言,我们将AIR扩展到时空状态空间模型(spatio-temporal state-space model)中,并在动态目标的未标记的图像序列上对其进行训练。我们将对结果模型进行展示,并且我们将其命名为序列 AIR(Sequential Attend,Infer,Repeat,SQAIR),它在综合和现实世界的场景中性能表现优于原始AIR的同时,还保留了原始AIR构想的优势。
总而言之,在本文中,我们将AIR扩展到图像序列,从而实现时间一致的重建和样本。我们指定了一个概率模型和一个相应的实现,它们可以利用由AIR引入的结构。在这样做的过程中,我们提高了解决重叠目标问题的能力。
就我们所知,这是第一个使用可学习似然的方法呈现无监督目标检测和追踪的研究,它借助于目标的生成式建模方法,特别是通过时间对其外观和位置进行明确建模。作为一个生成式模型,它可以用于条件式生成,其中,它可以将序列推断到未来。因此,在一个强化学习环境中,将它与Weber等人(于2017年提出)的想象力增强智能体(Imagination-Augmented Agents)一起使用,或更为普遍地作为一种世界模型(Ha和Schmidhuber于2018年提出),尤其是对于那些具有简单背景的环境,例如,像《蒙特祖玛的复仇》(Montezuma’s Revenge)或《吃豆人》(Pacman)这样的游戏。
该框架为进行进一步的研究提供了各种途径。SQAIR能够导致具有可解释性的表征,但是通过使用可解决目标中变化因素的可替代性目标,就可以进一步提高变量的可解释性(Kim和Mnih于2018年提出)。此外,在目前的状态下,SQAIR的运行只能使用简单的背景和静态摄像头。而在未来的研究中,我们将会想办法解决这个缺点,并加快序列推理过程,其复杂性与目标数量呈线性关系。生成式模型——目前假设为附加的图像合成,性能可以进一步得以改进,例如,自回归建模(autoregressive modelling,Oord等人于2016年提出)。它可以导致模型具有更高的保真度,且也改善被遮挡目标的处理。最后,SQAIR模型是非常复杂的,而且执行一系列消融研究以更密切地研究不同组分的重要性将是非常有用的。
原文链接:https://arxiv.org/pdf/1806.01794.pdf
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习



