黄金时代
今年的图灵奖得主John L. Hennessy和David A. Patterson即将在ISCA2018上做个讲演,题目是“A New Golden Age for Computer Architecture: Domain-Specific Hardware / Software Co-Design, Enhanced Security, Open Instruction Sets, and Agile Chip Development”[1]。而在IEEE Micro上,Google Brain的Jeff Dean, David Patterson和Cliff Young发表的文章“A New Golden Age in Computer Architecture: Empowering the Machine- Learning Revolution”[2],从另一个视角提出了计算机体系结构的”黄金时代“。不同的角度,反映了不同的思考。
•••
如果你还不太清楚Computer Architecture的定义,以下贴出Wikipedia的解释供参考:
In computer engineering, computer architecture is a set of rules and methods that describe the functionality, organization, and implementation of computer systems. Some definitions of architecture define it as describing the capabilities and programming model of a computer but not a particular implementation(更偏向抽象概念). In other definitions computer architecture involves instruction set architecture design, microarchitecture design, logic design, and implementation(硬件架构).
本文讨论的内容主要是硬件架构设计。
•••
我们先来看看软件大神Jeff Dean作为第一作者,体系结构大神Patterson作为第二作者的文章[2]。他们的出发点是,在Machine Learning爆发的背景下的计算机体系结构。摘要如下:
“The end of Moore’s law and Dennard scaling has led to the end of rapid improvement in general-purpose program performance. Machine learning (ML), and in particular deep learning, is an attractive alternative for architects to explore. It has recently revolutionized vision, speech, language understanding, and many other fields, and it promises to help with the grand challenges facing our society. The computation at its core is low-precision linear algebra. Thus, ML is both broad enough to apply to many domains and narrow enoughto benefit from domain-specific architectures, such as Google’s Tensor Processing Unit (TPU). Moreover, the growth in demand for ML computing exceeds Moore’s law at its peak, just as it is fading. Hence, ML experts and computer architects must work together to design the computing systems required to deliver on the potential of ML. This article offers motivation, suggestions, and warnings to computer architects on how to best contribute to the ML revolution.”
Motivation我们就不具体看了,相信大家都了解的很多。我们直接看这篇文章的干货:suggesttions和warnings吧。
这篇文章的核心部分是“ADVICE FOR HARDWARE ENGINEERS”,提出了六个很具体且值得思考的问题。在看具体问题之前,文章先讨论了一下,ML算法快速演进和硬件(芯片)开发周期长的矛盾。
“Hardware designs must remain relevant over at least two years of design time plus a three-year deployment window (assuming standard depreciation schedules). As designers, we need to pick a good system-level balance point between specialization for the currently popular techniques and flexibility to handle changes in the field over the lifetime of a design. Designing appropriate hardware for a five-year window in a field that is changing as rapidly as ML is quite challenging. Compilation techniques, possibly themselves enhanced by ML, will be central to meeting this challenge. It would be ideal if users could express their ML problems in the most natural way, but then rely on compilation to give interactive response times for researchers and scalability for production users.”
希望硬件支持更多的算法,实现更长的生命周期,就需要更高的灵活性,而灵活性都是以牺牲效率为代价的,找到平衡点非常重要,也相当困难。这里强调了编译技术。个人感觉,编译器做的好,可以解决一部分问题,但并不能完全解决“寻找架构平衡点”的难题。
下面我们就一起来看看文章中提出的具体的问题(“six issues that impact ML hardware design, roughly sorted on a spectrum from purely architectural to mostly ML-driven concerns.”)
1. Training
这里主要强调Training的挑战,运算量是inference的三倍以上;同时,由于要把所有的activation值存下来,供反向传播算法使用,需要的存储就更惊人了。总之,相比inference,training要解决的问题的规模要大的多。(对于training的挑战,大家也可以看看老师木最近的讲座:视频 | 一流科技创始人袁进辉:深度学习引擎的最优架构)。本文也给Google先做inference做了辩护
2. Batch Size
Batch size的大小直接影响数据重用和并行处理,实际上对硬件架构的运行效率影响是很大的。目前使用的GPU和TPU在batch size大于32的时候是比较有效的,但对于小的batch size(甚至是1),是否可能有更有效的架构来支持?这里提出的主要问题是目前对Batch size的研究是比较少的,而目前的研究结果也看不出很清晰的结论。不过Graphcore好像最近发表过small batch size这个话题的研究,感兴趣的同学可以去看看。
3. Sparsity and Embeddings
ML中的稀疏性讨论已经有很多了,针对细粒度的稀疏性的硬件架构优化也有很多研究。本文提到的一个“更有潜力”的话题是粗细粒度稀疏性(coarse-grain sparsity),一个采样点只影响一个大型模型的一部分的情况。“However, we think that coarse-grain sparsity, where an example touches only a fraction of the parameters of huge model, has even more potential; Mixture of Experts (MoE) models25 consult a learned subset of a panel of experts as part of their network structure. Thus, MoE models train more weights using fewer flops for higher accuracy than previous approaches.”和这种粗粒度的稀疏性模型类似的问题是目前在文字和语言处理里使用很多的Embedding。对Embedding表的访问是通常在一个很大的数据结构中随机访问比较小的数据(“hundreds of 100- to 1,000-byte reads in multi-hundred-gigabyte data structures per training or inference example”)。这种对参数的访问方式和一般的神经网络是有很大差别。记得Jeff Dean在好几次演讲中都提到如下的趋势。这也是对硬件架构设计提出的一个好问题。

source: Hot Chip 2017
4. Quantization and Distillation
这个话题是希望通过量化和Distillation技术来提高训练的效率。量化(低精度)在inference中用的已经很多了,但在training里似乎进展不大。Distillation是使用一个大的模型来优化小模型的训练,得到比直接训练小模型更好的效果。但目前其作用的原理还不是很清楚,也带来如下问题:“Could better training methods allow us to directly train the smaller models (and perhaps all models) to higher accuracy? Is there something fundamental about the more degrees of freedom in the larger model that enables better training?”这个话题主要是算法和训练方法的问题,而非硬件架构设计的问题。但从另一个角度来看,如果能用较低的量化精度进行训练,或者研究出更有效的训练方法,就可能大大简化硬件架构设计的难度。
5. Networks with Soft Memory
这个话题我在之前的文章“AI会给芯片设计带来什么?”中就探讨过,其核心是在一些神经网络中(Neural Turing Machines,memory networks,attention),访问存储器的方式会和现在有很大差别。和所谓“硬”存储器(目前的存储方式)不同,访问“软”存储器实际需要把表(存储)中所有条目的加权平均。“Such soft mechanisms are expensive compared to traditional “hard” memories, because the soft memory computes a weighted average over all entries of a table. A hard memory simply loads a single entry from a table. We haven’t seen research into efficient or sparse implementations of these soft memory models.”个人感觉应该会出现专门为这种访存行为设计的存储器或者DMA控制器。
6. Learning to Learn (L2L)
这个当然是目前最大的脑洞了,神经网络自己设计神经网络,甚至在设计机器学习模型的同时顺便设计新的硬件架构(“For those doing hardware-software co-design, L2L gives the further possibility to construct better systems by simultaneously, automatically searching for new ML model architectures and new computer architectures.”)。如果真能这样,可能离人工智能的奇点就不远了。“L2L offers the possibility that we might use far more computing resources but require considerably less human ML expertise in designing ML solutions, which seems like a utilitarian optimization of marginal returns on capital and labor. ”这也符合Jeff Dean最近常说的Meta-learn everything。
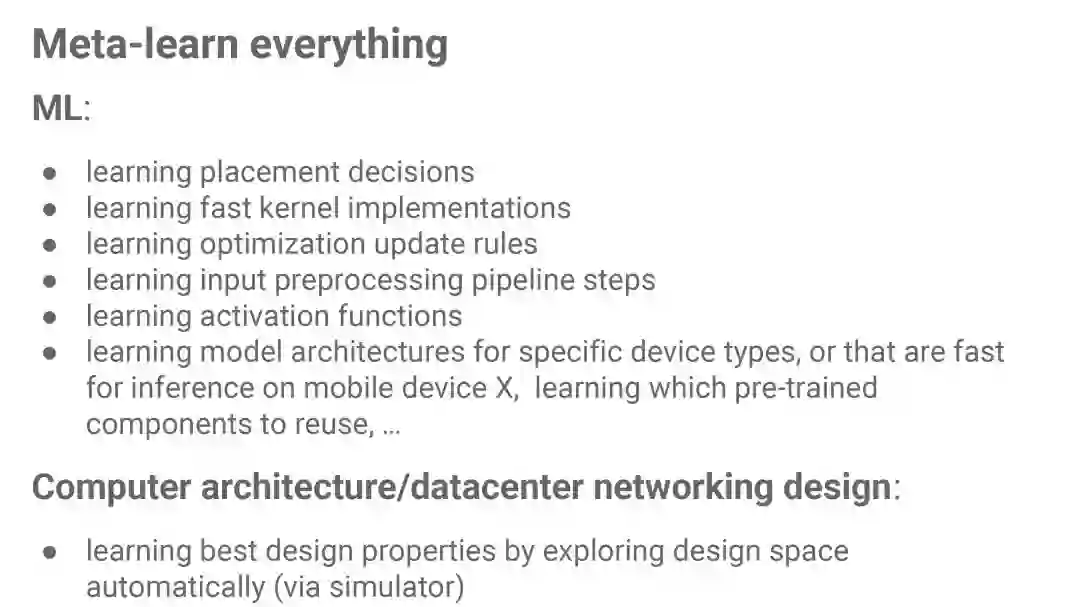
source: ScaledML 2018
除了上述一些问题(潜在研究点)外,文章还以“ML HARDWARE FALLACIES AND PITFALLS”的方式给大家提出了一些“忠告”。
Fallacy: Given the large size of the ML problems, the hardware focus should be operations per second (throughput) rather than time to solution (latency).
Fallacy: Given a sufficiently large speedup, ML researchers would be willing to sacrifice a little accuracy.
Pitfall: Designing hardware using last year’s models.
Pitfall: Designing ML hardware assuming the ML software is untouchable.
这几点我就不细说了,大家看看原文吧,还是非常清楚的。
Jeff Dean看到的“黄金时代”是围绕机器学习而来的。我们看到,ML和计算机体系结构两个问题碰撞产生了几乎“无限”的可能性(本文还没怎么讲利用ML解决体系结构的话题)。作为这个领域的工作者,这可能是我们现在感觉最为幸福的一点。

•••
两位新晋图灵奖得主将在ISCA上讲的内容目前只有个提要。和上面介绍的文章相比,他们探讨的问题就计算机体系结构而言更为基础,范围也更广。首先用一段话简单介绍了一下计算机体系结构的历史:“In the 1980s, Mead and Conway democratized chip design and high-level language programming surpassed assembly language programming, which made instruction set advances viable. Innovations like RISC, superscalar, multilevel caches, and speculation plus compiler advances (especially in register allocation) ushered in a Golden Age of computer architecture, when performance increased annually by 60%. In the later 1990s and 2000s, architectural innovation decreased, so performance came primarily from higher clock rates and larger caches. The ending of Dennard Scaling and Moore’s Law also slowed this path; single core performance improved only 3% last year! In addition to poor performance gains of modern microprocessors, Spectre recently demonstrated timing attacks that leak information at high rates.”。
简单来说就是,上世纪80年代开始了一个体系结构的黄金时代,各种架构上的创新集中涌现;90年代末开始,半导体工艺突飞猛进,不需要太多架构上的创新,计算机系统的性能也可以大幅增长;而目前工艺的进展明显放缓(Dennard Scaling and Moore’s Law),基于工艺改进的性能提升已经非常有限;Spectre漏洞对体系结构的安全性又提出了挑战。在这个大背景下,二位体系结构大神认为我们即将迎来另一次体系结构黄金时代。而这个新时代主要包括了如下几个重点内容:
1. Hardware/Software Co-Design for High-Level and Domain-Specific Languages
这个话题不算新鲜,当通用架构很难改进的时候,面向特定领域的架构肯定是必然的选择(可以参考我关于专用处理器的系列文章:“当我们设计一个专用处理器的时候我们在干什么?(上)”和“自己动手设计专用处理器!”)。特定领域计算是一个很大的概念,从专用的领域语言(Domain-Specific Language)到软硬件架构和实现和验证。Google的TPU和Pixel Visual Core是很好的例子,它们都针对特定领域,有相应的领域语言:Tensorflow和Halide,有专门的硬件架构和工具(在[3]中有详细的分析)。
2. Enhancing Security
这个话题主要是来自Meltdown和Spectre。这两个漏洞和之前的很多安全性挑战的很大区别在于,它们利用了CPU架构设计本身使用的重要技术。对于这个问题的分析已经很多,实际上,要求最初的架构设计者能够想到这项技术会被这样利用是不公平的。“The very definition of computer architecture ignores timing, yet Spectre shows that attacks that can determine timing of operations can leak supposedly protected data.”但这样的漏洞确实会对未来的体系结构设计提出更高的要求。
3. Free and Open Architectures and Open-Source Implementations
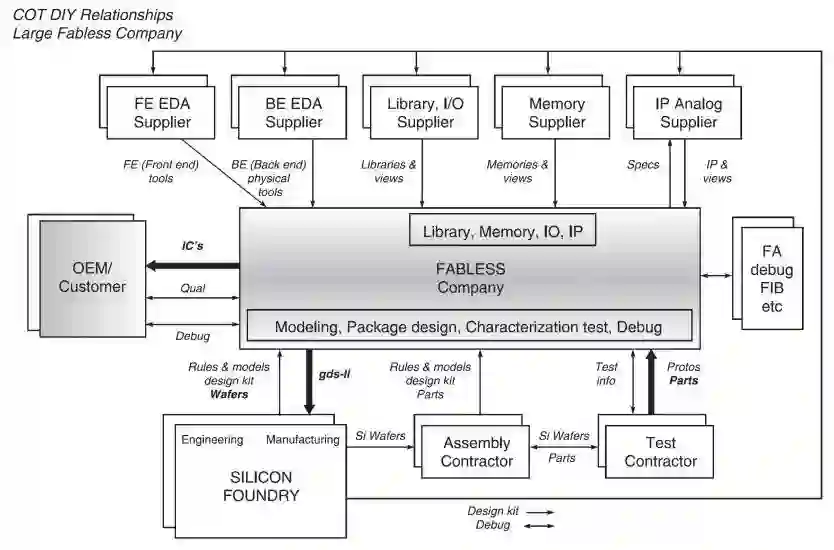
这个话题主要是在讲硬件开源的问题,特别是开源指令集,比如RISC-V的重要作用(毕竟是大神大力支持的项目)。目前开源硬件的呼声很高,大家对RISC-V也很期待。对此我在之前的两篇文章中都有涉及(“从Nvidia开源深度学习加速器说起”,“通过DARPA项目看看芯片世界的“远方”- 自动化工具和开源硬件”)。总的来说,芯片设计需要复杂的生态(下图是一个Fabless芯片设计厂商设计芯片需要的生态,来自[4]),不能高估在一个点上的硬件开源能够起到的作用。
4. Agile Chip Development
这一个又是大话题,把软件开发中的“敏捷开发”概念引入的芯片设计,不仅仅是体系结构问题,还是个方法学的问题。如果我们追根溯源,可以看到Patterson在2015年就在EE Times上发表过系列文章“Agile Design for Hardware”[5]。当时在这个话题的讨论中,除了对芯片投片成本的分析,他讨论的主要方案还是RISC-V/Chisel这些内容。在我看来,这里存在的问题和1,3两个话题类似,方向是有潜力的,但解决方案似乎还有待更多的探索和创新。
总得来说,以上4点中除了第2点之外,都是Patterson多年宣传的内容,这次的Lecture可能不会有太多新意。当然,这几个领域确实是计算机体系结构中非常值得研究的方向,所以还是很期待他们在ISCA上的演讲。
参考:
1. John L. Hennessy and David A. Patterson, "A New Golden Age for Computer Architecture: Domain-Specific Hardware/Software Co-Design, Enhanced Security, Open Instruction Sets, and Agile Chip Development" , ISCA2018 lecture, http://iscaconf.org/isca2018/turing_lecture.html
2. Jeff Dean, David Patterson, and Cliff Young, "A New Golden Age in Computer Architecture: Empowering the Machine- Learning Revolution", IEEE Micro Volume: 38, Issue: 2, Mar./Apr. 2018
3. John L. Hennessy, and David A. Patterson. "Domain Specific Architectures," in Computer architecture: a quantitative approach, Sixth Edition, Elsevier, 2018.Rakesh Kumar, “Fabless Semiconductor Implementation”,March 26, 2008
4. Rakesh Kumar, “Fabless Semiconductor Implementation”,March 26, 2008
5. David A. Patterson, and Borivoje Nikolić. "Agile Design for Hardware, Parts I, II, III," EE Times, July 27 to August 3, 2015.
- END-
题图来自网络,版权归原作者所有
本文为个人兴趣之作,仅代表本人观点,与就职单位无关



