书单 | 系统了解智能问答和机器翻译,从这两本书开始(文末有福利)

编者按:自然语言理解是人工智能皇冠上的明珠。在大数据、深度学习和云计算推动下,自然语言理解的各个领域近来都取得了新的进展,也孕育着无穷的机会。在本期的书单中,我们将向大家推荐两本来自微软亚洲研究院自然语言计算组的全新力作:《智能问答》和《机器翻译》。这两本书分别对智能问答和机器翻译这两个具有广泛应用场景的研究领域进行了系统性的介绍。
自然语言处理是中文信息处理的重要技术,我很高兴地看到,中国的自然语言处理在最近二十年取得了长足的进步。最新的深度学习进一步推动了本领域的发展。《智能问答》和《机器翻译》两本书详细地介绍了最新的理论、方法和技术,是难得的技术参考书。
——李生
哈尔滨工业大学教授,原中国中文信息学会理事长
早在1991年,当比尔·盖茨创建微软研究院时,就提出过一个愿景:让计算机能看会听,并可理解人类的想法。从那时开始,自然语言处理和计算机视觉、语音和图像识别等一直就是重要的研发方向。这两本书体现了微软亚洲研究院在自然语言处理方面的卓越进展。
——洪小文
微软全球资深副总裁、微软亚太研发集团主席、微软亚洲研究院院长
两本书分别系统地介绍了两个领域的关键技术,深入浅出,理论与实践完美结合,对有志于进入本领域学习的人士大有帮助。懂语言者得天下!
——沈向洋
微软全球执行副总裁、微软人工智能及研究事业部负责人
微软是继IBM深度问答系统问世以来率先从事开放式智能问答系统研究的著名团队之一,而微软亚洲研究院的机器翻译团队也是该领域全球最著名的团队之一。《智能问答》和《机器翻译》两本书的作者就分别来自于这两个团队,我对他们的学术造诣深信不疑,并对他们在研究中做出的贡献充满自豪。
《智能问答》一书深入地介绍了不同类型的智能问答系统,对于其底层的深度学习理论和知识图谱、语义表示做了深入浅出的阐述。《机器翻译》一书深入地介绍了近三十年来得到阶跃式发展的统计机器翻译和神经机器翻译的理论、方法和工具。鉴于两本书的理论高度和实践深度,它不仅可以作为大学本科和研究生的教科书使用,也定将会成为相关科研工作者和企业开发人员案头常备的专业参考书。
——黄昌宁
国际著名自然语言处理专家、清华大学自然语言处理团队和微软亚洲研究院自然语言处理团队创始人

内容简介
作为搜索引擎和智能语音助手的核心功能,智能问答(Question Answering)近年来受到学术界和工业界的一致关注和深入研究,各种问答数据集和方法层出不穷。《智能问答》一书简要回顾了该研究领域的发展历史和背景知识,并在此基础上系统介绍了包括知识图谱问答、表格问答、文本问答、社区问答和问题生成在内的五个典型的问答任务。
全书共分为十个章节:第一章概述智能问答的历史沿革、任务分类和问答测评等基本问题;第二章介绍了智能问答研究中几种常用的统计学习和深度学习模型;第三章介绍了自然语言处理任务的基础——实体链接,并详细阐述了长文本实体链接的典型方法及其在智能问答系统中的应用;第四章对智能问答最重要的组成部分,自然语言中实体间的关系进行了讲解,并介绍了四种不同的关系分类方法;第五章至第八章针对四类不同的智能问答任务,分别介绍了它们不同的解答方法;除此之外,本书的第九章还介绍了问题生成任务,解释其如何从数据和模型训练两个角度进一步提升智能问答系统的性能;最后,第十章对全书内容加以总结。
精彩章节节选
3.2.2 基于无监督学习的方法
为了减少实体链接系统对标注数据的需求,可以将无监督学习方法用于候选实体排序任务。常用的方法包括基于向量空间模型的方法和基于信息检索的方法。
基于向量空间模型的方法首先将实体提及m和m对应的某个候选实体e_i分别转化为向量表示。然后,通过计算这两个向量表示之间的距离对不同候选实体进行排序。实体提及和候选实体的不同向量表示生成方法对应了不同的工作。
基于信息检索的方法将每个知识图谱实体对应的维基百科文档作为该实体的表示,并基于该类文档对全部知识图谱实体建立索引。给定输入文本中的一个实体提及m,该类方法首先从输入文本中找到包含m的全部句子集合,并通过去停用词等过滤操作生成一个查询语句。然后,使用该查询语句从知识图谱实体对应的索引中查找得到相关性最高的知识图谱实体,作为m的实体链接结果。
无监督学习方法通常适用于长文本实体链接任务,这是由于短文本无法很好地生成实体提及对应的向量表示或查询语句。
5.3 基于答案排序的方法
绝大多数基于语义分析的知识图谱问答需要带有语义标注的问题集合作为训练数据。这类数据需要花费的时间和成本很高,而且要求标注人员对语义表示有一定程度的理解。使用答案作为弱监督训练语义分析模型,能够在一定程度上缓解数据标注难度高、开销大和标注量有限等问题,但按照答案选择出来的正例语义分析候选存在一定的噪音,这在一定程度上也会对语义分析模型的质量造成影响。
基于答案排序(Answer Ranking)的知识图谱问答将该任务看成一个信息检索任务:即给定输入问题Q和知识图谱KB,通过对KB中实体进行打分和排序,选择得分最高的实体或实体集合作为答案输出。
具体来说,该类知识图谱问答方法主要包含下述四个模块:
1.问题实体识别。问题实体是指问题Q中提到的知识库实体,例如在Who founded Microsoft这个问题中,Microsoft在知识图谱中对应的实体是该问题的问题实体。每个问题可能对应多个问题实体,该类实体的识别通常采用实体链接技术完成;
2.答案候选检索。根据识别出来的一个问题实体,从知识图谱中查找与之满足特定约束条件的知识库实体集合,作为该问题的答案候选。最常用的约束条件是:在知识图谱中,与问题实体最多通过两个谓词相连的知识库实体。该做法假设问题对应的答案实体和问题实体在知识图谱中的距离通常不会很远;
3.答案候选表示。由于每个答案候选无法直接与输入问题进行比较,该模块基于答案候选所在的知识图谱上下文,生成答案候选对应的向量表示。这样,输入问题和答案候选之间的相关度计算就转化为输入问题和答案候选对应向量表示之间的相关度计算。具体方法的不同主要体现就在如何生成答案的向量表示上;
4.答案候选排序。使用排序模型对不同答案候选进行打分和排序,并返回得分最高的答案候选集合作为输出结果。
图5-5给出基于答案排序的知识图谱问答方法的工作流程示意图,按照对答案候选的不同表示方法,本章将介绍五种具体的方法,包括特征工程方法、问题生成方法、子图匹配方法、向量表示方法和记忆网络方法。
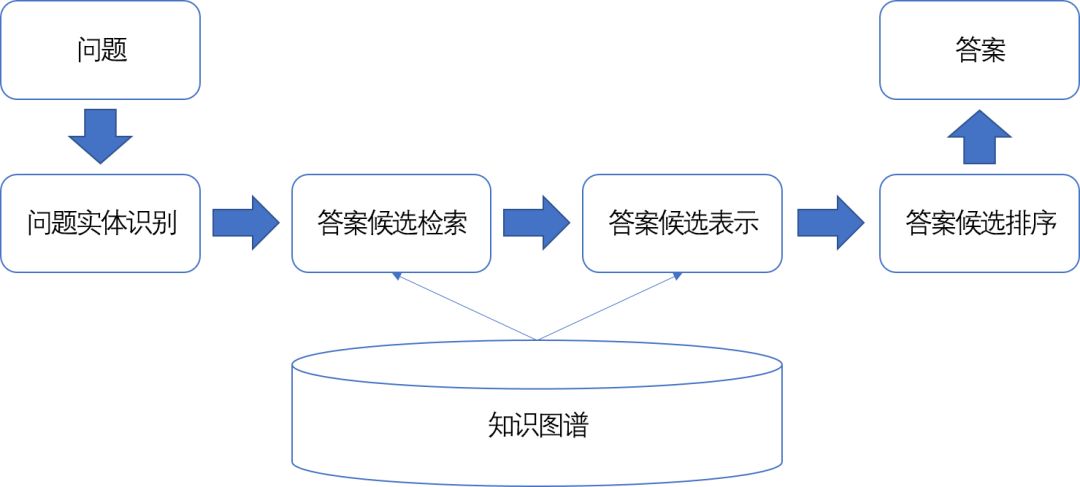
图5-5:基于答案排序的知识图谱问答流程图
作者介绍

段楠博士,微软亚洲研究院自然语言计算组主管研究员,主要从事包括智能问答、语义理解、对话系统和网络搜索等在内的自然语言处理基础研究,在ACL、EMNLP、COLING、AAAI、IJCAI、CVPR、KDD等国际会议中发表论文40余篇,发明专项6项,其多项研究成果已成功应用到微软核心人工智能产品中,包括必应搜索、Cortana语音助手和微软小冰等。

周明博士,微软亚洲研究院副院长,国际计算语言学协会(ACL)会长,中国计算机学会理事、中文信息技术专委会主任、中国中文信息学会常务理事、中国五所顶尖大学的博士生导师。周明博士1991年获哈尔滨工业大学博士学位。1991-1993年清华大学博士后,随后留校任副教授。1996-1999访问日本高电社公司领导中日机器翻译研究。1999年,周明博士加入微软亚洲研究院。长期担任微软亚洲研究院的自然语言处理的负责人。他是2018首都劳动奖章获得者。

内容简介
《机器翻译》一书以简明易懂的语言对机器翻译技术给予了全面介绍,兼顾经典的统计机器翻译以及目前飞速发展的神经机器翻译技术。同时,此书注重理论和实践结合。读者在深入浅出地理解理论体系后,可以借助实例和本书所介绍的工具快速入门,掌握机器翻译的训练和解码的主要技术。
本书分为七章:第一章回顾机器翻译发展的历史并介绍机器翻译技术的各种应用;第二章介绍如何获取用于机器翻译模型训练的单语和双语数据的方法以及机器翻译自动评价方法;第三章介绍统计机器翻译系统的基础架构、建模方法和基本模型以及模型的参数训练方法;第四章介绍典型的统计机器翻译系统模型,包括基于短语的、基于形式文法的和基于句法的统计机器翻译模型系统;第五章介绍深度学习的基础知识,包括感知机、词语嵌入模型、卷积神经网络和循环神经网络;第六章系统介绍神经机器翻译,包括神经联合模型和基于序列映射的神经机器翻译模型以及注意力机制。除此之外,还介绍了基于卷积神经网络的编码器和解码器的神经机器翻译模型以及完全基于注意力网络的模型;第七章进一步深入讨论了神经机器翻译在模型改进、模型训练、翻译解码等方面的前沿进展。
精彩章节节选
6.6 完全基于注意力网络的神经翻译模型
在前边我们提到,注意力网络通过将源语言句子的隐含状态和目标语言句子的隐含状态直接链接,从而缩短了源语言词的信息到生成对应目标语言词的传递路径,显著得提高了翻译质量。基于循环神经网络的编码器和解码器,每个词的隐含状态都依赖于前一个词的信息,所以编码的状态是顺序生成的。这用编码的顺序生成严重影响了模型的并行能力。另一方面,尽管基于门的循环神经单元可以解决梯度消失或者爆炸的问题,然而相距太远的词的信息仍然不能保证被考虑进来。尽管卷积神经网络可以提高并行化的能力,然而只能考虑一定窗口内的历史信息。为了同时解决这些问题,可以将两个额外的注意力网络引入编码器和解码器的内部,分别用于解决源语言句子和目标语言句子内部词语之间的依赖关系。基于这样的考虑, Vaswani 等人提出了完全基于注意力网络的神经翻译模型(Transformer),在本节中将对该方法进行详细的介绍。
6.6.1 基于注意力网络的编码器和解码器
如图 6-22 所示,编码器由 N 个同构的网络层堆叠而成,每一个网络层包含两个子网络层:第一个子网络层称为分组自注意力网络,用于将同层的源语言句子里的其它词的信息通过自注意力网络考虑进来以生成当前当前词的上下文向量;第二个子网络层是一个全联通的前馈神经网络,该网络的作用是将自注意力网络生成的源语言句子内的上下文向量同当前词的信息进行整合,从而生成考虑了整个句子上下文的当前时刻的隐含状态。 为提高模型的训练速度,残差链接(Residual Connection)和层规范化(Layer Normalization)被用于这两个子网络层,即图中的 Add&Norm 层,定义为LayerNorm(x +SubLayer(x)),其中x为子网络的输入,SubLayer为该子网络的处理函数,LayerNorm为层规范化函数。通过对 N 个这样的网络层堆叠可以对信息进一步地进行抽象和融合。为了引入残差网络,同构网络中每242 个子网络的输出,以及词向量和位置编码(Positional Encoding)都需要保持同样的长度。
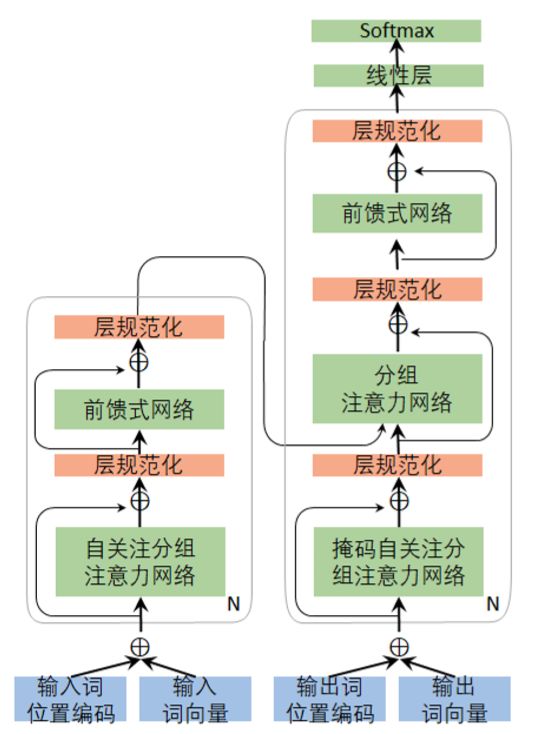
图 6-22:完全基于注意力网络的神经翻译模型
解码器同样包含堆叠的N个同构网络层,每个网络层包含三个子网络层:第一个子网络层同编码器的第一个子网络层类似,是一个分组自注意力网络,负责将同层的目标语言句子里的其它词的信息考虑进来生成一个目标语言句子内的上下文向量。不同于编码器的自注意力网络,解码器在解码的时候只能够看到已经生成的词的信息,对于未生成的内容,可以使用掩码(mask)机制将其屏蔽掉。第二个子网络层为分组的注意力网络,该网络作用同 6.4 节中原始的注意力网络层类似,负责将源语言句子的隐含状态同目标语言的隐含状态进行比较生成源语言句子的上下文向量。第三个子网络层同编码器的第二个子网络层类似,是一个全联通的前馈神经网络,该网络的作用是将自注意力网络生成的目标语言句子内的上下文向量,注意力网络生成的源语言句子的上下文向量,以及当前词的信息进行整合,从而更好的预测下一个目标语言测。同编码器类似,残差网络(Residual Connection)和层规范化(Layer Normalization)也被用于解码器的三个子网络层。
作者介绍

李沐博士,曾任微软亚洲研究院自然语言计算组资深研究员。研究领域和兴趣包括自然语言处理,大规模数据挖掘,深度学习,机器翻译等。在国际知名期刊和会议上发表论文70余篇,并对Windows、Office以及必应等多项微软产品做出过重要贡献。

刘树杰博士,微软研究院自然语言计算组主管研究员,主要研究领域为自然语言处理、机器学习、机器翻译以及深度神经网络在自然语言处理中的应用等。

张冬冬博士,微软亚洲研究院自然语言计算组主管研究员,主要从事机器翻译的理论研究与系统开发工作,发表学术论文近50篇,是微软翻译、必应词典、Skype Translator等产品的重要贡献者。
周明博士,微软亚洲研究院副院长,国际计算语言学协会(ACL)会长,中国计算机学会理事、中文信息技术专委会主任、中国中文信息学会常务理事、中国五所顶尖大学的博士生导师。周明博士1991年获哈尔滨工业大学博士学位。1991-1993年清华大学博士后,随后留校任副教授。1996-1999访问日本高电社公司领导中日机器翻译研究。1999年,周明博士加入微软亚洲研究院。长期担任微软亚洲研究院的自然语言处理的负责人。他是2018首都劳动奖章获得者。
欢迎大家在留言区分享你对NLP领域的见解,我们将挑选点赞数前两名的小伙伴,送上周明博士亲笔签名的赠书一本!
留言截止时间:2019年1月27日
两本书均已在京东上架,点击“阅读原文”,直达购买页面
活动最终解释权归微软亚洲研究院所有
你也许还想看:
● 书单 | 《分布式机器学习:算法、理论与实践》——理论、方法与实践的全面汇总(文末有福利)

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




