利用神经网络进行序列到序列转换的学习

本文为 雷锋字幕组优秀译者 YunfanDL 编译的论文翻译,原标题 :
Sequence to Sequence Learning with Neural Networks
作者 | Ilya Sutskever, Oriol Vinyals, Quoc V. Le
翻译 | YunfanDL
论文链接:
https://arxiv.org/abs/1409.3215
注:本文的相关链接请访问文末【阅读原文】
0. 摘要
深度神经网络是在困难的学习任务中取得卓越性能的强大模型。尽管拥有大量的标记训练集,DNN就能很好地工作,但是它们并不能用于将序列映射到序列。在本文中,我们提出了一种通用的端到端序列学习方法,它对序列结构作出最小的假设。我们的方法使用多层长短期记忆网络(LSTM)将输入序列映射到一个固定维度的向量,然后使用另一个深层LSTM从向量中解码目标序列。我们的主要结果是,在WMT 14数据集的英法翻译任务中,LSTM的翻译在整个测试集中获得了34.8分的BLEU分数,而LSTM的BLEU分数在词汇外的单词上被扣分。此外,LSTM人在长句上没有困难。相比之下,基于短语的SMT在同一数据集上的BLEU得分为33.3。当我们使用LSTM对上述系统产生的1000个假设进行重新排序时,它的BLEU分数增加到36.5,这接近于之前在这项任务中的最佳结果。LSTM还学会了对词序敏感、并且对主动语态和被动语态相对不变的有意义的短语和句子表达。最后,我们发现颠倒所有源句(而不是目标句)中单词的顺序显著提高了LSTM的表现,因为这样做在源句和目标句之间引入了许多短期依赖性,使得优化问题变得更容易。
1. 导言
深层神经网络(DNNs)是非常强大的机器学习模型,它在语音识别[13,7]和视觉目标识别[19,6,21,20]等难题上取得卓越的性能。DNNs非常强大,因为它们可以执行任意并行计算的步骤比较少。DNN强大功能的一个令人惊讶的例子是,它们能够只使用2个二次大小的隐藏层来分类N比特数[27]。因此,虽然神经网络与传统的统计模型相关,但它们学习的是复杂的计算。此外,只要标记的训练集有足够的信息来指定网络的参数,就可以用监督的反向传播来对大型的DNN训练。因此,如果存在获得良好结果的大DNN的参数设置(例如,因为人类可以非常快速地解决任务),则监督反向传播将找到这些参数并解决问题。
尽管DNN具有灵活性和强大的功能,但它适用于输入和目标可以用固定维数的向量进行合理编码的问题。这有很明显的局限性,因为许多重要的问题最好是能够用长度未知的序列来表达。例如,语音识别和机器翻译是连续的问题。同样,问题回答也可以看作是将将表示问题的单词序列映射到表示答案的单词序列。因此,很明显,学习将序列映射到序列的与域无关的方法将是有用的。
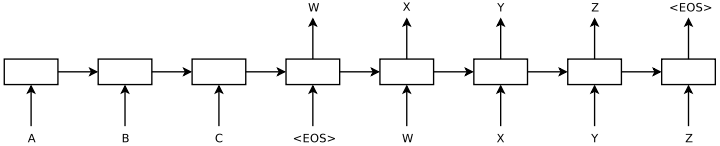
序列对DNN来说是一个挑战,因为它们要求输入和输出的维数是已知并且是固定的。在本文中,我们展示了长短期记忆网络(LSTM)架构[16]的直接应用可以解决一般序列到序列的问题。想法是使用一个LSTM来读取输入序列,一次一步,以获得大的固定维向量表示,然后使用另一个LSTM来从该向量中提取输出序列(图1)。第二个LSTM本质上是一个递归神经网络语言模型[28,23,30]除了它是以输入序列为条件。由于输入和相应输出之间存在相当大的时间延迟,LSTM成功学习具有长期时间依赖性的数据的能力使其成为该应用的自然选择(图1)。
已经有许多相关的尝试来解决用神经网络排序学习问题的一般顺序。我们的方法与卡尔奇布伦纳和布伦森·[[18]密切相关,他们是第一个将整个输入句子映射到向量的人,并且与乔等人有关。[5]尽管后者仅用于重新证明基于短语的系统产生的假设。格雷夫斯·[10]引入了一种新颖的可区分注意机制,这种机制允许神经网络聚焦于输入的不同部分,这一思想的一个优雅变体被巴赫达诺等人成功地应用于机器翻译。[2]。连接序列分类是用神经网络将序列映射到序列的另一种流行技术,但是它假设输入和输出之间单调对齐,[11]。
图1:我们的模型读取一个输入句子“ABC”,并产生“WXYZ”作为输出句子。这个模型在输出句尾标记后停止预测。需要注意的是,LSTM反过来读取输入语句,因为这样做会在数据中引入许多短期依赖性,从而使优化问题变得更加容易。
这项工作的主要成果如下。在WMT的14个英法翻译任务中,我们通过使用简单的从左到右波束搜索解码器直接从5个深度的LSTMs(每个深度LSTMs具有384M参数和8000维状态)的集合中提取翻译,获得了34.81的BLEU分数。这是迄今为止用大型神经网络直接翻译获得的最佳结果。相比之下,在该数据集上SMT基准的BLEU分数为33.30 [29]。34.81 BLEU分数是由一个拥有80k单词词汇量的LSTM人获得的,因此每当参考译文包含这80k单词未涵盖的单词时,该分数就会被扣分。该结果表明,相对未优化的小词汇量神经网络体系结构比基于短语的SMT系统具有更大的改进空间。
最后,我们利用LSTM重新获得了在同一任务中可公开获得的1000个最佳工管基准列表[29]。通过这样做,我们获得了36.5分的BLEU分数,这将基准提高了3.2个BLEU点,并且接近于之前关于该任务的最佳发表结果(即37.0 [9])。
令人惊讶的是,LSTM没有在很长的句子受到影响,尽管其他研究人员最近有相关结构的经验[26]。我们能够在长句上做得很好,因为我们颠倒了源句中的单词顺序,而不是训练和测试集中的目标句。通过这样做,我们引入了许多短期依赖性,这使得优化问题变得简单得多(参见第节)。2和3.3)。因此,SGD可以学习没有长句子问题的LSTMs。颠倒源句中单词的简单技巧是这项工作的关键技术贡献之一。
LSTM的一个有用的特性是它学会将可变长度的输入句子映射成固定维向量表示。鉴于翻译往往是源句的释义,翻译目标鼓励LSTM寻找能捕捉其意义的句子表征,因为具有相似意义的句子彼此接近而不同句子的意义会相差很远。一项定性评估支持了这一说法,表明我们的模型知道词序,并且对主动语态和被动语态相当不变。
2. 模型
递归神经网络(RNN) [31,28]是前馈神经网络对序列的自然推广。给定输入序列(x1,… , xT),标准RNN计算输出序列(y1,… ,yT)通过迭代以下等式:
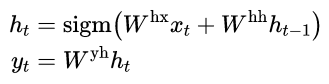
只要提前知道输入和输出之间的对齐,RNN就可以轻松地将序列映射到序列。然而,还不清楚如何将RNN应用于输入和输出序列具有不同长度且具有复杂和非单调关系的问题。
通用序列学习的最简单策略是使用一个RNN将输入序列映射到固定大小的向量,然后使用另一个RNN将向量映射到目标序列(这种方法也被Cho等人采用。[5])。虽然它原则上是可行的,因为向RNN提供了所有相关信息,但由于由此产生的长期依赖关系,很难训练区域网络(图1) [14、4、16、15]。然而,众所周知的是长短期记忆网络(LSTM) [16]学习长期时间依赖的问题,因此LSTM可能在这种情况下取得成功。
LSTM的目标是估计条件概率p(y1,..,yT’| x1,.. ,xT)其中(x1,.. ,xT)是输入序列,y1,…yT’为其对应的输出序列, 其长度T’可能与T不同,LSTM通过首先获得输入序列(x1,…,xT)由LSTM的最后一个隐藏状态给出,然后计算y1,.. ,yT’,其初始隐藏状态被设置为x1,.. ,xT:
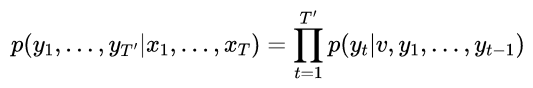
在这个等式中,每个p(yt|v,y1,… yt-1)分布用词汇表中所有单词的softmax表示。我们使用格雷夫斯[10]的LSTM公式。请注意,我们要求每个句子都以一个特殊的句尾符号“< EOS >”结尾,这使得模型能够定义所有可能长度序列的分布。总体方案如图1所示,图中所示的LSTM计算“A”、“B”、“C”、“< EOS >”的表示,然后使用该表示计算“W”、“X”、“Y”、“Z”、“< EOS >”的概率。
我们的实际模型在三个重要方面不同于上面的描述。首先,我们使用了两种不同的LSTM:一种用于输入序列,另一种用于输出序列,因为这样做以可以忽略的计算成本增加了模型参数的数量,并且使得在多种语言对上同时训练LSTM变得很自然[18]。第二,我们发现deep LSTMs明显优于shallow LSTMs,所以我们选择了一个有4层的LSTM。第三,我们发现颠倒输入句子的单词顺序非常有价值。因此,举例来说,不是把句子a、b、c映射到句子α、β、γ,而是要求LSTM把c、b、a映射到α、β、γ,其中α、β、γ是a、b、c的翻译。这样,a非常接近α,b非常接近β,以此类推,这使得SGD很容易在输入和输出之间“建立通信”。我们发现这种简单的数据转换大大提高了LSTM的性能。
3. 实验
我们以两种方式将我们的方法应用于WMT14英语到法语的机器翻译任务中。我们用它来直接翻译输入的句子,而不使用引用的SMT系统,我们用它来重新存储SMT基准的n个最佳列表。我们报告这些翻译方法的准确性,呈现示例翻译,并可视化结果句子表示。
3.1 数据集详细信息
我们使用了WMT14英语到法语数据集。我们对我们的模型进行了12M感知子集的训练,该子集由348M法语单词和304M英语单词组成,这是[29]的一个干净的“精选”子集。我们选择此翻译任务和此特定训练集子集,是因为标记化训练和测试集以及基准SMT [29]中的1000个最佳列表可供公众使用。
由于典型的神经语言模型依赖于每个单词的向量表示,我们对两种语言都使用了固定的词汇。我们对源语言使用了160000个最频繁的单词,对目标语言使用了80000个最频繁的单词。每个词汇外的单词都被一个特殊的“UNK”标记代替。
3.2 解码和重新评分
我们实验的核心是在许多句子对上训练一个大而深的LSTM。我们通过最大化给定源句子的正确翻译的对数概率来训练它,所以训练目标是
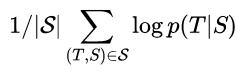
此处S是训练集, 训练完成后,我们会根据LSTM的说法,通过寻找最有可能的翻译来进行翻译:
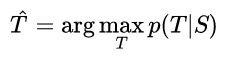
我们使用简单的从左到右波束搜索解码器来搜索最可能的翻译,该解码器维护少量的部分假设B,其中部分假设是一些翻译的前缀。在每个时间步长中,我们用词汇中的每一个可能的单词来扩展波束中的每一个部分假设。这极大地增加了假设的数量,因此我们根据模型的对数概率丢弃除了最有可能的假设B之外的所有假设。一旦“< EOS >”符号被附加到一个假设上,它就从波束中移除,并被添加到一组完整的假设中。虽然这个解码器是近似的,但实现起来很简单。有趣的是,我们的系统即使在波束大小为1的情况下也表现良好,而波束大小为2的情况提供了波束搜索的大部分好处(表1)。
我们还利用LSTM重新获得了基准系统[29]产生的1000个最佳列表。为了重新获得n-best列表,我们用我们的LSTM计算了每个假设的对数概率,并用他们的分数和LSTM的分数取了一个平均分。
3.3 反转源语句
虽然LSTM能够解决具有长期依赖关系的问题,但是我们发现,当源语句被反转(目标语句没有反转)时,LSTM学习得更好。通过这样做,LSTM的测试perplexity从5.8下降到4.7,其解码翻译的测试BLEU分数从25.9增加到30.6。
虽然我们对这一现象没有一个完整的解释,但我们认为这是由于对数据集引入了许多短期依赖关系造成的。通常,当我们把源句和目标句连接起来时,源句中的每个单词都与目标句中的对应单词相差很远。因此,该问题具有很大的“最小时间延迟”[17]。通过颠倒源句中的单词,保持源语言中对应单词与目标语言的平均距离不变。然而,源语言中的前几个单词现在与目标语言中的前几个单词非常接近,因此问题的最小时间延迟大大减少。因此,反向传播更容易在源句和目标句之间“建立通信”,从而大大提高了整体性能。
起初,我们认为颠倒输入句子只会导致目标句子早期部分更有信心的预测,而后期部分的预测则不那么有信心。然而,在反转源句上训练的学习者在长句上比学习者做得好得多接受原始源句子的训练(参见第节)。3.7),这表明颠倒输入句子会导致更好的记忆利用。
3.4 训练详情
我们发现LSTM模型很容易训练。我们使用了对4层layers的深度LSTMs,每层有1000个单元,1000维单词嵌入,输入词汇为160000,输出词汇为80000。因此,深层LSTM使用8000个实数来表示一个句子。我们发现deep LSTM明显优于shallow LSTMs,shallow LSTMs中每增加一层,困惑就减少了近10%,这可能是因为它们的隐藏状态要大得多。我们在每次输出中使用了超过80000个单词的softmax。由此产生的LSTM有384M参数,其中64M是纯循环连接(32M用于“编码器”LSTM,32M用于“解码器”LSTM)。完整的训练详情如下:
我们用-0.08和0.08之间的均匀分布初始化了所有LSTM参数
我们使用无动量的随机梯度下降,固定学习率为0.7。五个epoch之后,我们开始每半个epoch将学习率减半。我们总共使用7.5个epoch训练我们的模型。
我们对梯度使用了128个序列的批次,并将其除以批次的大小(即128)。
虽然LSTMs往往不会遇到梯度消失的问题,但它们可能会出现爆炸梯度。因此,当梯度[10,25]的范数超过阈值时,我们通过缩放它来对其范数施加硬约束。对于每个训练批次,我们计算s = ||g||2,其中g是梯度除以128。如果s > 5,我们设置g = 5g / s。
不同的句子有不同的长度。大多数句子很短(例如,长度为20-30),但是一些句子很长(例如,长度大于100),因此由128个随机选择的训练句子组成的minibatch将具有许多短句和很少长句,结果,minibatch中的大部分计算被浪费了。为了解决这个问题,我们确保minibatch中的所有句子长度大致相同,速度提高了2倍。
3.5 并行化
一个c++实现的深层LSTM配置从上一节对一个GPU处理速度约1700字每秒。这对于我们的目的来说太慢了,所以我们使用8-GPU机器并行化我们的模型。LSTM的每一层都是在不同的GPU上执行的,一旦计算完成,就把它的激活传递给下一层GPU /层。我们的模型有4层LSTMs,每一层都位于一个单独的GPU上。剩下的4个GPU用于并行化softmax,因此每个GPU负责乘以一个1000×20000矩阵。最终实现的速度达到每秒6300个单词(包括英语和法语),小批处理大小为128。实施这一计划花了大约十天的时间进行训练。
3.6 实验结果
我们使用[24]的案例BLEU评分来评估我们的翻译质量。我们用标记化预测和地面实况计算了我们的BLEU分数。这种评估BELU分数的方法与[5]和[2]相一致,并且复制了[29]的33.3分。然而,如果我们以这种方式评估最好的WMT14系统9,我们得到37.0,这比statmt.org\matrix报告的35.8大。
结果见表1和表2。我们的最佳结果是通过一组LSTMs获得的,这些LSTMs的随机初始化和小批次的随机顺序不同。虽然LSTM集成的解码翻译并不优于最好的WMT14系统,但这是第一次在大规模MT任务中,一个纯神经翻译系统在很大程度上超过基于短语的SMT基准,尽管它无法处理词汇表外的单词。如果使用LSTM重新确定基准系统的1000个最佳列表,则LSTM距离最佳WMT14结果的0.5个BLEU点以内。
BLEU分数有几个变体,每个变体都是用perl脚本定义的。
| Method | test BLEU score(ntst14) |
|---|---|
| Bahdanau et al. [2] | 28.45 |
| Baseline System [29] | 33.30 |
| Single forward LSTM beam size 12 | 26.17 |
| Single reversed LSTM, beam size 12 | 30.59 |
| Ensemble of 5 reversed LSTMs, beam size 1 | 33.00 |
| Ensemble of 2 reversed LSTMs, beam size 12 | 33.27 |
| Ensemble of 5 reversed LSTMs, beam size 2 | 34.50 |
| Ensemble of 5 reversed LSTMs, beam size 12 | 34.81 |
表1:LSTM在WMT14个英语转为法语测试集中的表现。请注意,波束尺寸为2的5个LSTMs的系综比波束尺寸为12的单个LSTM要便宜。
| Method | test BLEU score(ntst14) |
|---|---|
| Baseline System [29] | 33.30 |
| Cho et al. [5] | 34.54 |
| Best WMT’14 result [9] | 37.0 |
| Rescoring the baseline 1000-best with a single forward LSTM | 35.61 |
| Rescoring the baseline 1000-best with a single reversed LSTM | 35.85 |
| Rescoring the baseline 1000-best with an ensemble of 5 reversed LSTMs | 36.5 |
| Oracle Rescoring of the Baseline 1000-best lists | ∼45 |
表2:在WMT 14英语到法语测试集中使用神经网络和表面贴装系统的方法。
3.7 长句子的表现
我们惊讶地发现LSTM在长句上表现很好,这在图3中有定量显示。表3给出了几个长句及其翻译的例子。
3.8 模型分析
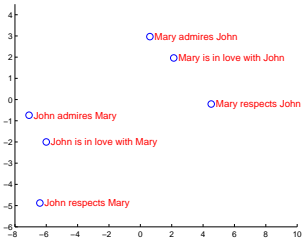

图2:该图显示了获得的LSTM隐藏态的二维主成分分析投影,在处理了图中的短语之后。短语按意义进行聚类,在这些例子中,意义主要是词序的函数,用单词袋模型很难捕捉到。请注意,两个集群具有相似的内部结构。
我们模型的一个吸引人的特征是它能够将一系列单词转化为固定维度的向量。图2可视化了一些学习到的表示。该图清楚地表明,这些表示对单词的顺序很敏感,而对用被动语态替换主动语态则相当不敏感。利用主成分分析得到二维投影。

表3:LSTM与真实值译文一起制作的长译文的几个例子。读者可以使用谷歌翻译来验证这些翻译是否合理。(点击文末阅读原文可查看高清表格)
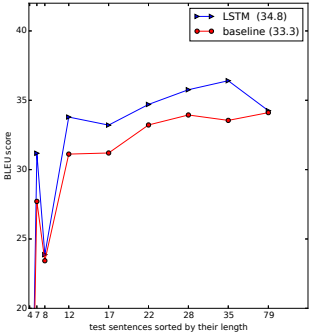
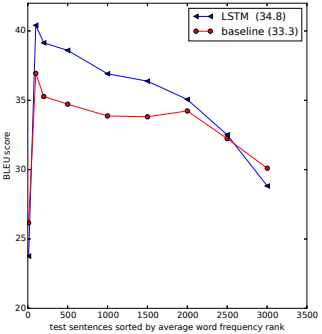
图3:左图显示了我们的系统作为句子长度函数的性能,其中x轴对应于按长度排序的测试句子,并由实际序列长度标记。少于35个单词的句子没有降级,最长的句子只有轻微的降级。右图显示了LSTM在单词越来越少的句子中的表现,其中x轴对应于按“平均单词频率等级”排序的测试句子。
4. 相关工作
关于神经网络在机器翻译中的应用,有大量的工作要做。迄今为止,应用RNN语言模型的最简单和最有效的方法是[23]或任务的前馈神经网络语言模型(NNLM) [3]是通过重新存储强机器翻译基准的n-最佳列表[22],这可靠地提高了翻译质量。
最近,研究人员开始研究将源语言信息纳入NNLM的方法。这项工作的例子包括Auli等人。[1],他将NNLM和输入句子的主题模型结合起来,这提高了重写性能。Devlin等人[8]也采用了类似的方法,但是他们把他们的NNLM输入到机器翻译系统的解码器中,并使用解码器的对齐信息为NNLM提供输入句子中最有用的单词。他们的方法非常成功,比基准有了很大的改进。
我们的工作与卡尔奇布伦纳(Kalchbrenner)和布伦森·[(Blunsom 18)关系密切,他们是第一个将输入句子映射成向量,然后再映射回句子的人,尽管他们使用卷积神经网络将句子映射到向量,这种网络会丢失单词的排序。类似于这项工作,Cho等人。[5]使用类似LSTM的RNN架构将句子映射成向量,然后再映射回来,尽管他们的主要关注点是将他们的神经网络集成到一个SMT系统中。Bahdanau等人[2]还尝试用神经网络进行直接翻译,该神经网络使用注意机制来克服赵等人在长句上表现不佳的问题。[5]并取得了令人鼓舞的成果。同样,Pouget-Abadie等人。[26]试图解决赵等人的记忆问题。[5]通过翻译源句子的片段来产生流畅的翻译,这类似于基于短语的方法。我们怀疑他们可以通过简单地训练他们的网络使用反源句来实现类似的改进。
端到端训练也是赫尔曼等人关注的焦点。[12],其模型代表前馈网络的输入和输出,并将它们映射到空间中的相似点。然而,他们的方法不能直接生成翻译:为了得到翻译,他们需要在预先计算好的句子数据库中查找最接近的向量,或者重写一个句子。
5. 结论
在这项工作中,我们展示了一个大而深的LSTM,它的词汇量有限,而且几乎没有对问题结构作出任何假设,在大规模机器翻译任务中,它的词汇量可以超过一个标准的基于表面贴装技术的系统。我们基于LSTM的简单方法在机器翻译上的成功表明,如果他们有足够的训练数据,它应该在许多其他序列学习问题上做得很好。
我们对通过颠倒源句中的单词所获得的改善程度感到惊讶。我们的结论是,找到一个短期依赖性最大的编码问题是很重要的,因为它们使学习问题变得简单得多。特别是,虽然我们不能在非反向翻译问题上训练标准的RNN(如图1所示),但我们相信当源句反向时,标准的RNN应该很容易训练(尽管我们没有通过实验来验证)。
我们还对LSTM能够正确翻译非常长的句子感到惊讶。我们最初确信,LSTM人会因为记忆力有限而在长句上失败,其他研究人员报告说,与我们相似的模型在长句上表现不佳[5,2,26]。然而,在反向数据集上训练的LSTMs翻译长句没有什么困难。
最重要的是,我们证明了一种简单、直接和相对非优化的方法可以胜过SMT系统,因此进一步的工作可能会导致更高的翻译准确性。这些结果表明,我们的方法很可能在其他具有挑战性的排序问题上表现良好。
6. 致谢
非常感谢萨米·本吉奥、杰夫·迪恩、马蒂厄·迪文、杰弗里·辛顿、纳尔·卡尔奇布伦纳、唐龙、沃尔夫-冈·马切里、拉杰特·艋舺、文森特·范胡凯、徐鹏、沃伊切赫·扎伦巴和谷歌大脑团队的有益评论和讨论。
7. 引用
[1] M. Auli, M. Galley, C. Quirk, and G. Zweig. Joint language and translation modeling with recurrent
neural networks. In EMNLP, 2013.
[2] D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate.
arXiv preprint arXiv:1409.0473, 2014.
[3] Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin. A neural probabilistic language model. In Journal of
Machine Learning Research, pages 1137–1155, 2003.
[4] Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult.
IEEE Transactions on Neural Networks, 5(2):157–166, 1994.
[5] K. Cho, B. Merrienboer, C. Gulcehre, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Arxiv preprint arXiv:1406.1078,
2014.
[6] D. Ciresan, U. Meier, and J. Schmidhuber. Multi-column deep neural networks for image classification.
In CVPR, 2012.
[7] G. E. Dahl, D. Yu, L. Deng, and A. Acero. Context-dependent pre-trained deep neural networks for large
vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing - Special
Issue on Deep Learning for Speech and Language Processing, 2012.
[8] J. Devlin, R. Zbib, Z. Huang, T. Lamar, R. Schwartz, and J. Makhoul. Fast and robust neural network
joint models for statistical machine translation. In ACL, 2014.
[9] Nadir Durrani, Barry Haddow, Philipp Koehn, and Kenneth Heafield. Edinburgh’s phrase-based machine
translation systems for wmt-14. In WMT, 2014.
[10] A. Graves. Generating sequences with recurrent neural networks. In Arxiv preprint arXiv:1308.0850,
2013.
[11] A. Graves, S. Fern´andez, F. Gomez, and J. Schmidhuber. Connectionist temporal classification: labelling
unsegmented sequence data with recurrent neural networks. In ICML, 2006.
[12] K. M. Hermann and P. Blunsom. Multilingual distributed representations without word alignment. In
ICLR, 2014.
[13] G. Hinton, L. Deng, D. Yu, G. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen,
T. Sainath, and B. Kingsbury. Deep neural networks for acoustic modeling in speech recognition. IEEE
Signal Processing Magazine, 2012.
[14] S. Hochreiter. Untersuchungen zu dynamischen neuronalen netzen. Master’s thesis, Institut fur Informatik, Technische Universitat, Munchen, 1991.
[15] S. Hochreiter, Y. Bengio, P. Frasconi, and J. Schmidhuber. Gradient flow in recurrent nets: the difficulty
of learning long-term dependencies, 2001.
[16] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 1997.
[17] S. Hochreiter and J. Schmidhuber. LSTM can solve hard long time lag problems. 1997.
[18] N. Kalchbrenner and P. Blunsom. Recurrent continuous translation models. In EMNLP, 2013.
[19] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural
networks. In NIPS, 2012.
[20] Q.V. Le, M.A. Ranzato, R. Monga, M. Devin, K. Chen, G.S. Corrado, J. Dean, and A.Y. Ng. Building
high-level features using large scale unsupervised learning. In ICML, 2012.
[21] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition.
Proceedings of the IEEE, 1998.
[22] T. Mikolov. Statistical Language Models based on Neural Networks. PhD thesis, Brno University of
Technology, 2012.
[23] T. Mikolov, M. Karafi´at, L. Burget, J. Cernock`y, and S. Khudanpur. Recurrent neural network based
language model. In INTERSPEECH, pages 1045–1048, 2010.
[24] K. Papineni, S. Roukos, T. Ward, and W. J. Zhu. BLEU: a method for automatic evaluation of machine
translation. In ACL, 2002.
[25] R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks. arXiv
preprint arXiv:1211.5063, 2012.
[26] J. Pouget-Abadie, D. Bahdanau, B. van Merrienboer, K. Cho, and Y. Bengio. Overcoming the
curse of sentence length for neural machine translation using automatic segmentation. arXiv preprint
arXiv:1409.1257, 2014.
[27] A. Razborov. On small depth threshold circuits. In Proc. 3rd Scandinavian Workshop on Algorithm
Theory, 1992.
[28] D. Rumelhart, G. E. Hinton, and R. J. Williams. Learning representations by back-propagating errors.
Nature, 323(6088):533–536, 1986.
[29] H. Schwenk. University le mans. http://www-lium.univ-lemans.fr/˜schwenk/cslm_
joint_paper/, 2014. [Online; accessed 03-September-2014].
[30] M. Sundermeyer, R. Schluter, and H. Ney. LSTM neural networks for language modeling. In INTERSPEECH, 2010.
[31] P. Werbos. Backpropagation through time: what it does and how to do it. Proceedings of IEEE, 1990.
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/blogDetail/11165
AI求职百题斩 · 每日一题

AI研习社IJCAI小组组长本周将采访大咖教授:Victor R. Lesser
大家有什么问题想要问Victor R. Lesser的,都可以在IJCAI小组里面进行提问!
扫码即刻参与提问,带话题#提问 IJCAI 大咖#,提问采纳者有机会获得礼品一份,小组研值累积排行前三者,更有机会获得 AI 研习社赞助的「直达顶会」的机票+酒店等参会费用,让你亲临大会现场,和大咖面对面~。