BERT模型蒸馏有哪些方法?

©PaperWeekly 原创 · 作者|蔡杰
学校|北京大学硕士生
研究方向|问答系统
-
pretrain-利用大量的未标记数据通过一些自监督的学习方式学习丰富的语义和句法知识。例如:Bert 的 MLM,NSP 等等。
-
finetune-将预训练过程中所学到的知识应用到子任务中,以达到优异的效果。
-
预训练模型高计算复杂度-不可能在实时系统中运行。
-
大存储需求——预训练模型一般都很大,少则几百 M,大则几 G,无法在有限资源的设备上部署。

Logit Distillation
知识蒸馏最早是 Hinton 在 15 年提出的一个黑科技技术,核心思想是通过迁移知识,从而通过训练好的大模型得到更加适合推理的小模型。

论文标题:Distilling the Knowledge in a Neural Network
论文来源:NIPS 2014
论文链接:http://arxiv.org/abs/1503.02531
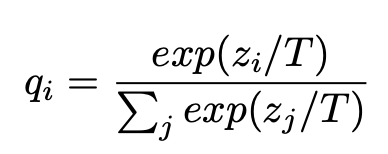

论文中用了对 softmax 的公式进行了推导,如果 T 远高于对数的量级,且对数为零均值,则上图公式(4)和公式(2)和几乎相同。在 T 非常小的情况下,梯度会接近于 qi-pi,所以当多个类别的 pi 接近于 0 时,最终输出的相似性信息是没有体现在梯度中的,所以网络会忽略掉这些信息;


论文标题:TinyBERT: Distilling BERT for Natural Language Understanding
论文来源:ICLR 2020
论文链接:http://arxiv.org/abs/1909.10351
代码链接:https://github.com/huawei-noah/Pretrained-Language-Model
-
Embedding Layer
-
Transformer Layer(Hidden States 和 Attention Matricies)
-
Prediction Layer
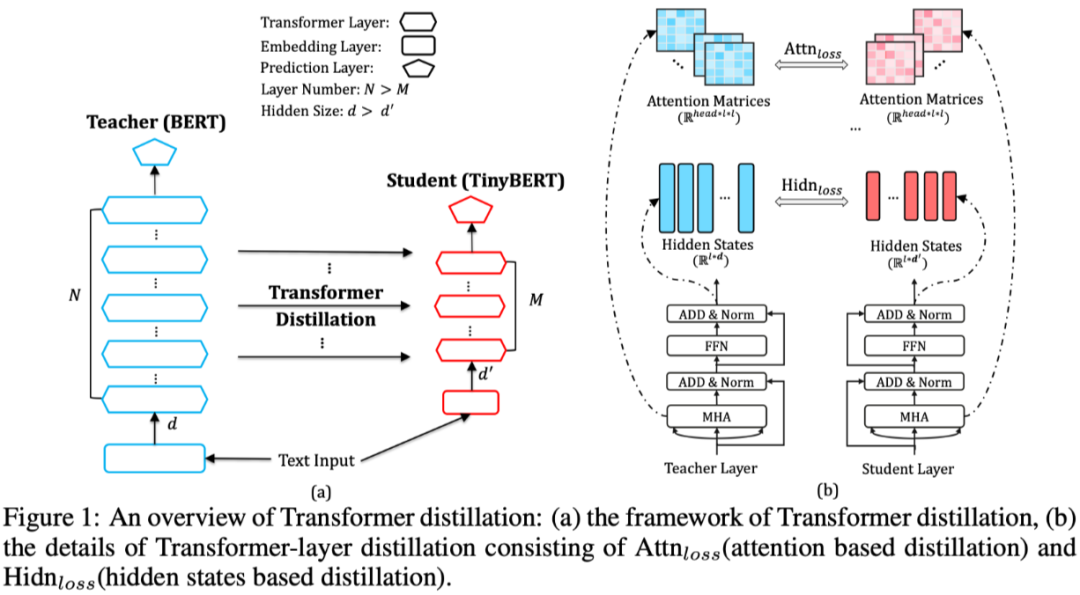
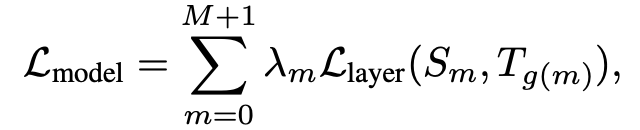
构造的 Loss 都是清一色的 MSE 函数:
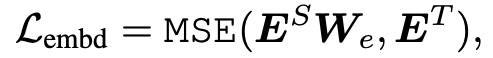
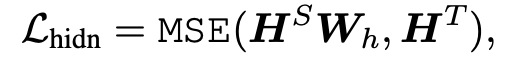
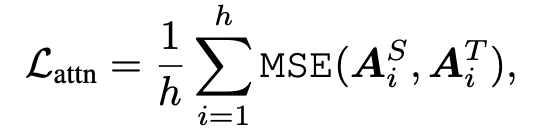
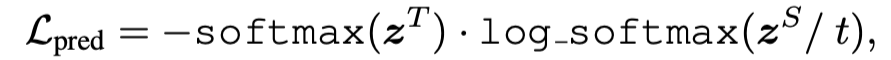
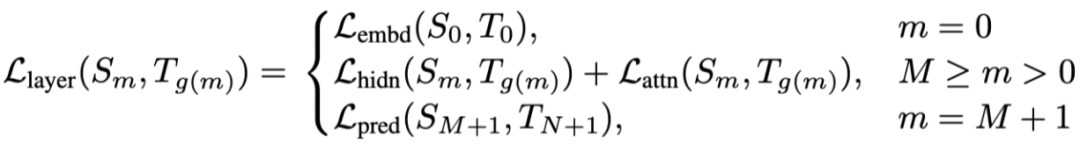
通过论文中的实证研究表明了 TinyBERT 的有效性,在 GLUE 上达到了与 BERT 相当(下降 3 个百分点)的效果,同时模型大小只有 BERT 的 13.3%(BERT 是 TinyBERT 的 7.5 倍),Inference 的速度是 BERT 的 9.4 倍。


论文标题:FitNets : Hints for Thin Deep Nets
论文来源:ICLR 2015
论文链接:https://arxiv.org/abs/1412.6550
代码链接:https://github.com/adri-romsor/FitNets
蒸馏时采用的中间层匹配本质上是一种正则化形式,Transformer 的分层蒸馏可能会导致过度正则化。
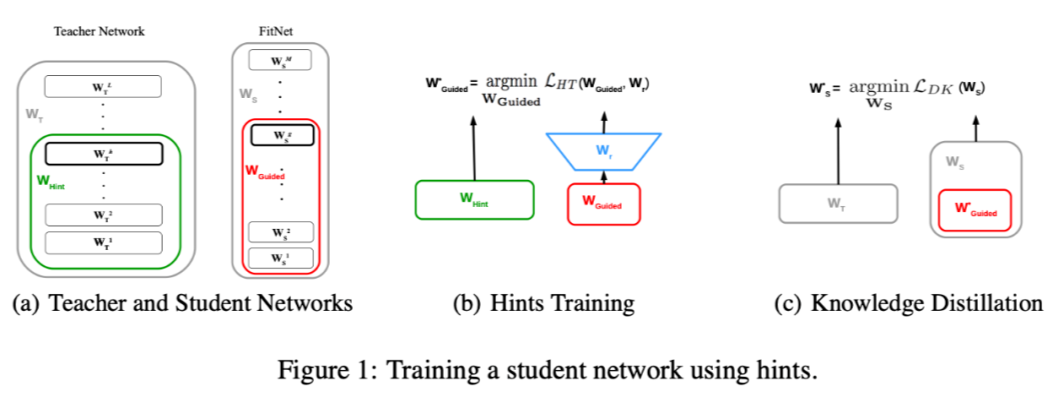

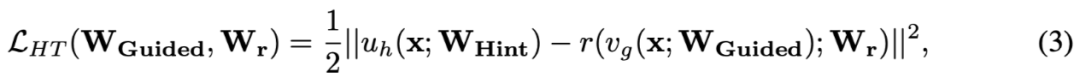
r 代表 hidden 层的一个额外的映射关系,Wr 是其中的参数,这是为了使得 hidden 层与 hint 层的神经元大小一致。
Fig. 1 (a) 作者选择 FitNet 的一个隐藏层,作为学习层,去学习 teacher model 的某一层(引导层)。我们希望学习层能够预测引导层的输出。
Fig. 1 (b) 作者从一个训练过的 teacher 网络和一个随机初始化的 FitNet 开始,在 FitNet 学习层的顶部加入一个由 Wr 参数化的回归因子,将 FitNet 参数 WGuided 训练到学习层,使 Eq.(3) 最小化 (Fig. 1 (b))。
最后,从预训练的参数中,我们对整个 FitNet 的 Ws 的参数进行训练,使 Eq.(2) 最小化 (Fig. 1 (c))。
从实验结果上看,student 比 teacher 参数少,效果却比 teacher 还要好,可能是因为网络更深的原因,某种程度上说明了深层网络的有效性,深层网络的表示性能要更优一些。

Dynamic Early Exit

论文标题:FastBERT: a Self-distilling BERT with Adaptive Inference Time
论文来源:ACL 2020
论文链接:https://arxiv.org/abs/2004.02178
代码链接:https://github.com/autoliuweijie/FastBERT
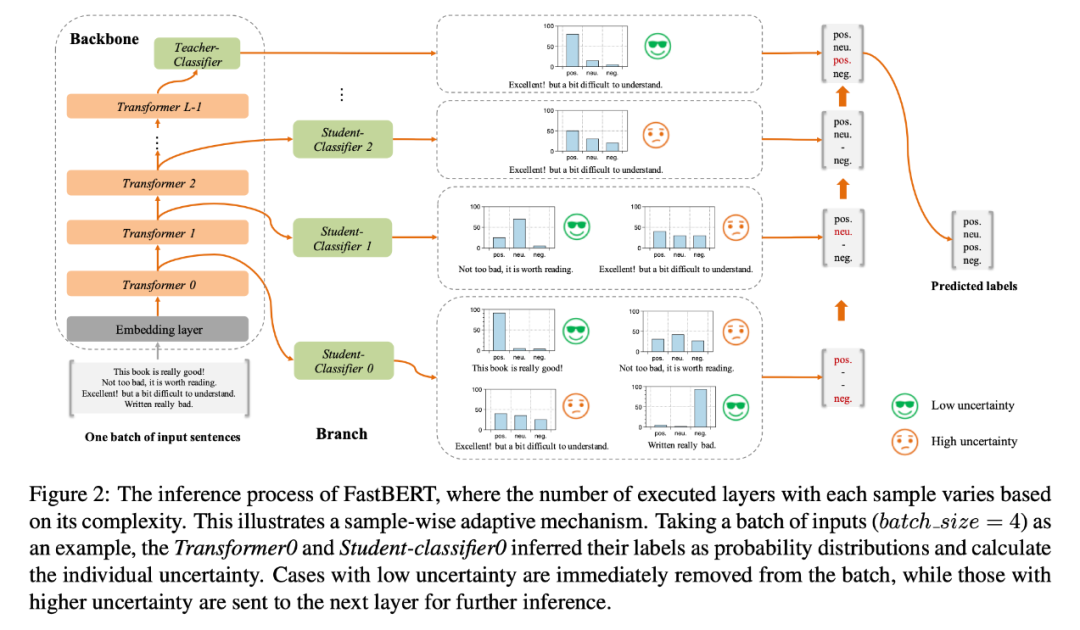
原 BERT 模型为主干(Backbone),每个分类器称为分支(Branch),其中分支 Classifier 都是由最后一层的分类器蒸馏而来,在预训练和微调阶段都只调整主干参数,finetune 之后主干参数 freeze,把最后一层classifier蒸馏到每一层 student classifier 中。
之所以叫自蒸馏,因为 student 和 teacher 都是由一个模型得到的,以往的 KD 都是两个模型,student 模型经过参数初始化,让 teacher 模型去优化 student 模型。
一共包含以下几个阶段:
-
Pre-training:和 BERT 预训练的流程一致,主要是要得到一个预训练模型。
-
Fine-tuning for Backbone:Backbone 的微调,也就是训练一个 Bert 的分类器,预训练模型后添加一层 classifier,classifier 的参数用于后期的指导训练。
-
Self-distillation for branch:分支(branch)的自蒸馏,每一层都有一个 student 的 classfier,由微调过的 Bert 的最后一层 classifier 蒸馏而来,每个 branch 都有一个 classifier。
-
Adaptive inference:自适应 inference,可以根据样本的难易程度决定样本要走几层分支分类器,简单的样本可以在底层直接给结果,困难的继续往高层走。
同类的文章还有:

论文标题:DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
论文来源:ACL 2020
论文链接:https://arxiv.org/abs/2004.12993
代码链接:https://github.com/castorini/DeeBERT

论文标题:DynaBERT: Dynamic BERT with Adaptive Width and Depth
论文来源:NeurIPS 2020
论文链接:https://arxiv.org/abs/2004.04037
代码链接:https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/DynaBERT
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





