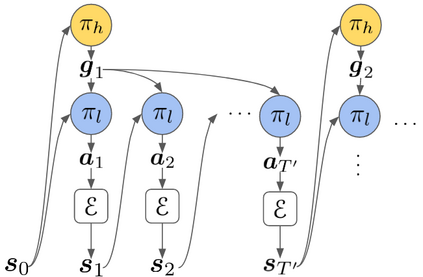
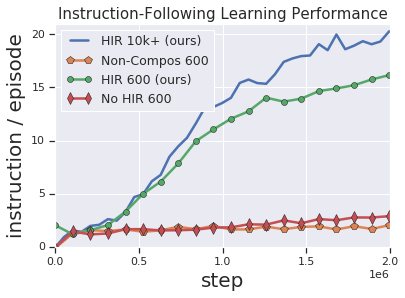
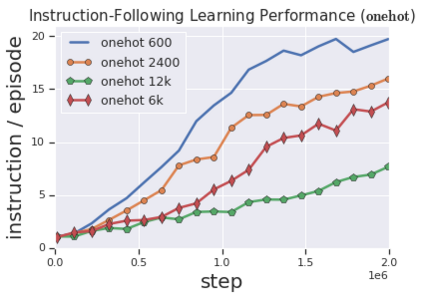
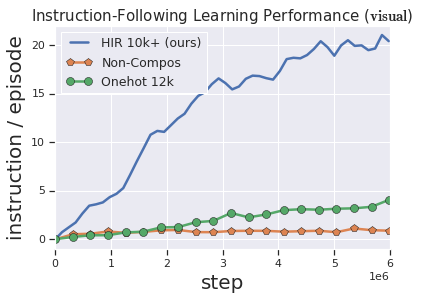
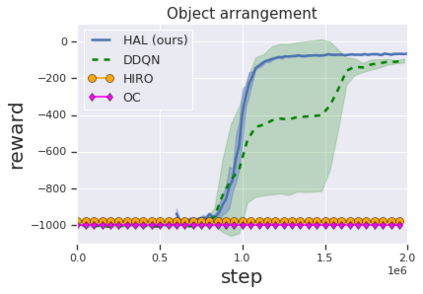
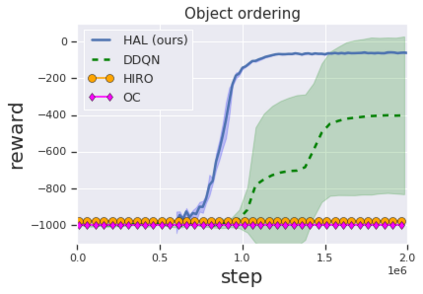
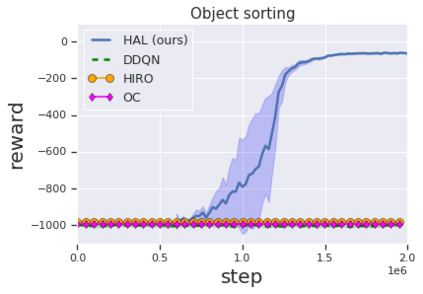
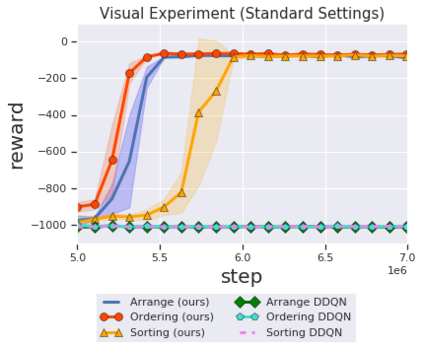
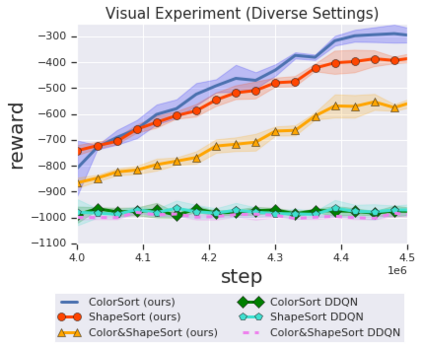
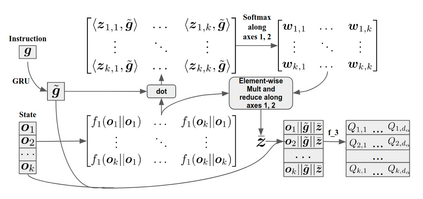
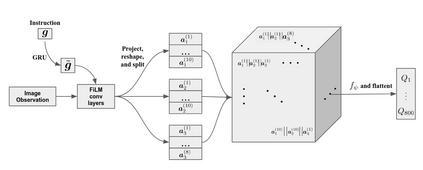
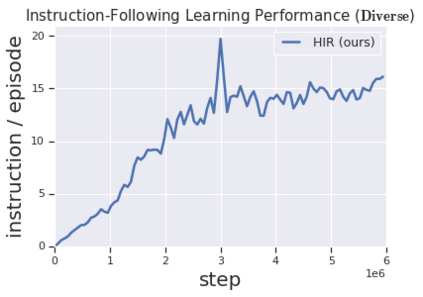
Solving complex, temporally-extended tasks is a long-standing problem in reinforcement learning (RL). We hypothesize that one critical element of solving such problems is the notion of compositionality. With the ability to learn concepts and sub-skills that can be composed to solve longer tasks, i.e. hierarchical RL, we can acquire temporally-extended behaviors. However, acquiring effective yet general abstractions for hierarchical RL is remarkably challenging. In this paper, we propose to use language as the abstraction, as it provides unique compositional structure, enabling fast learning and combinatorial generalization, while retaining tremendous flexibility, making it suitable for a variety of problems. Our approach learns an instruction-following low-level policy and a high-level policy that can reuse abstractions across tasks, in essence, permitting agents to reason using structured language. To study compositional task learning, we introduce an open-source object interaction environment built using the MuJoCo physics engine and the CLEVR engine. We find that, using our approach, agents can learn to solve to diverse, temporally-extended tasks such as object sorting and multi-object rearrangement, including from raw pixel observations. Our analysis find that the compositional nature of language is critical for learning diverse sub-skills and systematically generalizing to new sub-skills in comparison to non-compositional abstractions that use the same supervision.
翻译:解决复杂、时间上延伸的任务是一个长期存在的强化学习问题。 我们假设,解决这类问题的一个关键要素是构成概念的概念。 学习概念和子技能的能力可以用来解决长期任务, 即等级RL, 我们可以获得暂时延伸的行为。 但是, 获得高等级RL 的有效但一般的抽象是极具挑战性的。 在本文件中, 我们提议使用语言作为抽象, 因为它提供了独特的抽象结构, 使得快速学习和组合化的概括化, 同时保留巨大的灵活性, 使它适合各种问题。 我们的方法可以学习一种遵循低层次政策和高层次政策, 能够重新利用跨任务的抽象性, 即等级RL, 实质上, 允许代理人使用结构化语言来理解。 但是, 我们使用 MuJoCo 物理引擎和 CLEVR 引擎来构建一个开放源的物体互动环境。 我们发现, 使用我们的方法, 代理人可以学会解决多种、 时间延伸的任务, 比如, 对象排序和多层次的分组分析, 包括系统化的分组分析, 系统化的分级分析, 系统化的分级的分级分析, 。