动物脑的好奇心和强化学习的好奇心
Visual novelty, curiosity, and intrinsic reward in machine learning and the brain
https://arxiv.org/abs/1901.02478
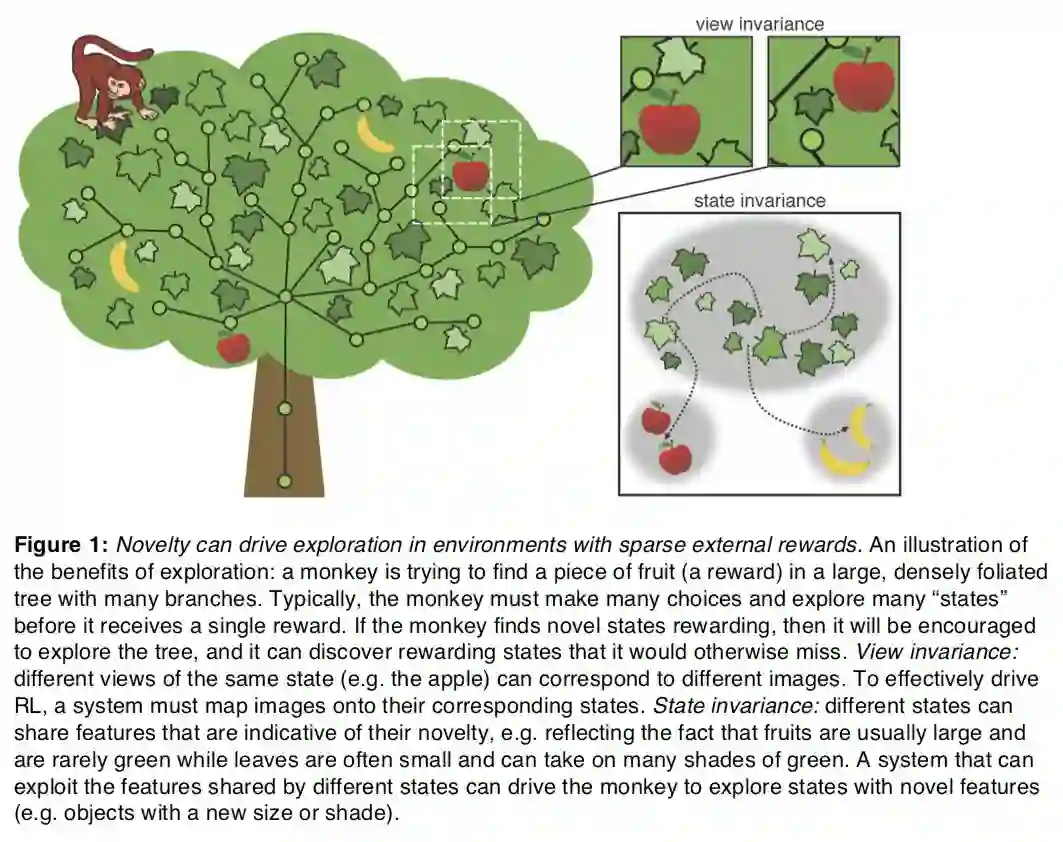
关于生物脑的好奇心介绍了比较强的动物能力的例子。
Andrew Jaegle, Vahid Mehrpour, Nicole Rust
(Submitted on 8 Jan 2019)
A strong preference for novelty emerges in infancy and is prevalent across the animal kingdom. When incorporated into reinforcement-based machine learning algorithms, visual novelty can act as an intrinsic reward signal that vastly increases the efficiency of exploration and expedites learning, particularly in situations where external rewards are difficult to obtain. Here we review parallels between recent developments in novelty-driven machine learning algorithms and our understanding of how visual novelty is computed and signaled in the primate brain. We propose that in the visual system, novelty representations are not configured with the principal goal of detecting novel objects, but rather with the broader goal of flexibly generalizing novelty information across different states in the service of driving novelty-based learning.
view invariance
state invariance:
One class of recent proposals for novelty-driven RL addressed the view and state invariance challenges by incorporating a method for computing similarity between images. Some of these proposals extend classic count-based proposals by first mapping similar images to the same bin (e.g. using a hash function [17] or by clustering [18]) before counting. A complementary proposal [19] estimated image similarity by training a DNN to estimate the distance in time between pairs of images, motivated by the observation that temporal continuity can capture invariance [20]. Instead of counting how many times states had been visited, this method estimated an image’s novelty by comparing it to familiar images held in a memory buffer.
Another class of proposals for novelty-driven RL used “pseudocounts” to estimate novelty. In contrast to explicit count-based proposals, pseudocount methods address the invariance problems using a model (e.g. a DNN) trained to estimate the probability of images. Pseudocounts are computed based on how the probability of an image changes between the Nth and (N+1)th times it is viewed, where N is often zero (see [21] for the exact expression). Because these methods approximate continuous probabilities, they are well suited to scenarios where the dimensionality is high and hence nearly all counts are zero, but some stimuli are more probable than others. Because pseudocount methods are based on the response after repeated exposure to an image, they bare some similarity to the phenomenon of repetition suppression in the visual system (see below for a discussion of the role of repetition suppression in novelty computation in the brain). Several recent papers have achieved promising results using pseudocounts to drive exploration on difficult RL tasks [21-23].
How does novelty seeking relate to other types of intrinsic motivation? In the case of pseudocount estimates, an important theoretical link has been established between estimates of novelty and the amount of information gain [24] that follows from observing an image [21]. Intuitively, this is because the novelty of an image reflects how much it differs from what we expect to see based on what we’ve seen in the past. Early work on intrinsic motivation established the link between curiosity and measures of image informativeness, such as information gain [25,26]. While the information gained by observing an image cannot be computed directly, several methods have been proposed to approximate it to drive exploration [27,28]. A number of recent papers have also proposed other, related signals to drive exploration, including methods that estimate image informativeness by how variable or
4
unreliable the response to the image is [29], how well the response of a target model can be predicted [30], and by how difficult it is to predict what will follow an image in time [31-33]. Unlike methods for novelty-driven RL, these methods do not estimate novelty explicitly, but they share the goal of driving exploration by estimating the informativeness of images.
Computing and signaling novelty in the primate brain
Our ability to detect visual novelty (or equivalently remember whether we have seen an image) is quite remarkable – for example, we can view thousands of photographs, each only once and each for a few seconds, and then distinguish with high accuracy the specific images that we have already seen from those that remain novel to us [34]. Even after viewing as many as 10,000 distinct photographs, our rates of remembering do not saturate, suggesting that this type of single-exposure visual memory has an exceedingly large capacity [34,35]. The most remarkable aspects of our ability to detect visual novelty are thought to be mediated by our “familiarity” memory system. One effective illustration of familiarity is the experience that we all occasionally have of seeing someone and remembering that we know them but not being able to recall any details about them, at least for a few moments, and this “sense of remembering absent details” is precisely what the familiarity memory system supports. In contrast to recollection-based memories (e.g. of the details about that person, such as their name), which are thought to be largely mediated by the hippocampus, familiarity is thought to be mediated by another brain area in the medial temporal lobe, perirhinal cortex, as well its input from the part of the visual system involved in signaling object and scene information, inferotemporal cortex (IT) [reviewed by 36,37].
How do these brain areas signal visual novelty? Novelty is thought to be signaled in IT and perirhinal cortex via an adaptation-like change in firing rate in response to familiar as compared to novel stimuli, a phenomenon referred to as repetition suppression [38-42]. Consistent with the signatures needed to account for the vast capacity of human single-exposure visual memory behavior, firing rate reductions with familiarity are selective for images, even after viewing large numbers of them, and these response decrements last for several minutes to hours following the single viewing of an image [39,40,42]. These putative visual novelty signals are mixed with signals reflecting visual identity, both within the responses of individual neurons and across the IT population. That is, visual identities of images and their content are thought to be reflected as distinct patterns of spikes across the IT population, and this translates into a population representation in which visual information about the currently-viewed scene is reflected by a population’s vector angle [Fig. 2; reviewed by 43]. In contrast, novelty is thought to be signaled by overall firing rates or equivalently the length of the population response vector, where vectors are longer for novel images and become shorter as they become familiar [42]. Novelty and familiarity modulations are thought to be approximately multiplicative [44,45], which translates to a type of novelty coding for memory that maintains identity vector angle position, thereby preventing the interference of identity and novelty representations [42]. Repetition suppression magnitudes are also continuous and depend on factors such as the time since an image has been viewed, the duration of the viewing, and the number of repeated viewings [reviewed by 46]. This encoding scheme can account for behavior on a familiarity task with a decoder that maps IT neural response to behavior via a simple positively-weighted linear read-out [42].
How is novelty computed by the brain? In the framework described in Figure 2, this amounts to understanding the origin of IT repetition suppression. Repetition suppression is found at all stages of visual processing from the retina to IT, and it strengthens in its magnitude as well as the duration over which it lasts across the visual cortical hierarchy [47]. Consequently, a hierarchical cascade of feed-forward, adaptation-like mechanisms clearly contribute to IT repetition suppression [46]. There are also indications that IT repetition suppression may arise from changes in synaptic weights between recurrently connected units within IT [46,48] and/or feed-back mechanisms from higher brain areas (such as perirhinal cortex) [49,50], although the latter assertion has been the focus of some debate [reviewed by 46].
Highlighted references:
* Tang H, Houthooft R, Foote D, Stooke A, Chen OX, Duan Y, Schulman J, DeTurck F, Abbeel P: #Exploration: A study of count-based exploration for deep reinforcement learning. In Conference on Neural Information Processing Systems (NeurIPS): 2017:2753-2762.
This paper addressed the view and state invariance challenges by adapting count-based methods to image-based RL using hash functions that map images to a relatively small number of bins.
** Bellemare M, Srinivasan S, Ostrovski G, Schaul T, Saxton D, Munos R: Unifying count- based exploration and intrinsic motivation. In Conference on Neural Information Processing Systems (NeurIPS): 2016:1471-1479.
This paper introduced the notion of pseudocounts, which generalize count-based methods for novelty estimation and can be applied to RL problems with high- dimensional, continuous states such as images. The authors formally demonstrated the relationship between pseudocounts and information gain, suggesting that pseudocounts may lead to near-optimal exploration behavior.
* Savinov N, Raichuk A, Marinier R, Vincent D, Pollefeys M, Lillicrap T, Gelly S: Episodic curiosity through reachability. In International Conference on Learning Representations (ICLR): 2019. [19]
This paper computed an intrinsic reward signal that closely resembles a novelty computation using two interesting model components: a learned similarity measure and a memory buffer.
** Meyer T, Rust NC: Single-exposure visual memory judgments are reflected in inferotemporal cortex. eLife 2018, 7:e32259.
This paper demonstrated the plausibility of IT repetition suppression as a novelty signal by illustrating that a positively weighted linear read-out of IT responses could account for remembering and forgetting behavior as a function of time since an image was viewed.
* Hong H, Yamins DL, Majaj NJ, DiCarlo JJ: Explicit information for category-orthogonal object properties increases along the ventral stream. Nat. Neurosci. 2016, 19:613-622.
This paper demonstrated the robust and easily accessible representations of IT populations for properties beyond object identity, including object position.
end



