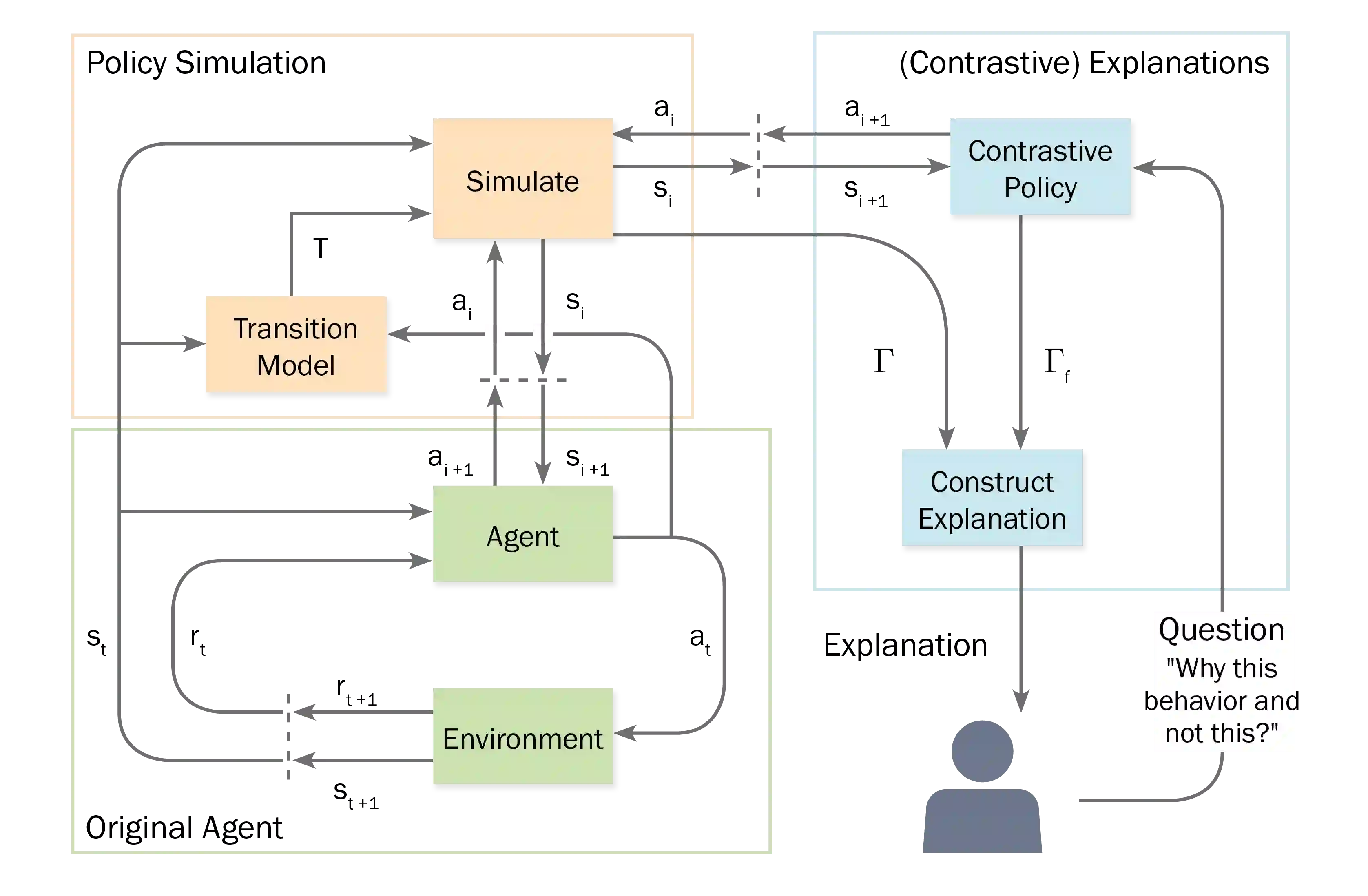
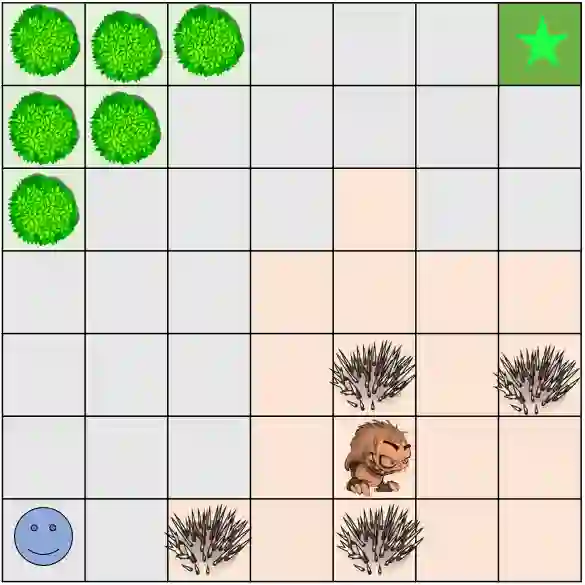
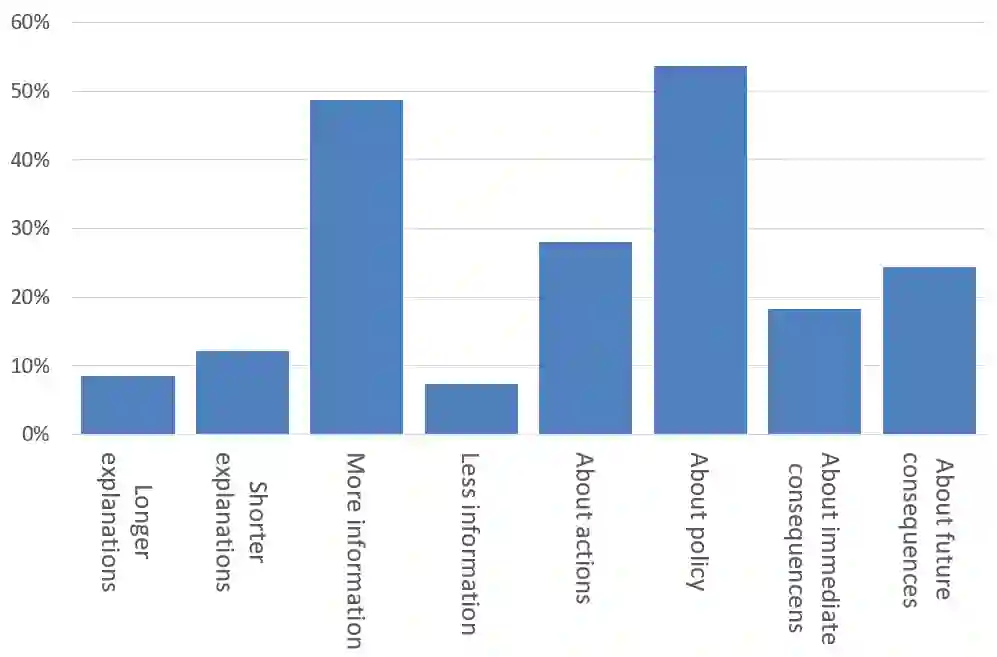
Machine Learning models become increasingly proficient in complex tasks. However, even for experts in the field, it can be difficult to understand what the model learned. This hampers trust and acceptance, and it obstructs the possibility to correct the model. There is therefore a need for transparency of machine learning models. The development of transparent classification models has received much attention, but there are few developments for achieving transparent Reinforcement Learning (RL) models. In this study we propose a method that enables a RL agent to explain its behavior in terms of the expected consequences of state transitions and outcomes. First, we define a translation of states and actions to a description that is easier to understand for human users. Second, we developed a procedure that enables the agent to obtain the consequences of a single action, as well as its entire policy. The method calculates contrasts between the consequences of a policy derived from a user query, and of the learned policy of the agent. Third, a format for generating explanations was constructed. A pilot survey study was conducted to explore preferences of users for different explanation properties. Results indicate that human users tend to favor explanations about policy rather than about single actions.
翻译:机器学习模式越来越精通复杂的任务。 但是,即使对实地专家来说,也可能很难理解模型学到了什么。这妨碍了信任和接受,也妨碍了纠正模型的可能性。因此,机器学习模式需要透明度。透明分类模式的开发引起了很大的注意,但实现透明的强化学习模式(RL)模式的发展却很少。在本研究中,我们提出了一个方法,使RL代理商能够从国家转型和结果的预期后果来解释其行为。首先,我们定义了一种国家和行动的翻译,以说明一种对人类用户来说比较容易理解的描述。第二,我们制定了一种程序,使代理商能够获得单一行动的后果,以及整个政策。这种方法计算出从用户查询得出的政策的后果和代理商的学习政策的后果。第三,设计了一种解释格式。进行了一项试点调查研究,以探讨用户对不同解释属性的偏好。结果表明,人类用户倾向于偏好对政策的解释,而不是单一行动的解释。