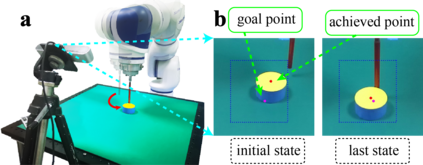
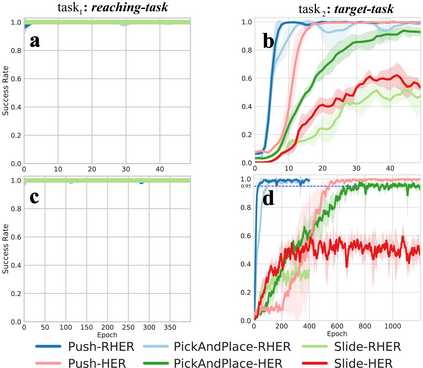
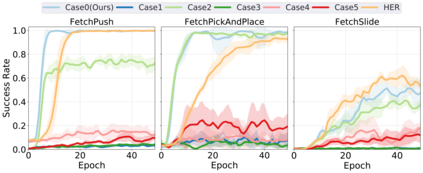
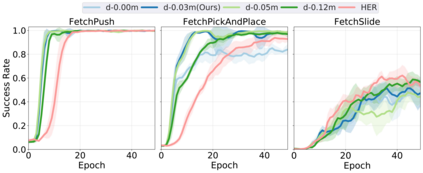
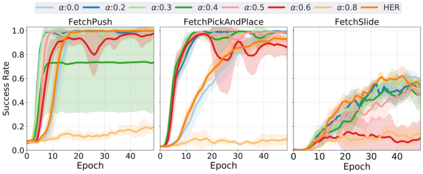
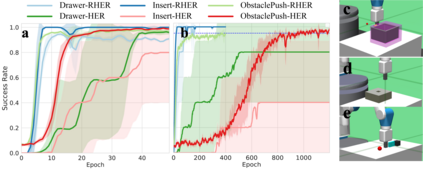
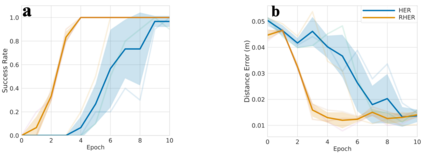
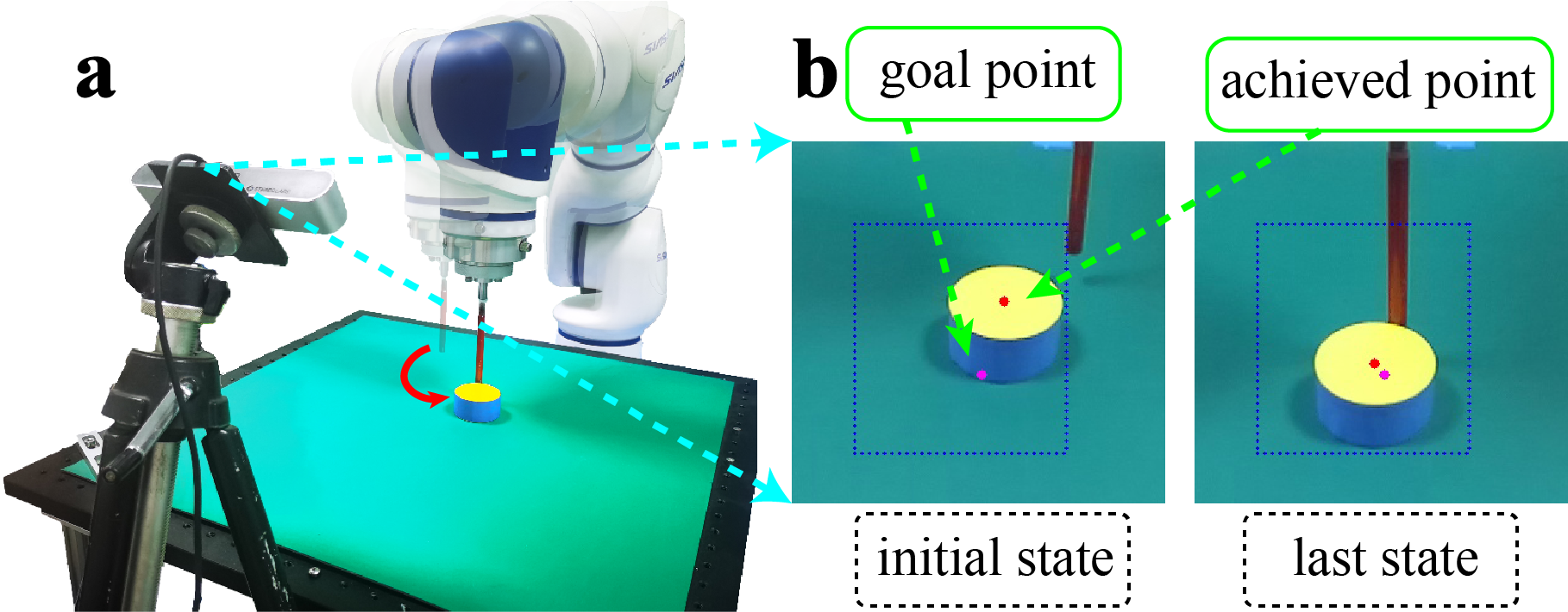
Learning with sparse rewards is usually inefficient in Reinforcement Learning (RL). Hindsight Experience Replay (HER) has been shown an effective solution to handle the low sample efficiency that results from sparse rewards by goal relabeling. However, the HER still has an implicit virtual-positive sparse reward problem caused by invariant achieved goals, especially for robot manipulation tasks. To solve this problem, we propose a novel model-free continual RL algorithm, called Relay-HER (RHER). The proposed method first decomposes and rearranges the original long-horizon task into new sub-tasks with incremental complexity. Subsequently, a multi-task network is designed to learn the sub-tasks in ascending order of complexity. To solve the virtual-positive sparse reward problem, we propose a Random-Mixed Exploration Strategy (RMES), in which the achieved goals of the sub-task with higher complexity are quickly changed under the guidance of the one with lower complexity. The experimental results indicate the significant improvements in sample efficiency of RHER compared to vanilla-HER in five typical robot manipulation tasks, including Push, PickAndPlace, Drawer, Insert, and ObstaclePush. The proposed RHER method has also been applied to learn a contact-rich push task on a physical robot from scratch, and the success rate reached 10/10 with only 250 episodes.
翻译:在加强学习(RL)中,以微薄的回报学习通常效率很低。 后视经验重现(HER)被证明是处理低抽样效率的有效办法,这种低抽样效率是通过目标重新标签而产生, 但由于目标的实现, 特别是机器人操纵任务, 她仍然存在着一个隐含的虚拟积极的微量报酬问题。 为了解决这个问题, 我们提议了一个新型的无模型的连续RL算法, 叫做Relay- Her(RHER) 。 拟议的方法首先拆解并重新将原始长视重现任务改成具有增量复杂性的新子任务。 随后, 一个多任务网络被设计来学习复杂程度不断上升的子任务。 为了解决虚拟积极的微量报酬问题, 我们建议了一个随机混合的探索战略, 其中, 在更复杂程度较低的指导下, 快速改变已完成的子任务 。 实验结果显示, 在五种典型的机器人操纵任务中, RHERPlace- Plac, Drawer, 以及一个与10 roclex 的学习速度, 也应用了一种与10 rocleast 的学习速度。