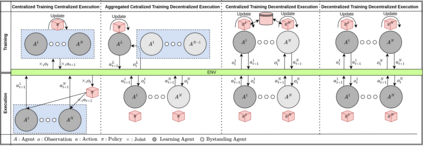
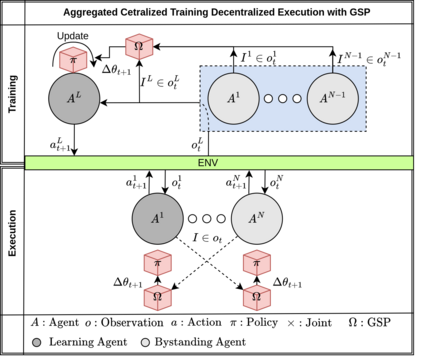
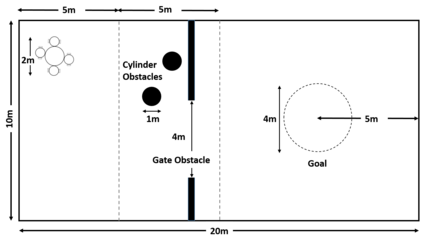
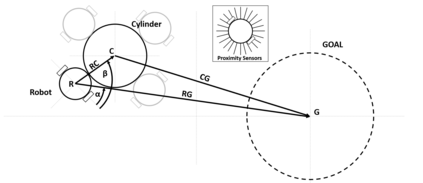
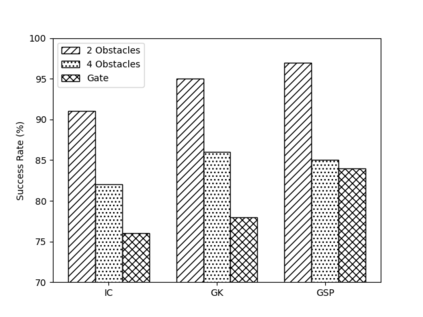
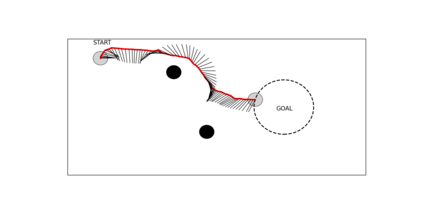
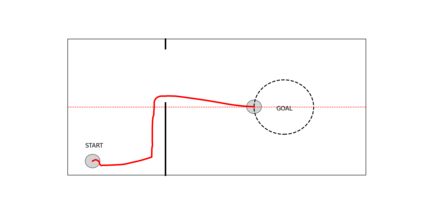
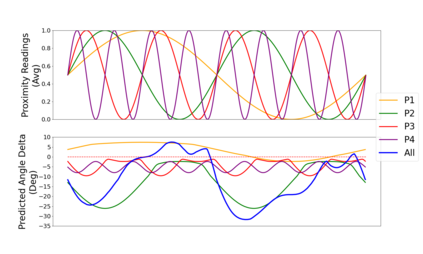
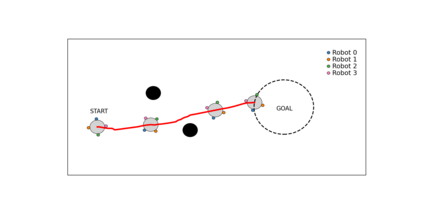
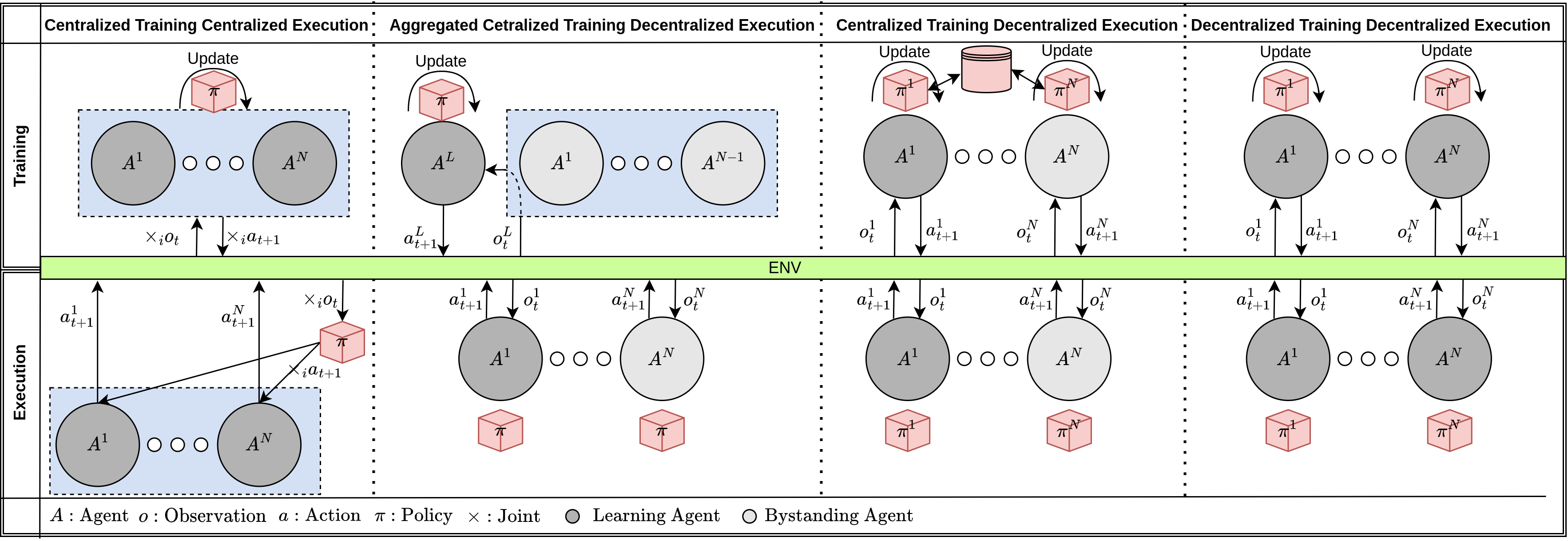
Deep reinforcement learning (DRL) has seen remarkable success in the control of single robots. However, applying DRL to robot swarms presents significant challenges. A critical challenge is non-stationarity, which occurs when two or more robots update individual or shared policies concurrently, thereby engaging in an interdependent training process with no guarantees of convergence. Circumventing non-stationarity typically involves training the robots with global information about other agents' states and/or actions. In contrast, in this paper we explore how to remove the need for global information. We pose our problem as a Partially Observable Markov Decision Process, due to the absence of global knowledge on other agents. Using collective transport as a testbed scenario, we study two approaches to multi-agent training. In the first, the robots exchange no messages, and are trained to rely on implicit communication through push-and-pull on the object to transport. In the second approach, we introduce Global State Prediction (GSP), a network trained to forma a belief over the swarm as a whole and predict its future states. We provide a comprehensive study over four well-known deep reinforcement learning algorithms in environments with obstacles, measuring performance as the successful transport of the object to the goal within a desired time-frame. Through an ablation study, we show that including GSP boosts performance and increases robustness when compared with methods that use global knowledge.
翻译:暂无翻译