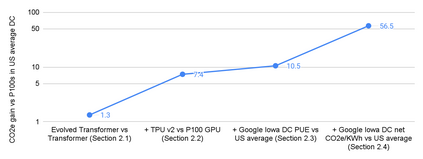
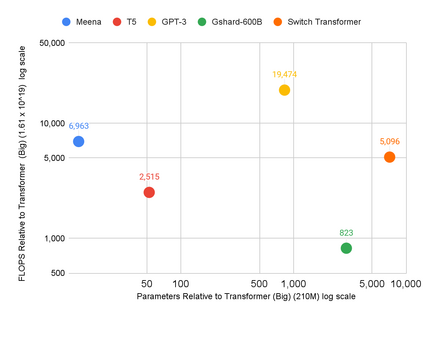
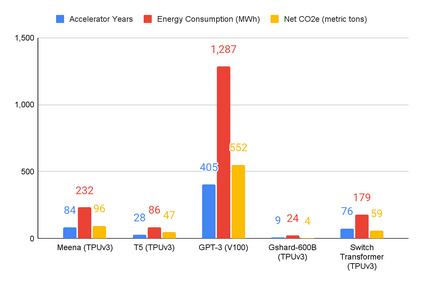
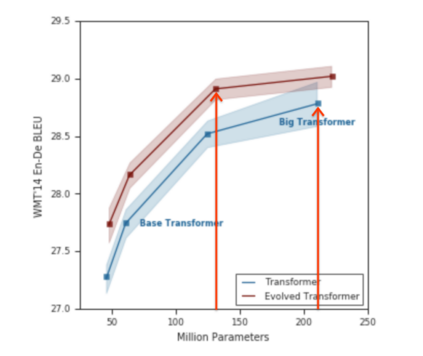
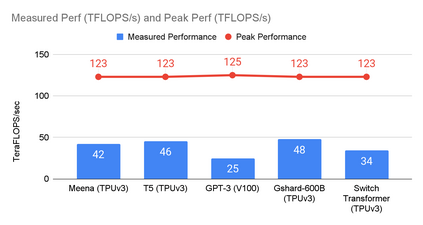
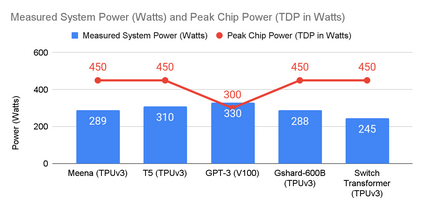
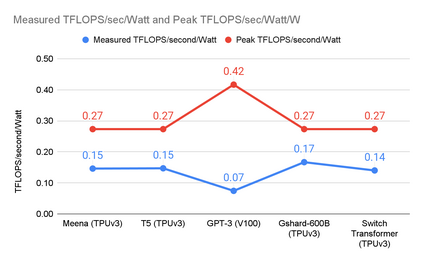
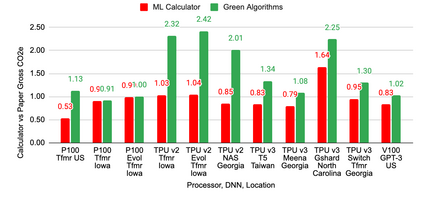
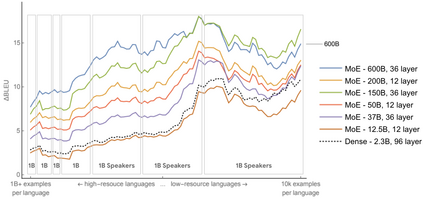
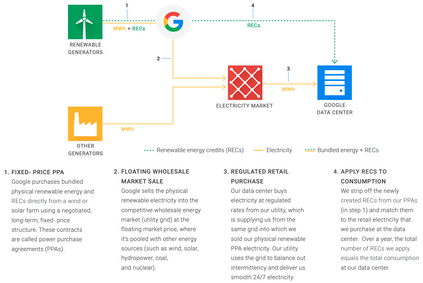
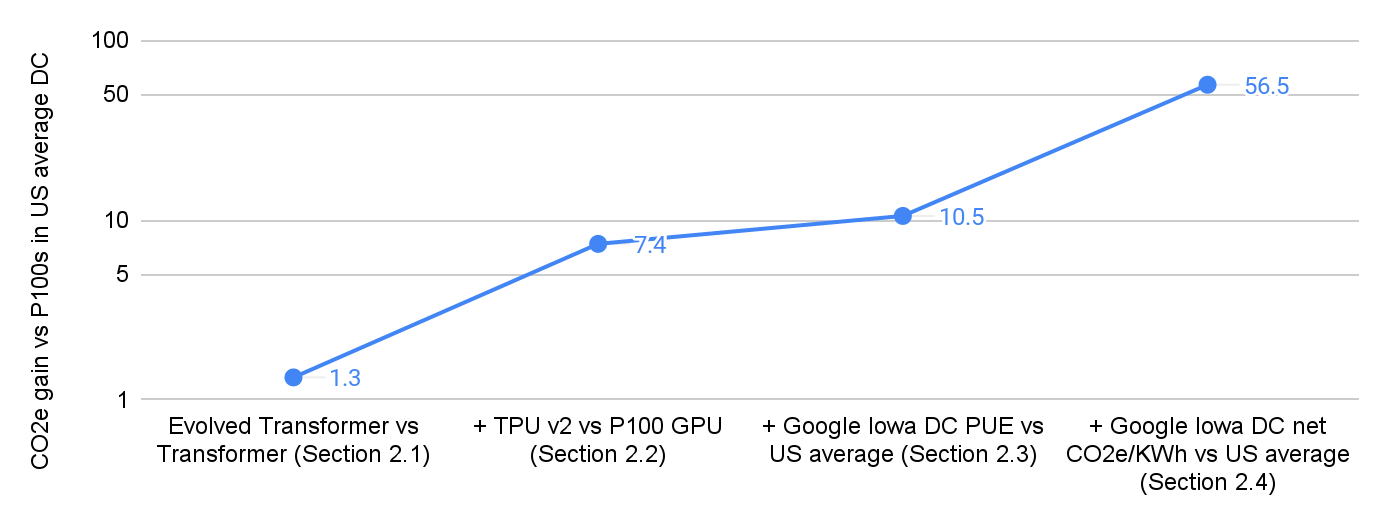
The computation demand for machine learning (ML) has grown rapidly recently, which comes with a number of costs. Estimating the energy cost helps measure its environmental impact and finding greener strategies, yet it is challenging without detailed information. We calculate the energy use and carbon footprint of several recent large models-T5, Meena, GShard, Switch Transformer, and GPT-3-and refine earlier estimates for the neural architecture search that found Evolved Transformer. We highlight the following opportunities to improve energy efficiency and CO2 equivalent emissions (CO2e): Large but sparsely activated DNNs can consume <1/10th the energy of large, dense DNNs without sacrificing accuracy despite using as many or even more parameters. Geographic location matters for ML workload scheduling since the fraction of carbon-free energy and resulting CO2e vary ~5X-10X, even within the same country and the same organization. We are now optimizing where and when large models are trained. Specific datacenter infrastructure matters, as Cloud datacenters can be ~1.4-2X more energy efficient than typical datacenters, and the ML-oriented accelerators inside them can be ~2-5X more effective than off-the-shelf systems. Remarkably, the choice of DNN, datacenter, and processor can reduce the carbon footprint up to ~100-1000X. These large factors also make retroactive estimates of energy cost difficult. To avoid miscalculations, we believe ML papers requiring large computational resources should make energy consumption and CO2e explicit when practical. We are working to be more transparent about energy use and CO2e in our future research. To help reduce the carbon footprint of ML, we believe energy usage and CO2e should be a key metric in evaluating models, and we are collaborating with MLPerf developers to include energy usage during training and inference in this industry standard benchmark.
翻译:对机器学习(ML)的计算需求最近迅速增长,这带来了一些成本。估计能源成本有助于测量其环境影响和寻找绿色战略,但缺乏详细信息,却具有挑战性。我们计算了最近若干大型模型-T5、米纳、Gashard、开关变换器和GPT-3的能源使用和碳足迹,并改进了发现变异变异变异器的神经结构搜索的早期估计。我们强调提高能源效率和二氧化碳当量排放(CO2)的以下机会:高但启动的DNN能够消耗大而密集的DNNN的能量,尽管使用了如此多甚至更多的参数,但不会降低准确性。我们计算MNNNN值的工作量,因为无碳能源的分量,即使在同一国家和同一组织内部,导致CO2值变化变异异变。我们现在正在优化大型模型的位置和在培训时,将大型模型纳入其中。具体的数据中心基础设施可以降低我们的能源效率,因为我们云化数据中心和CO2的精确性能效率比典型的数据中心要高,而ML为今后需要大量的NE-NE-NE值的能源成本的计算,在它们内部进行大量的计算中可以降低能源成本的能源成本的计算。