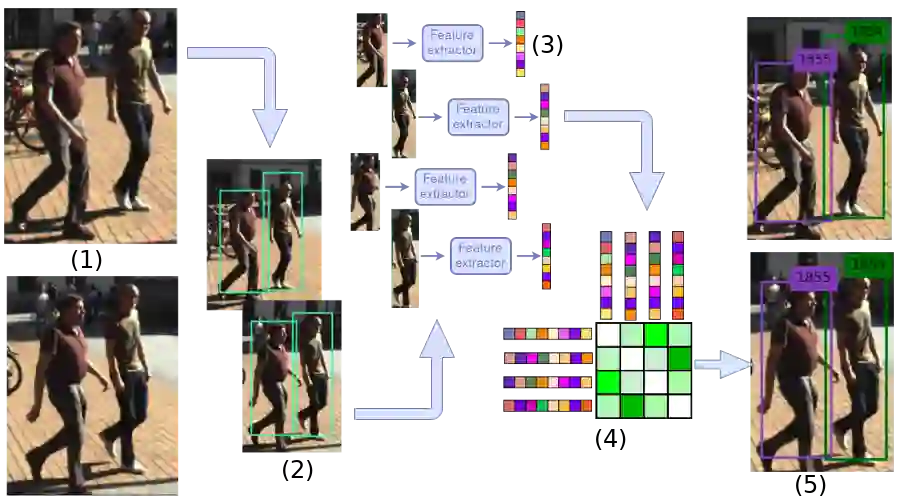
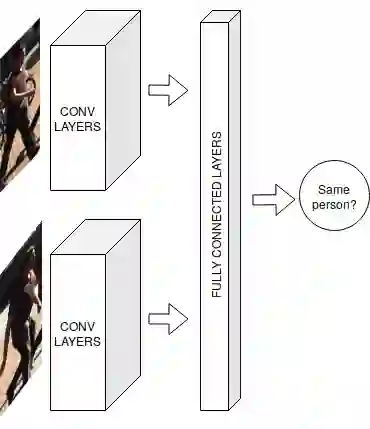
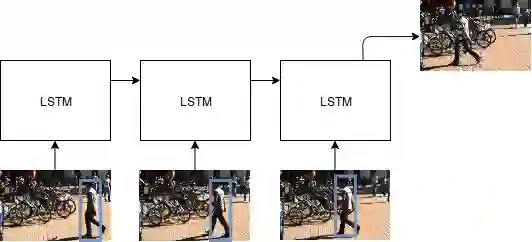
The problem of Multiple Object Tracking (MOT) consists in following the trajectory of different objects in a sequence, usually a video. In recent years, with the rise of Deep Learning, the algorithms that provide a solution to this problem have benefited from the representational power of deep models. This paper provides a comprehensive survey on works that employ Deep Learning models to solve the task of MOT on single-camera videos. Four main steps in MOT algorithms are identified, and an in-depth review of how Deep Learning was employed in each one of these stages is presented. A complete experimental comparison of the presented works on the three MOTChallenge datasets is also provided, identifying a number of similarities among the top-performing methods and presenting some possible future research directions.
翻译:多物体跟踪(MOT)问题在于按顺序跟踪不同物体的轨迹,通常是一段视频。近年来,随着深层学习的兴起,为解决这一问题提供解决办法的算法得益于深层模型的代表性力量。本文对利用深层学习模型解决MOT单摄像头任务的工作进行了全面调查。确定了MOT算法的四大步骤,并深入分析了深层学习在其中每个阶段是如何使用的。还提供了对三个MOTChallenge数据集所展示的工程的全面实验性比较,确定了最佳方法之间的一些相似之处,并提出了一些可能的未来研究方向。