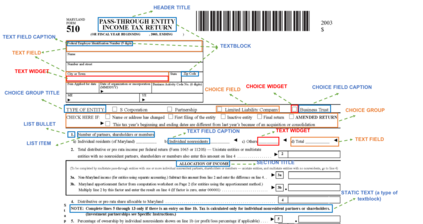
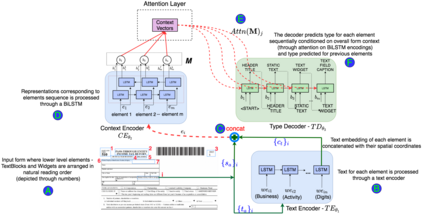
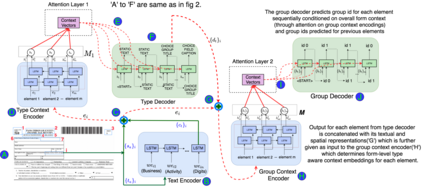
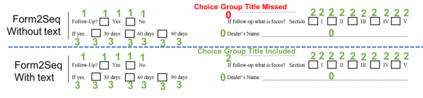
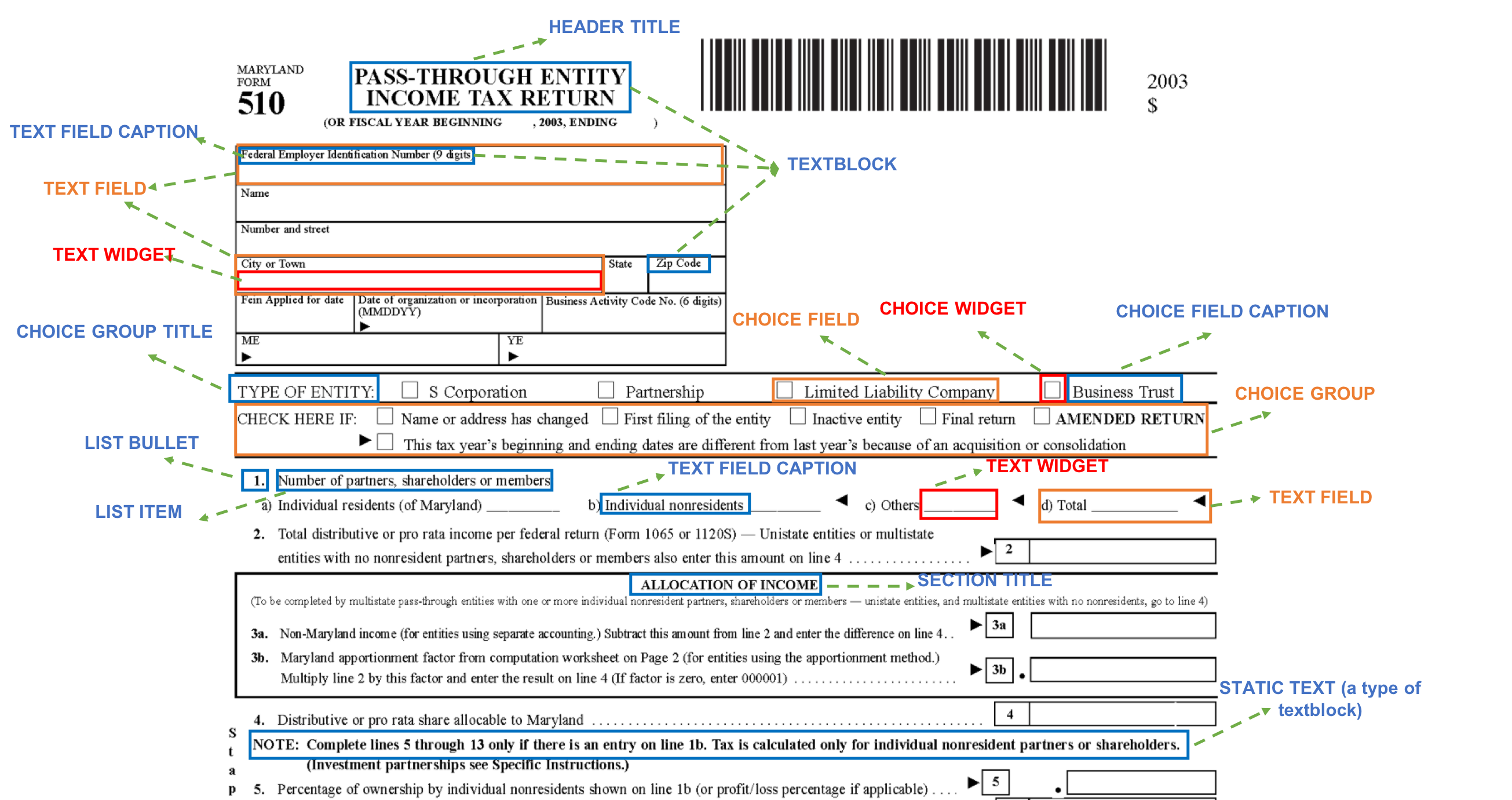
Document structure extraction has been a widely researched area for decades with recent works performing it as a semantic segmentation task over document images using fully-convolution networks. Such methods are limited by image resolution due to which they fail to disambiguate structures in dense regions which appear commonly in forms. To mitigate this, we propose Form2Seq, a novel sequence-to-sequence (Seq2Seq) inspired framework for structure extraction using text, with a specific focus on forms, which leverages relative spatial arrangement of structures. We discuss two tasks; 1) Classification of low-level constituent elements (TextBlock and empty fillable Widget) into ten types such as field captions, list items, and others; 2) Grouping lower-level elements into higher-order constructs, such as Text Fields, ChoiceFields and ChoiceGroups, used as information collection mechanism in forms. To achieve this, we arrange the constituent elements linearly in natural reading order, feed their spatial and textual representations to Seq2Seq framework, which sequentially outputs prediction of each element depending on the final task. We modify Seq2Seq for grouping task and discuss improvements obtained through cascaded end-to-end training of two tasks versus training in isolation. Experimental results show the effectiveness of our text-based approach achieving an accuracy of 90% on classification task and an F1 of 75.82, 86.01, 61.63 on groups discussed above respectively, outperforming segmentation baselines. Further we show our framework achieves state of the results for table structure recognition on ICDAR 2013 dataset.
翻译:数十年来,文档结构提取一直是一个广泛研究的领域,最近的工作是利用全演网络对文档图像进行语义分解任务,使用全演网络对文档图像进行语义分解任务。这些方法受到图像分辨率的限制,因为其无法分解常见形式的稠密区域的结构。为此,我们提议了Form2Seqeq,即一个创新的按顺序排序(Seq2Seq63)的利用文本进行结构提取的框架,其具体重点是利用结构相对空间安排的表格。我们讨论了两个任务:(1) 将低级构成元素(TextBlock和空可填充元)分类为10种类型,如外地说明、列表项目和其他;(2) 将较低级别的元素分组成更高层次结构,如文本字段、选择字段和选择组,作为形式的信息收集机制。为此,我们将结构的构成要素按线性排列为自然阅读顺序,将其基于空间和文字的表达方式提供给Seq2Seq2Seqeq框架,根据最终任务按顺序对每个要素进行输出预测。我们修改Seq2Seq2Sseal2Seqeqealal-lavialalalalalalalalalalal-laview laview laview 工作,我们分别在Sildal 上完成了Slievalal-traal-traal-traal-laview laviewxal 工作, 工作,在Sildal-laview-traal-traal-traal-traal-laview-ladal-ladal-traal-laction-labal-labal-traal-ladal-ladal-ladal-ladal-ladal-labaldal-labal-ladal-ladal-ladaldal-ladal-ladal-ladal-ladal-ladal-ladal-ladal-ladal-lad-lad-ladal-lad-lad-lad-lad-lad-lad-lad-lad-lad-lad-lad-lad-lad-lad-lad-lad-