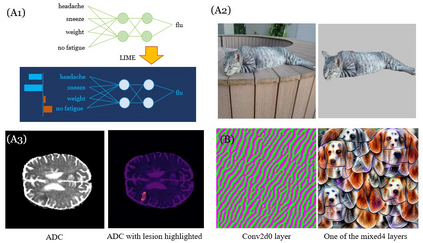
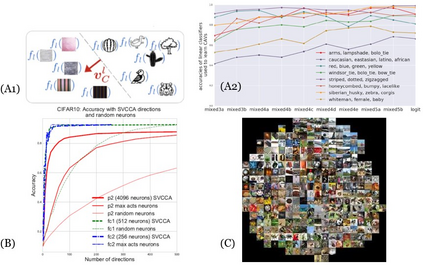
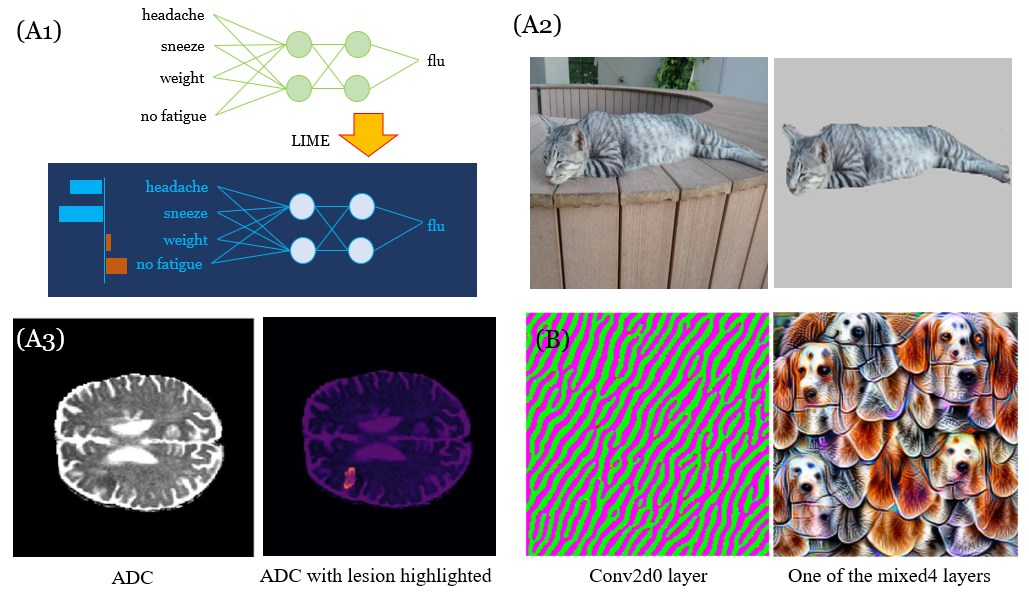
Recently, artificial intelligence, especially machine learning has demonstrated remarkable performances in many tasks, from image processing to natural language processing, especially with the advent of deep learning. Along with research progress, machine learning has encroached into many different fields and disciplines. Some of them, such as the medical field, require high level of accountability, and thus transparency, which means we need to be able to explain machine decisions, predictions and justify their reliability. This requires greater interpretability, which often means we need to understand the mechanism underlying the algorithms. Unfortunately, the black-box nature of the deep learning is still unresolved, and many machine decisions are still poorly understood. We provide a review on interpretabilities suggested by different research works and categorize them. Also, within an exhaustive list of papers, we find that interpretability is often algorithm-centric, with few human-subject tests to verify whether proposed methods indeed enhance human interpretability. We explore further into interpretability in the medical field, illustrating the complexity of interpretability issue.
翻译:最近,人工智能,特别是机器学习,在许多任务,从图像处理到自然语言处理,尤其是随着深层次学习的到来,人工智能在许多任务中表现出显著的成绩。随着研究的进展,机器学习已经侵入了许多不同的领域和学科。其中一些领域,例如医疗领域,需要高度的问责制,从而需要透明度,这意味着我们需要能够解释机器的决定、预测和证明其可靠性。这要求更大的可解释性,这往往意味着我们需要理解算法背后的机制。不幸的是,深层学习的黑盒性质仍然没有解决,许多机器决定仍然不易理解。我们审查了不同研究工程提出的解释性,并将它们分类。此外,在一份详尽的文件清单中,我们发现可解释性往往以算法为中心,只有很少的人类实验可以核实拟议方法是否确实加强了人类的可解释性。我们进一步探索医学领域的可解释性,说明可解释性问题的复杂性。