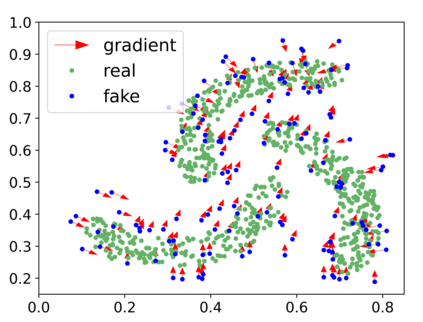
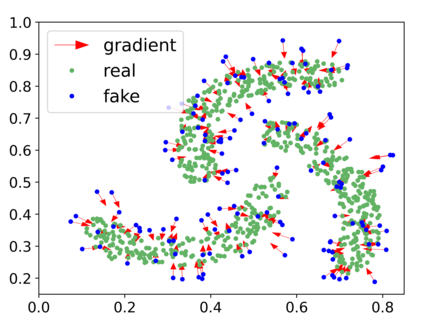
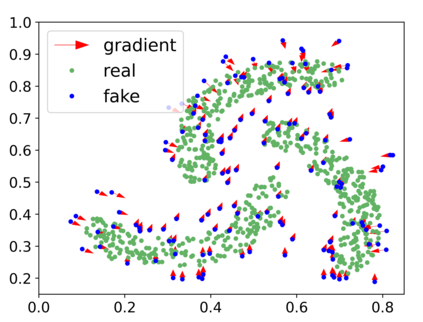
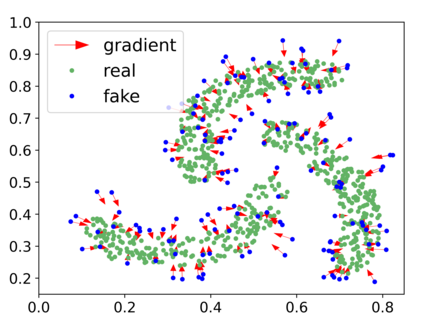
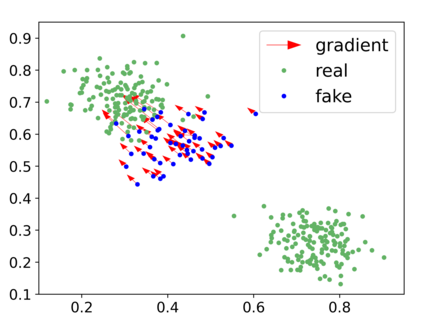
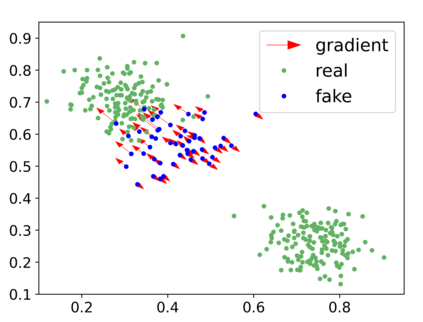
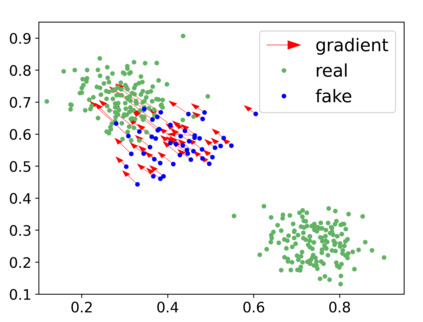
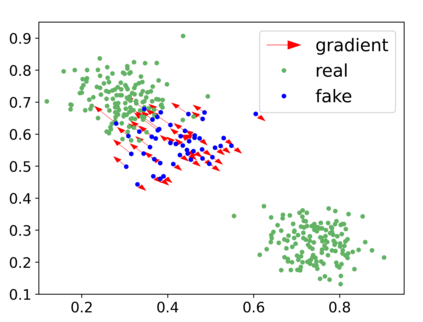
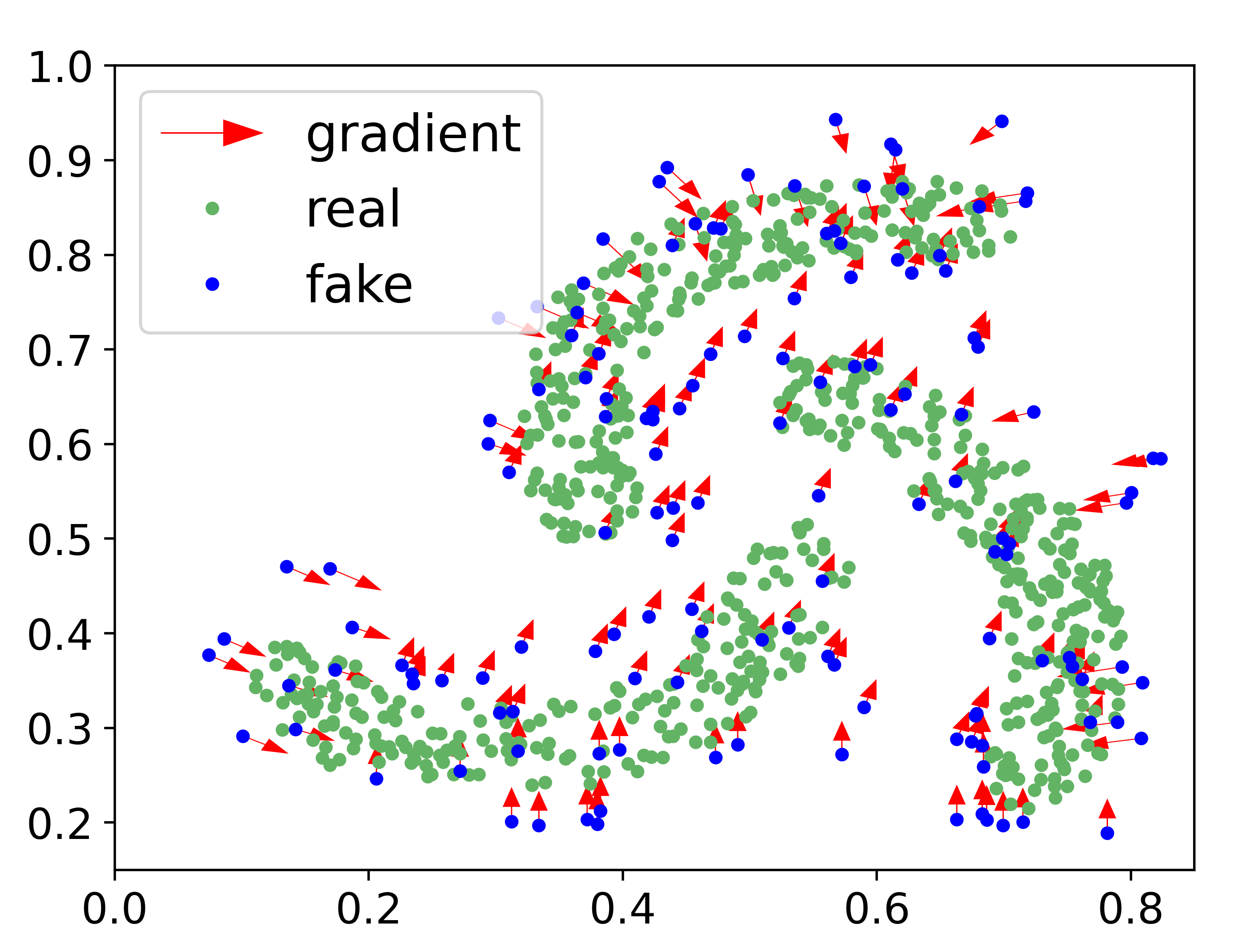
Generative adversarial networks (GANs) have achieved rapid progress in learning rich data distributions. However, we argue about two main issues in existing techniques. First, the low quality problem where the learned distribution has massive low quality samples. Second, the missing modes problem where the learned distribution misses some certain regions of the real data distribution. To address these two issues, we propose a novel prior that captures the whole real data distribution for GANs, which are called PriorGANs. To be specific, we adopt a simple yet elegant Gaussian Mixture Model (GMM) to build an explicit probability distribution on the feature level for the whole real data. By maximizing the probability of generated data, we can push the low quality samples to high quality. Meanwhile, equipped with the prior, we can estimate the missing modes in the learned distribution and design a sampling strategy on the real data to solve the problem. The proposed real data prior can generalize to various training settings of GANs, such as LSGAN, WGAN-GP, SNGAN, and even the StyleGAN. Our experiments demonstrate that PriorGANs outperform the state-of-the-art on the CIFAR-10, FFHQ, LSUN-cat, and LSUN-bird datasets by large margins.
翻译:创世的对抗网络(GANs)在学习丰富的数据分布方面取得了迅速的进展。然而,我们争论了现有技术中的两个主要问题:第一,知识分布质量低的问题,质量低的问题,质量低的问题,质量低的问题,质量低的问题,质量低的问题,质量差的模式问题,实际数据分布的某些区域,实际数据分布不足的问题。为了解决这两个问题,我们提出了一个新颖的前题,将GANs(称为PrecialGANs)的全部真实数据分布记录起来。具体地说,我们采用了简单而优雅的Gossian Mixture模型(GMMM),以建立整个真实数据特征水平的明显概率分布。通过最大限度地增加生成数据的概率,我们可以将低质量的样本推到高质量。与此同时,我们装备了前题,可以估计在知识分布中缺失的模式,并设计出一个真正数据解决问题的抽样战略。拟议的真实数据可以概括到GANs的各种培训环境,如LSGAN、WGAN-GP、SNGANAN,甚至SyleGAN。我们的实验表明,前GANANANs(L-AANAS-GAR-GAR-FAS-GAR-A-A-FAR-A-MS-GAR-GM-GM-GM-LAFAR-L-I-MAS-I-I)在大型数据中,L-FAS-FAS-FAS-M-L-I-FAS-M-L-I-I-FAS-FAS-FAS-FAS-L-FAS-L-FAS-FAS-FAS-L-FAS-FAS-M-L-FAS-L-FAS-GAS-FAS-FAS-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-I-IAS-IAS-I-IAS-IAS-IAS-I-I-I-I-I-I-I-I-I-IAS-IAS-IAS-IAS-IAS-IAS-I-I-I-IAS-IAS-IAS-I-I-I