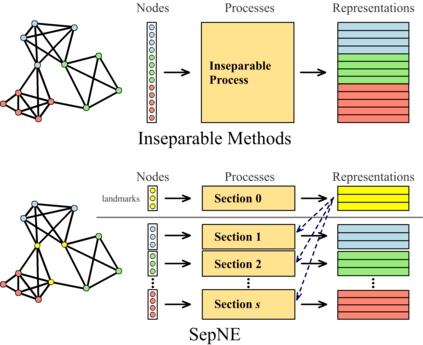
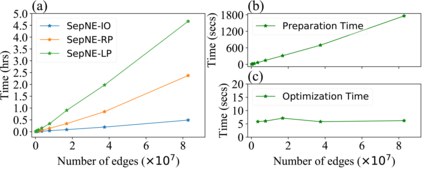
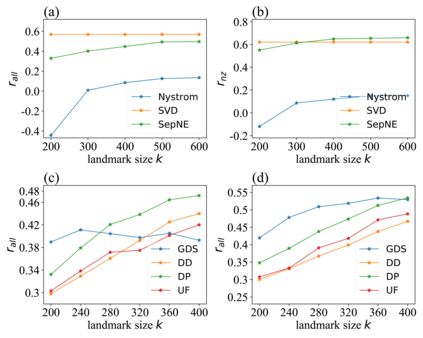
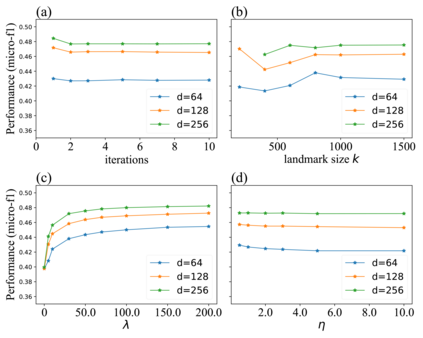
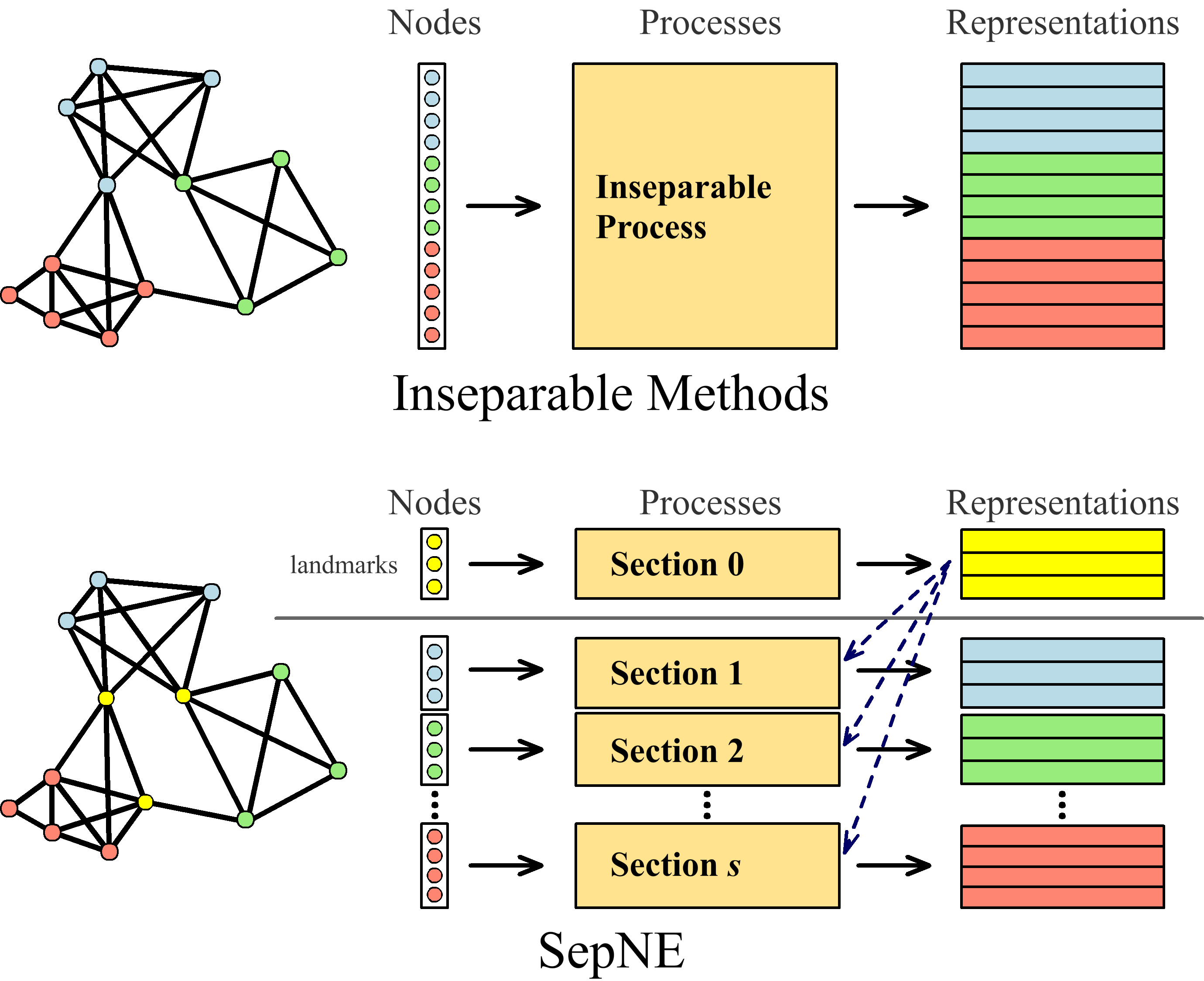
Many successful methods have been proposed for learning low dimensional representations on large-scale networks, while almost all existing methods are designed in inseparable processes, learning embeddings for entire networks even when only a small proportion of nodes are of interest. This leads to great inconvenience, especially on super-large or dynamic networks, where these methods become almost impossible to implement. In this paper, we formalize the problem of separated matrix factorization, based on which we elaborate a novel objective function that preserves both local and global information. We further propose SepNE, a simple and flexible network embedding algorithm which independently learns representations for different subsets of nodes in separated processes. By implementing separability, our algorithm reduces the redundant efforts to embed irrelevant nodes, yielding scalability to super-large networks, automatic implementation in distributed learning and further adaptations. We demonstrate the effectiveness of this approach on several real-world networks with different scales and subjects. With comparable accuracy, our approach significantly outperforms state-of-the-art baselines in running times on large networks.
翻译:在大型网络中,提出了许多成功的方法来学习低维度的表达方式,而几乎所有现有方法都是在不可分割的进程中设计的,学习整个网络的嵌入,即使只有一小部分节点值得关注。这导致极大的不便,特别是在超级大或动态网络中,这些方法几乎无法实施。在本文件中,我们正式确定了分离矩阵因子化问题,在此基础上,我们拟订了一个保存当地和全球信息的新的目标功能。我们进一步提议SepNe,这是一个简单而灵活的网络嵌入算法,它独立地学习不同节点子在分离过程中的表达方式。通过实施分离,我们的算法减少了将无关节点嵌入的冗余努力,使超大网络具有可扩缩性,在分布式学习和进一步调整中自动实施。我们用不同规模和主题来证明这个方法在几个真实世界网络中的有效性。我们的方法具有类似的准确性,大大超出大型网络运行时的先进基线。