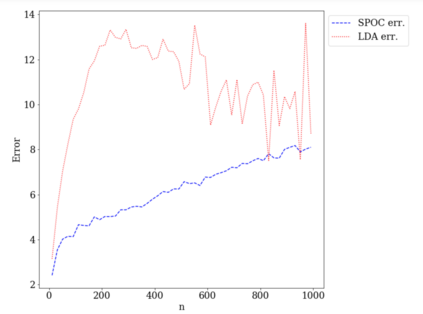
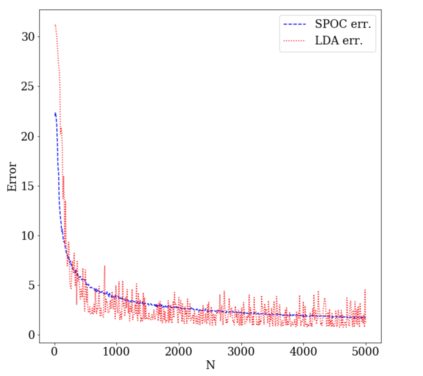
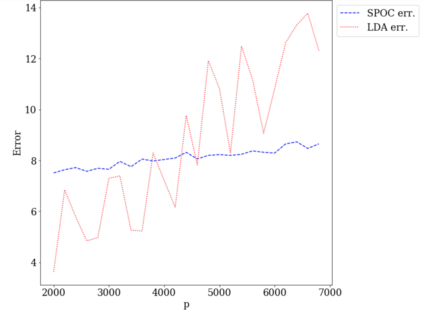
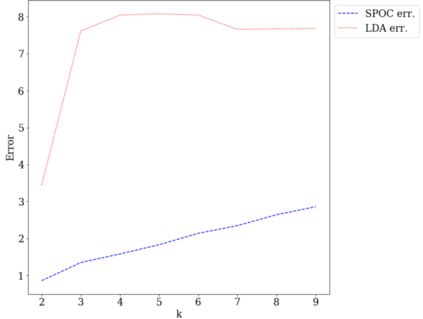
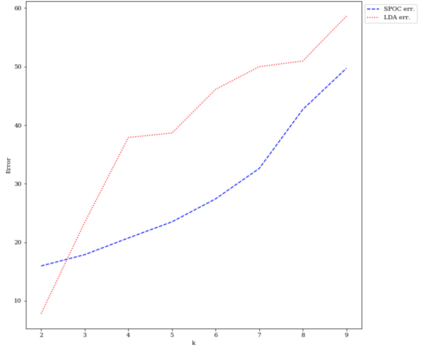
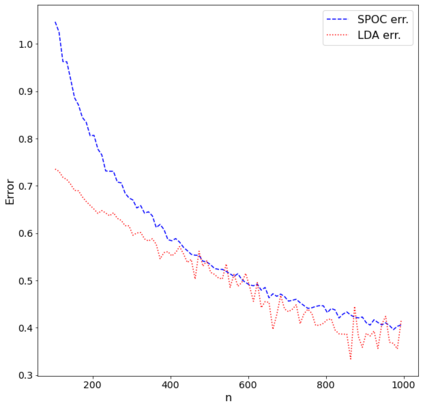
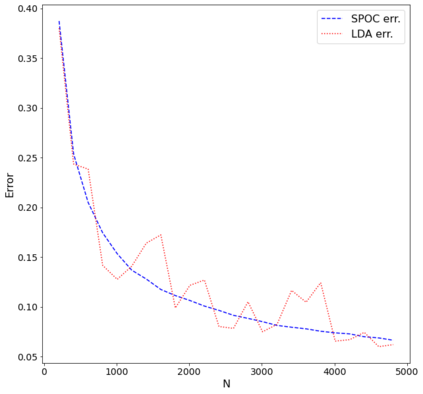
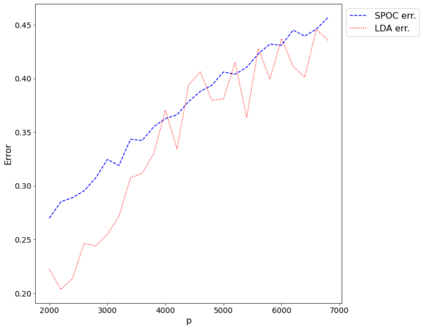
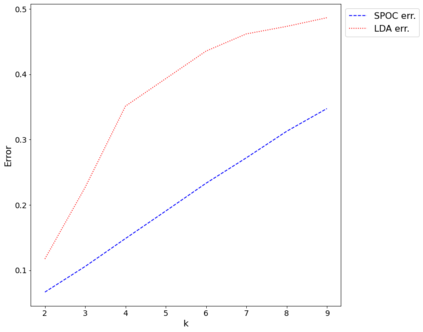
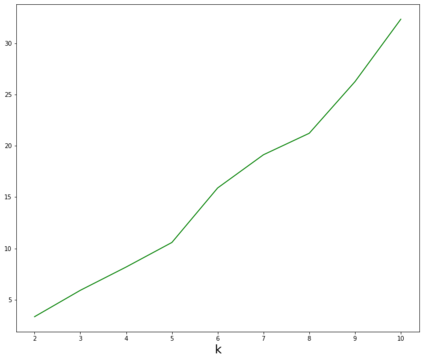
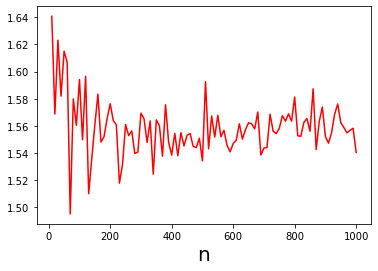
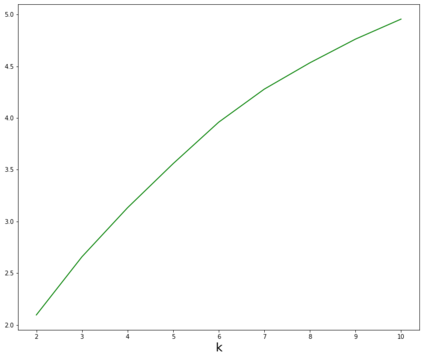
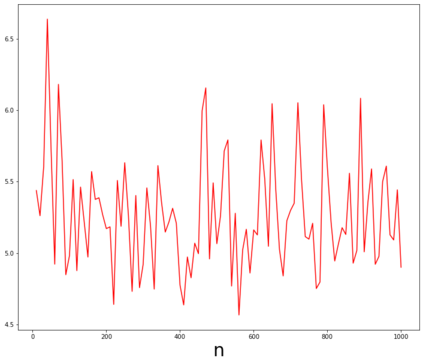
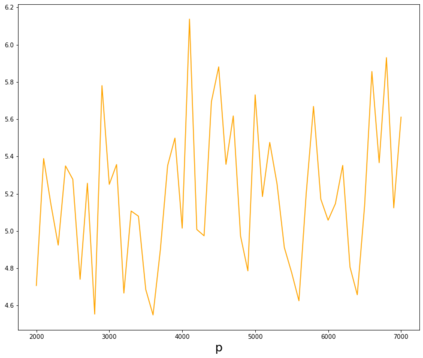
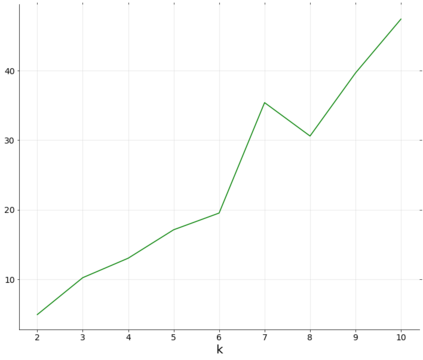
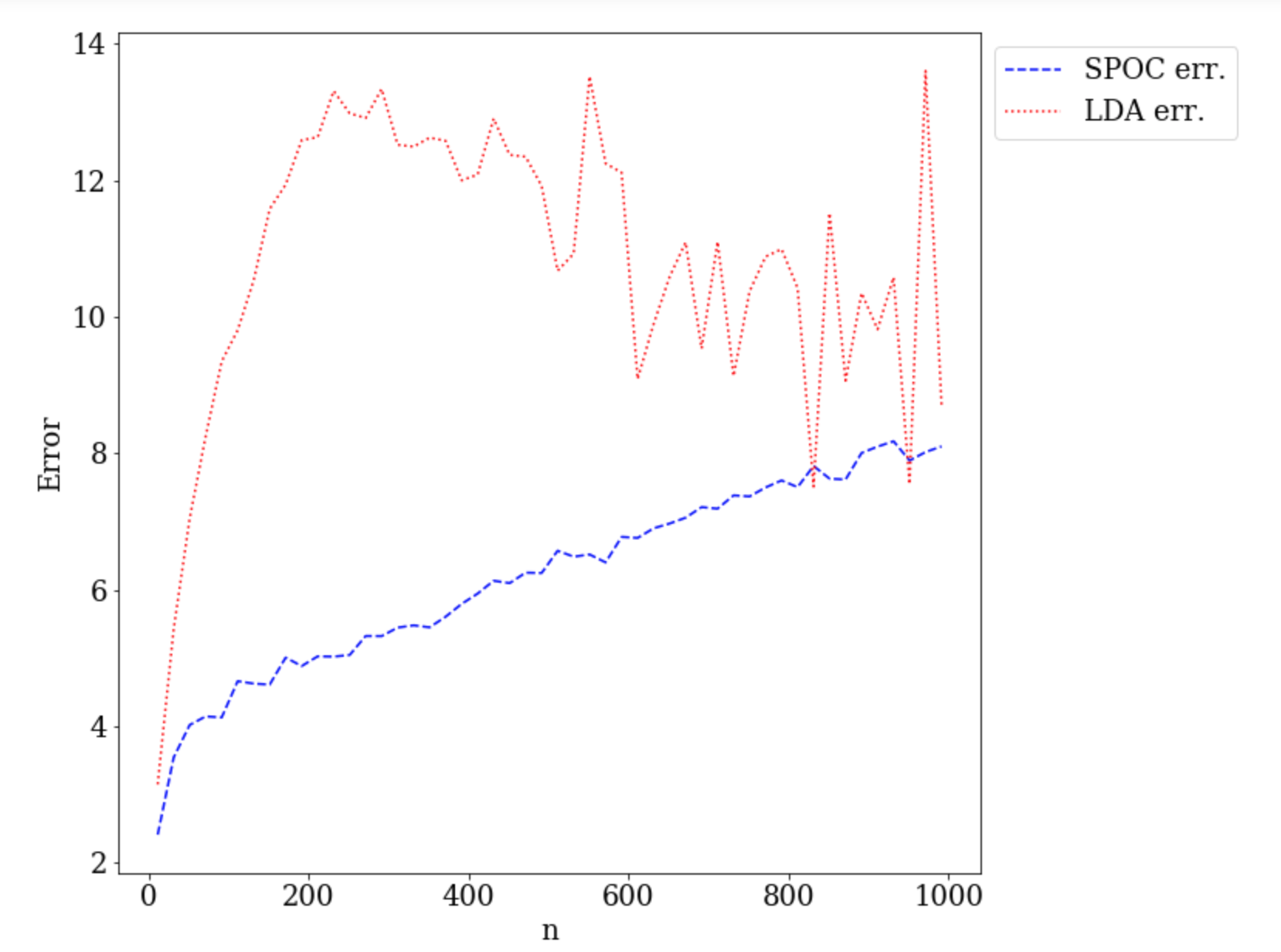
Topic models provide a useful tool to organize and understand the structure of large corpora of text documents, in particular, to discover hidden thematic structure. Clustering documents from big unstructured corpora into topics is an important task in various areas, such as image analysis, e-commerce, social networks, population genetics. A common approach to topic modeling is to associate each topic with a probability distribution on the dictionary of words and to consider each document as a mixture of topics. Since the number of topics is typically substantially smaller than the size of the corpus and of the dictionary, the methods of topic modeling can lead to a dramatic dimension reduction. In this paper, we study the problem of estimating topics distribution for each document in the given corpus, that is, we focus on the clustering aspect of the problem. We introduce an algorithm that we call Successive Projection Overlapping Clustering (SPOC) inspired by the Successive Projection Algorithm for separable matrix factorization. This algorithm is simple to implement and computationally fast. We establish theoretical guarantees on the performance of the SPOC algorithm, in particular, near matching minimax upper and lower bounds on its estimation risk. We also propose a new method that estimates the number of topics. We complement our theoretical results with a numerical study on synthetic and semi-synthetic data to analyze the performance of this new algorithm in practice. One of the conclusions is that the error of the algorithm grows at most logarithmically with the size of the dictionary, in contrast to what one observes for Latent Dirichlet Allocation.
翻译:主题模型提供了一个有用的工具,以组织和理解大量文本文件整体结构的结构,特别是发现隐藏的专题结构。将大型非结构化公司的文件分组为主题,是各个领域的重要任务,如图像分析、电子商务、社交网络、人口基因学。主题模型的共同方法是将每个专题与单词字典上的概率分布联系起来,并将每个文件视为一个专题的组合。由于专题的数量通常大大小于本体和字典的大小,专题模型方法可以导致显著的尺寸缩减。在本文件中,我们研究对每个特定内容中每个文件的过时大小分布进行估算的问题,也就是说,我们侧重于问题的组群方面。我们采用一种算法,我们称之为 " 成功项目重叠组合(SPOC) ",在词典词典的词典中将每个专题的概率分布视为一个混合的矩阵因素组合。这种算法比较简单易执行,而且计算得很快。我们为新的SPOC算法的性能建立了理论保证,特别是接近缩略式的上和下限的大小。我们用一种算法来估算其数值的数值,我们用新的算法来计算。我们用一个数字分析方法来计算。我们用一个数字来计算。