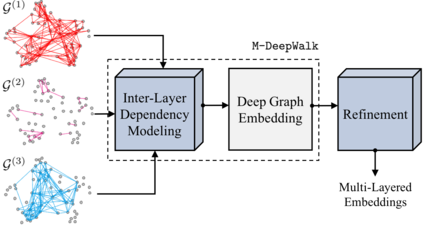
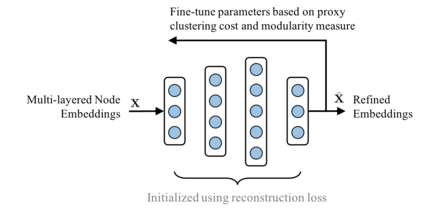
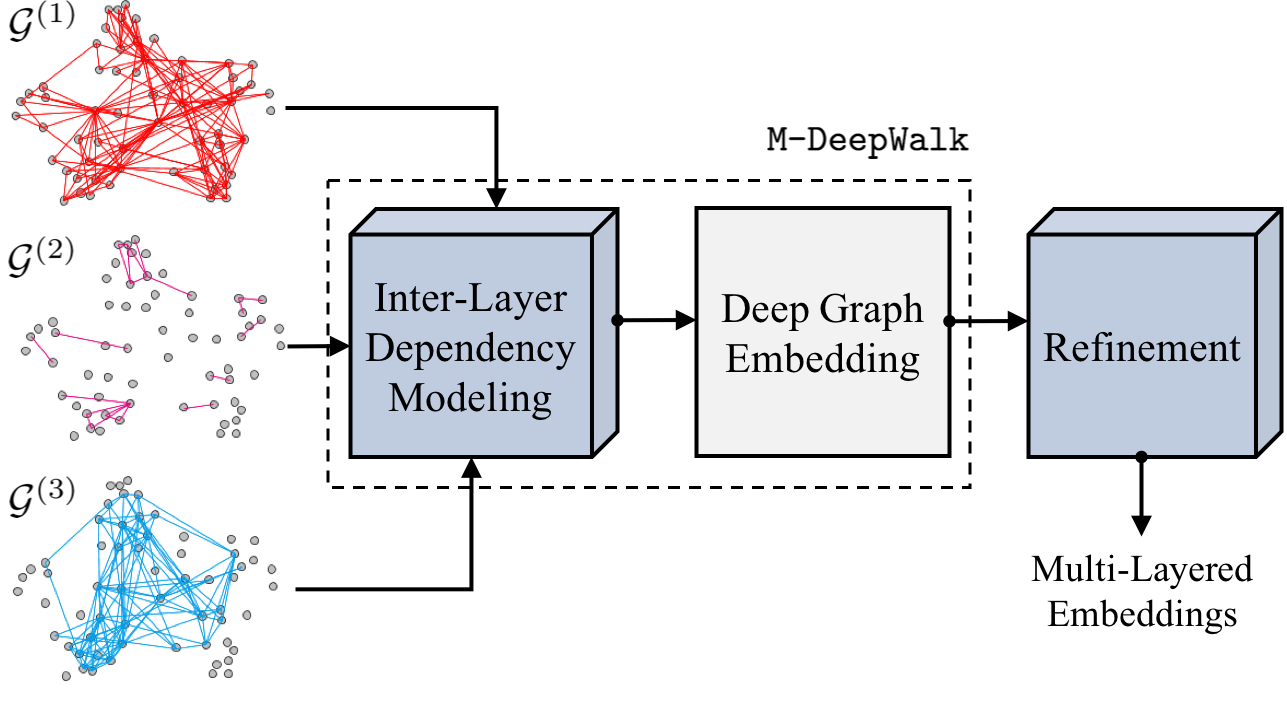
Inferencing with network data necessitates the mapping of its nodes into a vector space, where the relationships are preserved. However, with multi-layered networks, where multiple types of relationships exist for the same set of nodes, it is crucial to exploit the information shared between layers, in addition to the distinct aspects of each layer. In this paper, we propose a novel approach that first obtains node embeddings in all layers jointly via DeepWalk on a \textit{supra} graph, which allows interactions between layers, and then fine-tunes the embeddings to encourage cohesive structure in the latent space. With empirical studies in node classification, link prediction and multi-layered community detection, we show that the proposed approach outperforms existing single- and multi-layered network embedding algorithms on several benchmarks. In addition to effectively scaling to a large number of layers (tested up to $37$), our approach consistently produces highly modular community structure, even when compared to methods that directly optimize for the modularity function.
翻译:根据网络数据推断,有必要将其节点映射成矢量空间,从而保持关系。然而,在多层网络中,对于同一节点组存在多种类型的关系,除了每个节点的不同方面外,利用各层之间共享的信息至关重要。在本文件中,我们提议了一种新颖的方法,首先通过DeepWalk在“DeepWalk”图上通过“DeepWalk”在所有层次上共同获得节点嵌入,从而允许各层之间互动,然后微调嵌入,以鼓励在潜在空间中建立一致的结构。在节点分类、连接预测和多层社区探测方面的实证研究中,我们显示,拟议的方法优于几个基准上的现有单层和多层网络算法。除了有效地扩大到大量层(测试达到370美元)外,我们的方法始终产生高度模块化的社区结构,即使与直接优化模块功能的方法相比较。