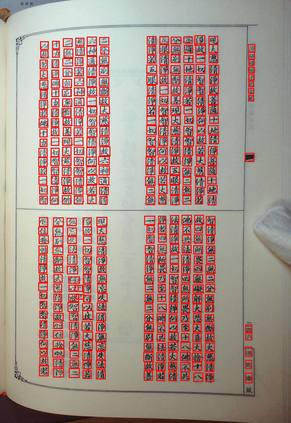
The information provided by historical documents has always been indispensable in the transmission of human civilization, but it has also made these books susceptible to damage due to various factors. Thanks to recent technology, the automatic digitization of these documents are one of the quickest and most effective means of preservation. The main steps of automatic text digitization can be divided into two stages, mainly: character segmentation and character recognition, where the recognition results depend largely on the accuracy of segmentation. Therefore, in this study, we will only focus on the character segmentation of historical Chinese documents. In this research, we propose a model named HRCenterNet, which is combined with an anchorless object detection method and parallelized architecture. The MTHv2 dataset consists of over 3000 Chinese historical document images and over 1 million individual Chinese characters; with these enormous data, the segmentation capability of our model achieves IoU 0.81 on average with the best speed-accuracy trade-off compared to the others. Our source code is available at https://github.com/Tverous/HRCenterNet.
翻译:历史文献提供的信息在人类文明的传播中一直不可或缺,但也使这些书籍容易因各种因素而受到损害。由于最近的技术,这些文件的自动数字化是最迅速和最有效的保存手段之一。自动文本数字化的主要步骤可以分为两个阶段,主要是:字符分割和字符识别,其识别结果主要取决于分解的准确性。因此,在本研究中,我们只关注中国历史文献的特性分割。在这项研究中,我们提出了一个名为HRCenterNet的模型,该模型与无固定物体探测方法和平行结构相结合。MTHV2数据集由3,000多张中国历史文件图像和100多万中国个人字符组成;有了这些巨大的数据,我们模型的分解能力平均达到IOU 0.81,其速度-准确性交易与其它文件相比达到最佳程度。我们的源代码可在https://github.com/Tverog/HRCentNet上查阅。