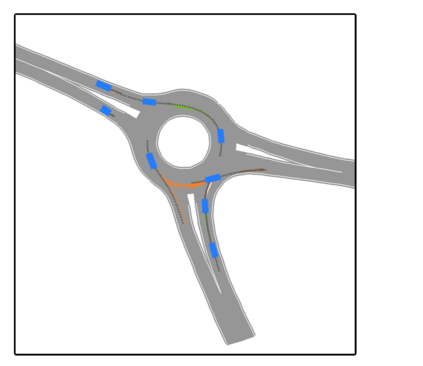
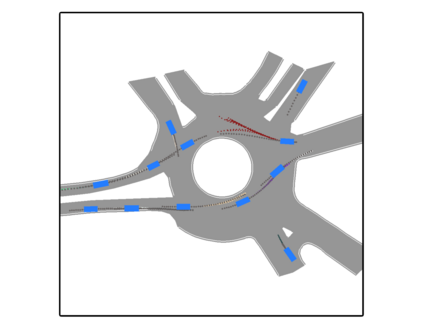
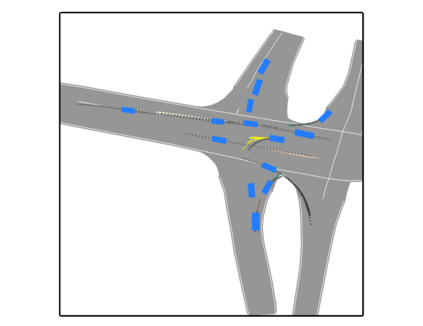
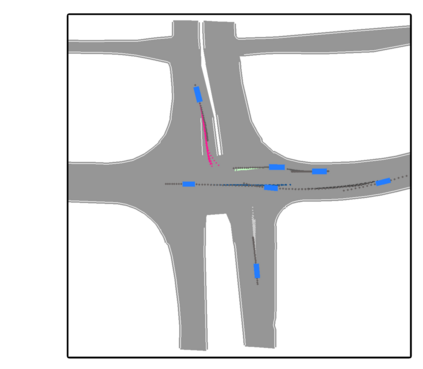
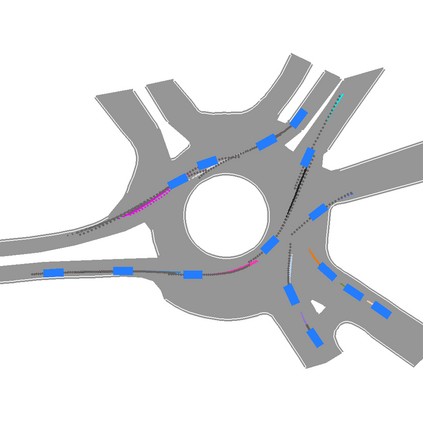
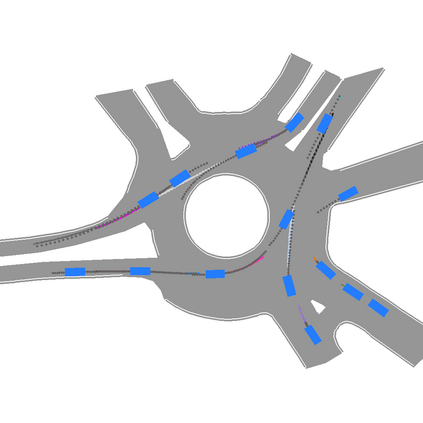
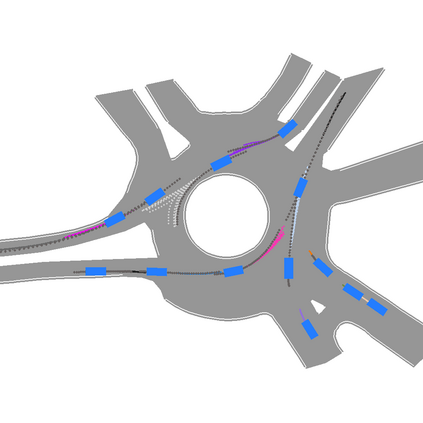
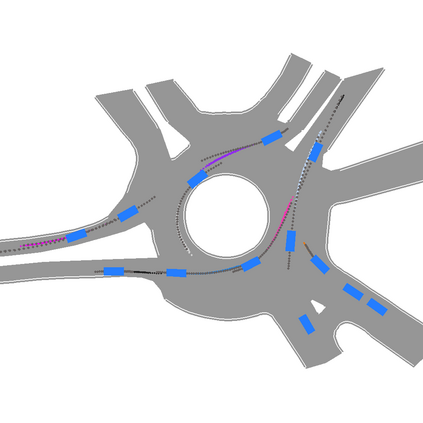
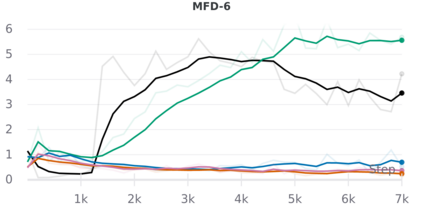
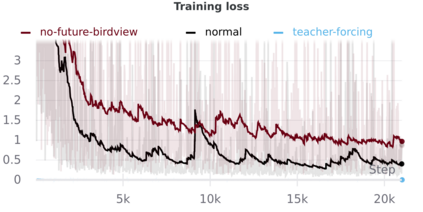
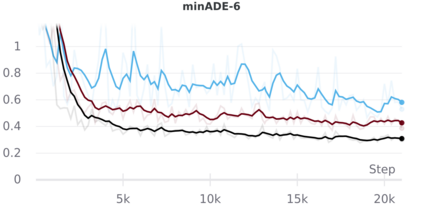
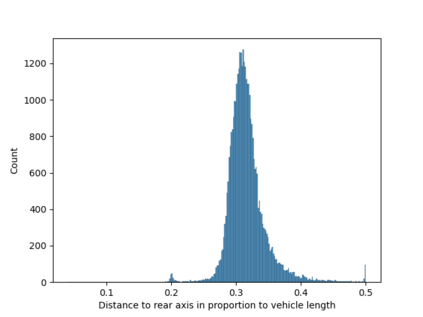
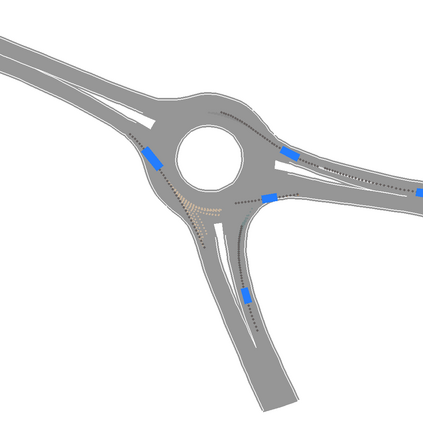
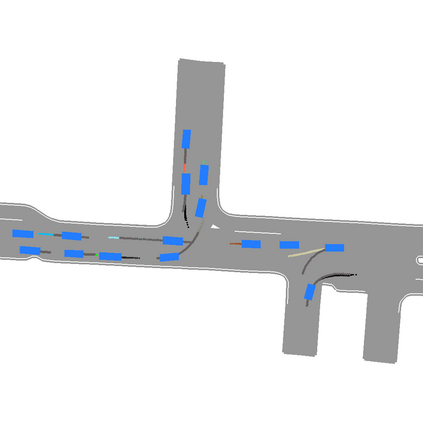
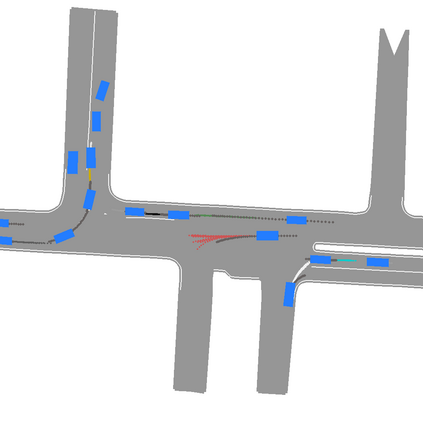
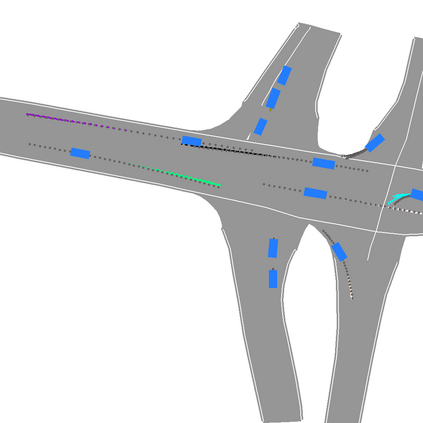
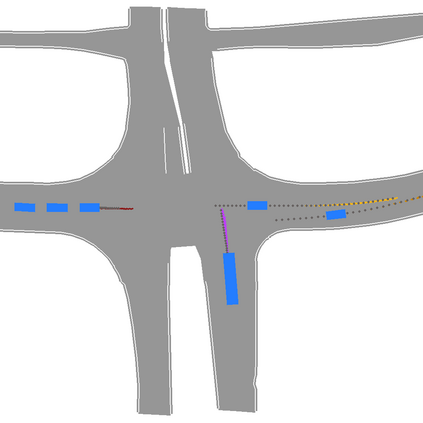
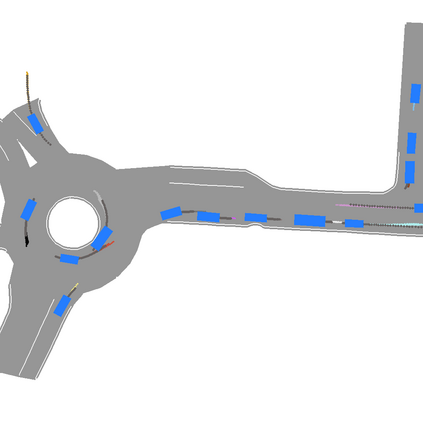
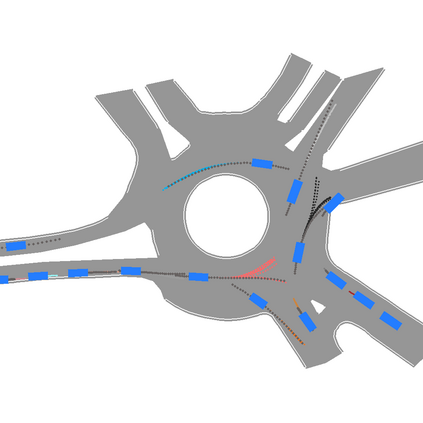
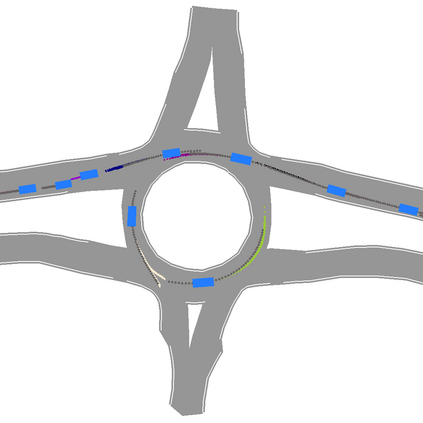
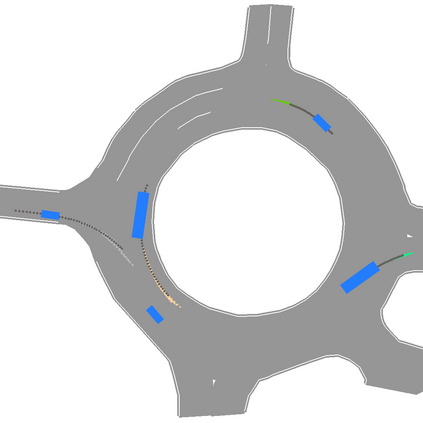
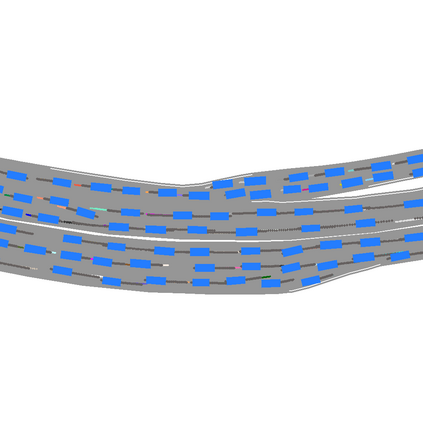
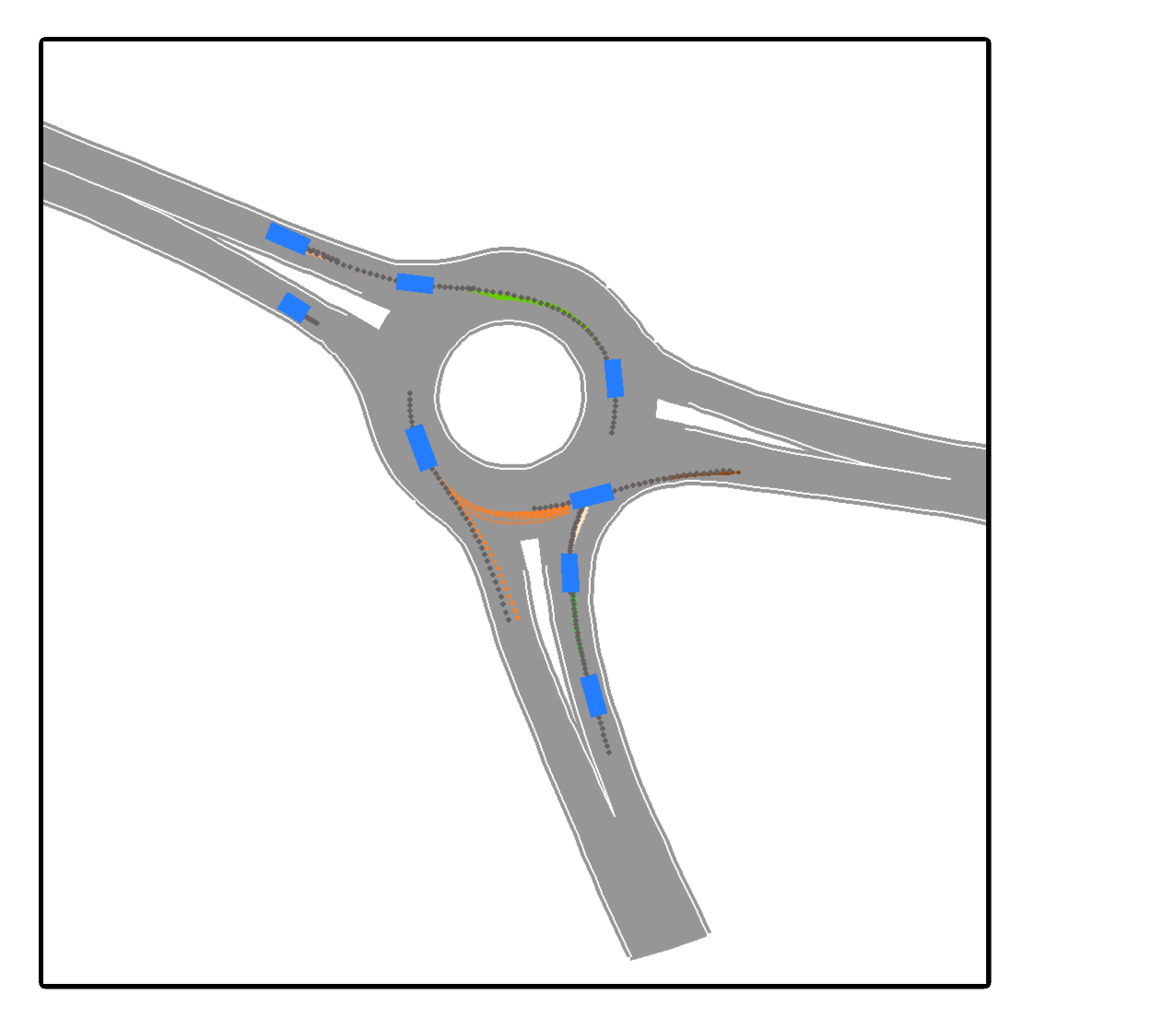
We develop a deep generative model built on a fully differentiable simulator for multi-agent trajectory prediction. Agents are modeled with conditional recurrent variational neural networks (CVRNNs), which take as input an ego-centric birdview image representing the current state of the world and output an action, consisting of steering and acceleration, which is used to derive the subsequent agent state using a kinematic bicycle model. The full simulation state is then differentiably rendered for each agent, initiating the next time step. We achieve state-of-the-art results on the INTERACTION dataset, using standard neural architectures and a standard variational training objective, producing realistic multi-modal predictions without any ad-hoc diversity-inducing losses. We conduct ablation studies to examine individual components of the simulator, finding that both the kinematic bicycle model and the continuous feedback from the birdview image are crucial for achieving this level of performance. We name our model ITRA, for "Imagining the Road Ahead".
翻译:我们开发了一个基于完全不同的多试剂轨迹预测模拟器的深重基因模型。代理器以有条件的重复变异神经网络(CVRNNSs)为模型,以代表世界现状的以自我为中心的鸟类图像作为输入,并产生一个由方向和加速组成的动作,用于利用运动自行车模型来得出随后的代理状态。然后,对每个代理器进行全面模拟,然后开始下一个步骤。我们利用标准的神经结构和标准变异培训目标,实现interACTION数据集的最先进的结果,产生现实的多模式预测,而不会造成任何刺激多样性的损失。我们进行调节研究,以检查模拟器的各个组成部分,发现运动自行车模型和鸟视图像的持续反馈对于达到这一水平至关重要。我们用“模拟路头”命名我们的模型ITRA。