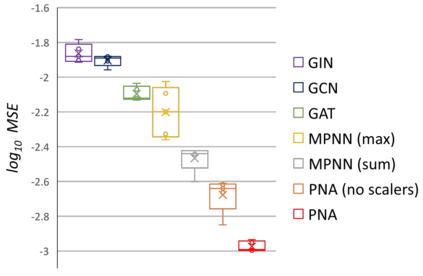
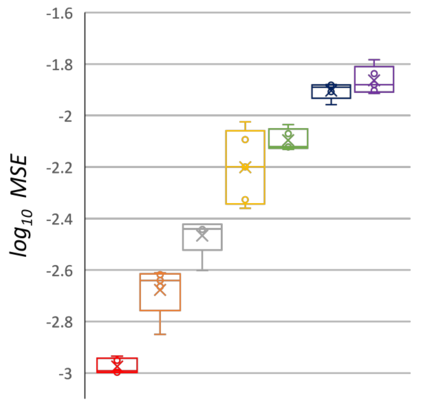
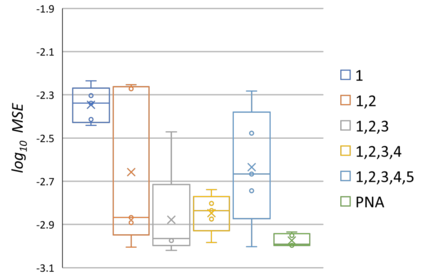
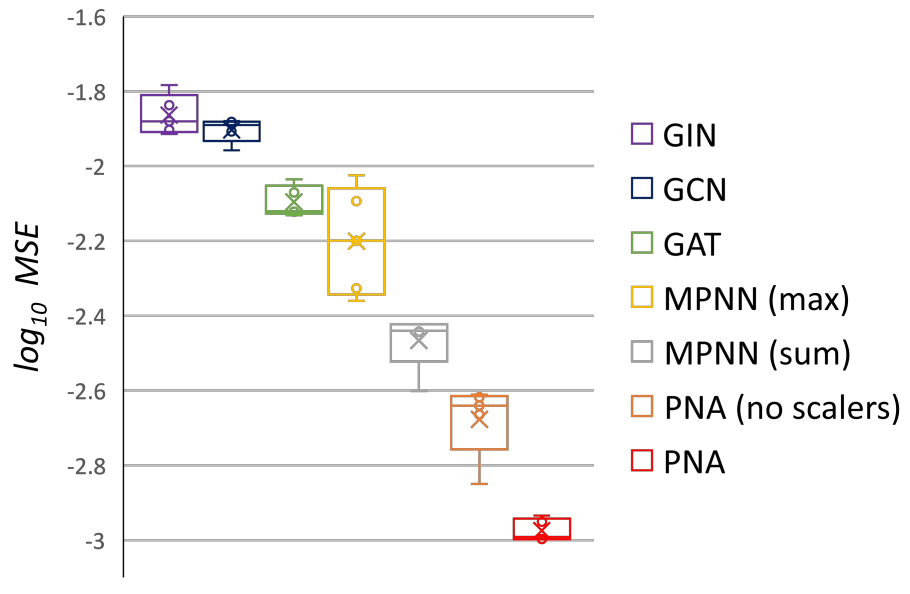
Graph Neural Networks (GNNs) have been shown to be effective models for different predictive tasks on graph-structured data. Recent work on their expressive power has focused on isomorphism tasks and countable feature spaces. We extend this theoretical framework to include continuous features - which occur regularly in real-world input domains and within the hidden layers of GNNs - and we demonstrate the requirement for multiple aggregation functions in this context. Accordingly, we propose Principal Neighbourhood Aggregation (PNA), a novel architecture combining multiple aggregators with degree-scalers (which generalize the sum aggregator). Finally, we compare the capacity of different models to capture and exploit the graph structure via a novel benchmark containing multiple tasks taken from classical graph theory, alongside existing benchmarks from real-world domains, all of which demonstrate the strength of our model. With this work, we hope to steer some of the GNN research towards new aggregation methods which we believe are essential in the search for powerful and robust models.
翻译:图表神经网络(GNNs)已被证明是图表结构数据不同预测任务的有效模型。最近关于其表达力的工作侧重于异形任务和可计量的特征空间。我们扩展了这一理论框架,以包括连续特征,这些特征经常出现在现实世界输入领域和隐藏的GNNs隐藏层中,我们在此背景下展示了多重聚合功能的要求。因此,我们提议了“社区聚合”(PNA),这是一个将多个聚合器与学位标尺器相结合的新结构(该结构将总和聚合器加以概括化 ) 。 最后,我们比较了不同模型通过包含古典图形理论的多重任务的新颖基准来捕捉和利用图形结构的能力,以及现实世界域的现有基准,所有这些基准都显示了我们模型的强度。通过这项工作,我们希望将一些GNN研究引向新的聚合方法,我们认为这些方法对于寻找强大和强大的模型至关重要。