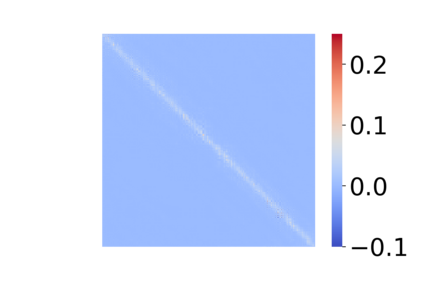
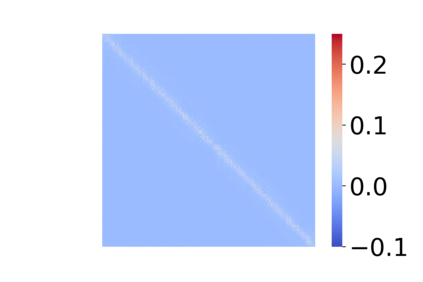
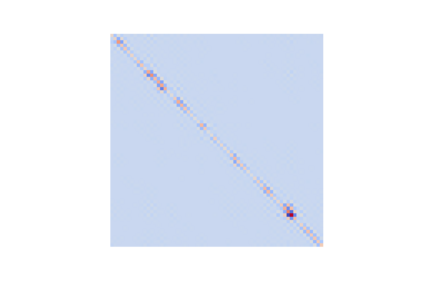
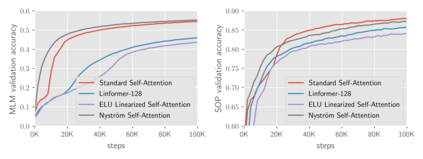
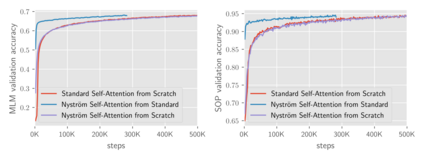
Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the input sequence length has limited its application to longer sequences -- a topic being actively studied in the community. To address this limitation, we propose Nystr\"{o}mformer -- a model that exhibits favorable scalability as a function of sequence length. Our idea is based on adapting the Nystr\"{o}m method to approximate standard self-attention with $O(n)$ complexity. The scalability of Nystr\"{o}mformer enables application to longer sequences with thousands of tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard sequence length, and find that our Nystr\"{o}mformer performs comparably, or in a few cases, even slightly better, than standard self-attention. On longer sequence tasks in the Long Range Arena (LRA) benchmark, Nystr\"{o}mformer performs favorably relative to other efficient self-attention methods. Our code is available at https://github.com/mlpen/Nystromformer.
翻译:变换器已经成为一种强大的工具, 用于一系列广泛的自然语言处理任务。 驱动变换器令人印象深刻业绩的一个关键部分是将其他象征在每种特定象征上的影响或依赖性编码的自我注意机制。 虽然有益, 但输入序列长度上的自我注意的二次复杂性使输入序列长度的应用限制在更长的顺序上 -- 一个正在社区积极研究的专题。 为了解决这个问题, 我们提议 Nystr\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\