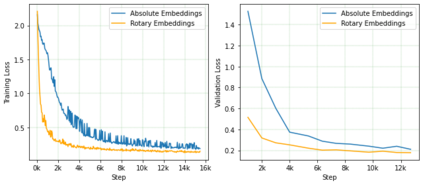
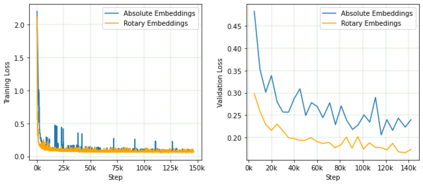
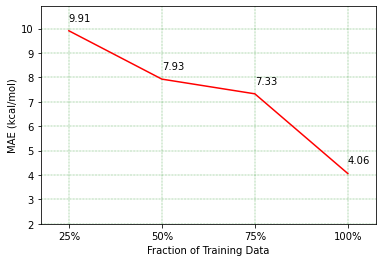
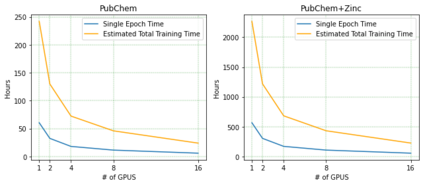
Predicting chemical properties from the structure of a molecule is of great importance in many applications including drug discovery and material design. Machine learning based molecular property prediction holds the promise of enabling accurate predictions at much less complexity, when compared to, for example Density Functional Theory (DFT) calculations. Features extracted from molecular graphs, using graph neural nets in a supervised manner, have emerged as strong baselines for such tasks. However, the vast chemical space together with the limited availability of labels makes supervised learning challenging, calling for learning a general-purpose molecular representation. Recently, pre-trained transformer-based language models (PTLMs) on large unlabeled corpus have produced state-of-the-art results in many downstream natural language processing tasks. Inspired by this development, here we present molecular embeddings obtained by training an efficient transformer encoder model, referred to as MoLFormer. This model was employed with a linear attention mechanism and highly paralleized training on 1D SMILES sequences of 1.1 billion unlabeled molecules from the PubChem and ZINC datasets. Experiments show that the learned molecular representation performs competitively, when compared to existing graph-based and fingerprint-based supervised learning baselines, on the challenging tasks of predicting properties of QM8 and QM9 molecules. Further task-specific fine-tuning of the MoLFormerr representation improves performance on several of those property prediction benchmarks. These results provide encouraging evidence that large-scale molecular language models can capture sufficient structural information to be able to accurately predict quantum chemical properties and beyond.
翻译:分子结构中的预测化学特性在许多应用中非常重要,包括药物发现和材料设计。机器学习的分子属性预测与密度功能理论(DFT)的计算相比,有可能使精确预测的准确性远不那么复杂。从分子图中提取的特性,以监督的方式以图形神经网作为这类任务的强有力的基线。然而,由于化学空间广大,加上标签有限,使得监督学习具有挑战性,要求学习通用分子代表制。最近,在大型无标签材料上,预先训练的基于变压器的语言模型(PTLMS)已经在许多下游自然语言处理任务中产生了最先进的结果。受此发展启发,我们在这里介绍了通过培训高效变压器编码模型(称为MLFormer)获得的分子嵌入。这个模型使用了一个线性关注机制,对1D SMILES序列(PubChem和ZINC数据库之外的11亿个未贴标签的分子标定基准,这些基于大型无标签的变压器语言模型(PTLLLMMMM)的变压式语言模型,这些变压式模型的模型能性能性预测性能性能性能性能数据模型,这些模型的模型在对比模型上,这些模型的模型的模型的模型上,这些模型的模型的模型的模型上,这些模型的模型的模型的模型的模型的模型的精确性能性能性能性能性能性能性能性能性能性能性能性能性能,这些模型,这些模型,这些模型,这些模型的模型在对比性能性能性能性能性能的数学性能的模型,这些模型,这些模型,这些模型的模型的模型的模型的模型的数学性能,这些模型的模型的模型的模型的模型,这些模型,这些模型的模型的模型的模型的模型的模型的模型的模型的模型,这些模型的模型的模型的模型的模型的模型的数学性能学学学,这些模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型,这些模型的模型的模型的模型的模型的模型的模型的模型的模型,这些模型,这些模型的模型,这些模型的模型的模型的精确性能性能的