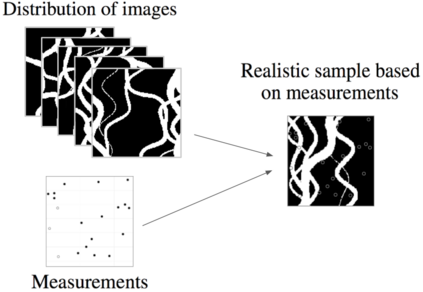
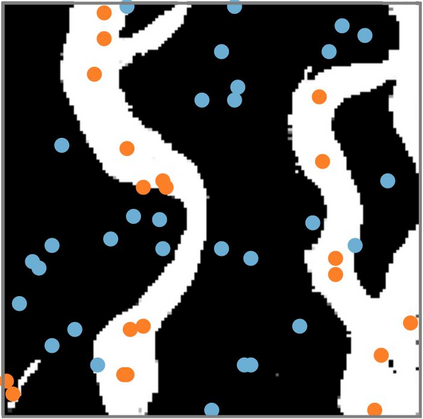
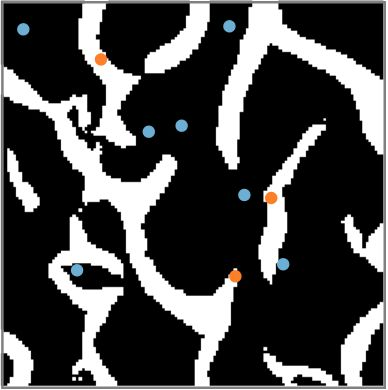
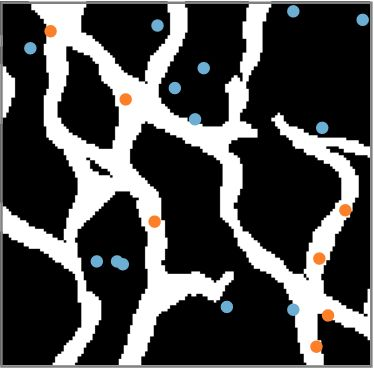
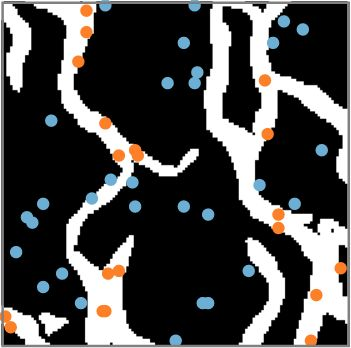
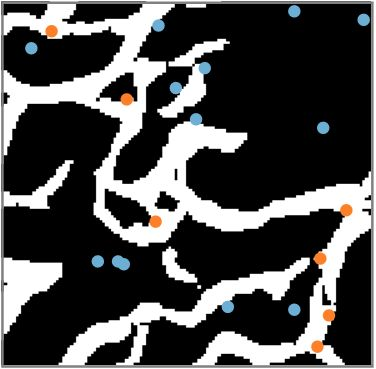
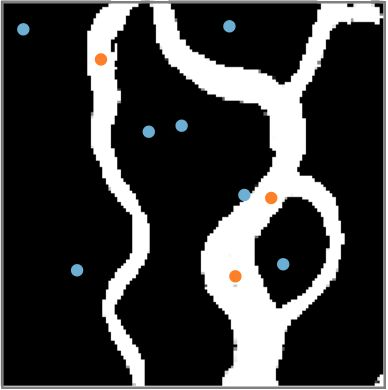
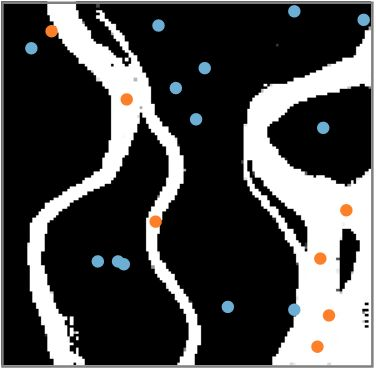
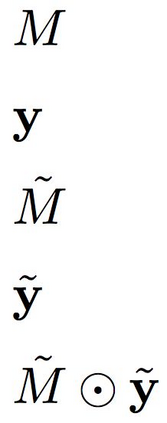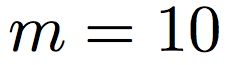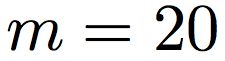An important problem in geostatistics is to build models of the subsurface of the Earth given physical measurements at sparse spatial locations. Typically, this is done using spatial interpolation methods or by reproducing patterns from a reference image. However, these algorithms fail to produce realistic patterns and do not exhibit the wide range of uncertainty inherent in the prediction of geology. In this paper, we show how semantic inpainting with Generative Adversarial Networks can be used to generate varied realizations of geology which honor physical measurements while matching the expected geological patterns. In contrast to other algorithms, our method scales well with the number of data points and mimics a distribution of patterns as opposed to a single pattern or image. The generated conditional samples are state of the art.
翻译:地理统计学中的一个重要问题是,在空间稀少的地点进行物理测量,从而建立地球地表下层的模型。通常,这是使用空间内插方法或通过从参考图像中复制模式来完成的。然而,这些算法未能产生现实的模式,也没有显示出地质学预测所固有的广泛不确定性。在本文中,我们展示了如何利用基因反向网络的语义涂色来产生各种地质学认识,既符合物理测量,又与预期的地质模式相匹配。与其他算法不同,我们的方法尺度与其他算法不同,与数据点和图谱的分布相比,与单一模式或图案或图案的分布相比,我们的方法尺度与数据点和图案的分布相仿。生成的有条件样本是艺术状态。