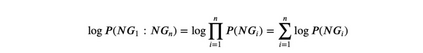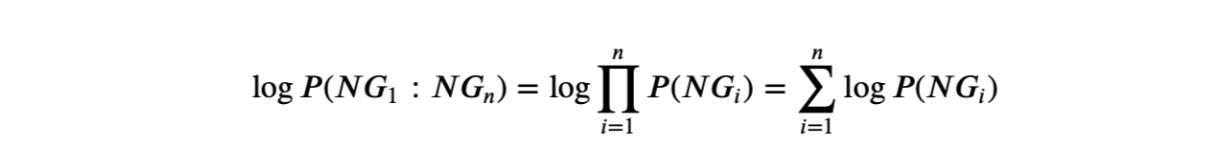Data augmentation (DA) is a common solution to data scarcity and imbalance problems, which is an area getting increasing attentions from the Natural Language Processing (NLP) community. While various DA techniques have been used in NLP research, little is known about the role of linguistic knowledge in DA for NLP; in particular, whether more linguistic knowledge leads to a better DA approach. To investigate that, we designed two adapted DA programs and applied them to LCQMC (a Large-scale Chinese Question Matching Corpus) for a binary Chinese question matching classification task. The two DA programs produce augmented texts by five simple text editing operations, largely irrespective of language generation rules, but one is enhanced with a n-gram language model to make it fused with extra linguistic knowledge. We then trained four neural network models and a pre-trained model on the LCQMC train sets of varying size as well as the corresponding augmented trained sets produced by the two DA programs. The test set performances of the five classification models show that adding probabilistic linguistic knowledge as constrains does not make the base DA program better, since there are no discernible performance differences between the models trained on the two types of augmented train sets. Instead, since the added linguistic knowledge decreases the diversity of the augmented texts, the trained models generalizability is hampered. Moreover, models trained on both types of the augmented trained sets were found to be outperformed by those directly trained on the associated un-augmented train sets, due to the inability of the underlying text editing operations to make paraphrastic augmented texts. We concluded that the validity and diversity of the augmented texts are two important factors for a DA approach or technique to be effective and proposed a possible paradigm shift for text augmentation.
翻译:数据增强( DA) 是数据稀缺和失衡问题的共同解决方案, 是一个自然语言处理( NLP) 社区日益关注的数据稀缺和失衡问题的一个领域。 虽然国家语言处理( NLP ) 研究中使用了各种 DA 技术, 但对于国家语言处理( NLP) 来说, 语言知识在DA 中的作用却知之甚少; 特别是语言知识是否导致更好的 DA 方法。 为了调查这一点, 我们设计了两个经调整的 DA 程序, 并将其应用到 LCQMC (一个大型中国问题匹配 Corpus) 的二进制中国问题匹配分类任务。 两个 DA 程序通过五个简单的文本编辑操作来增加文本, 基本上不管语言生成规则如何, 但有一个以 ng 语言编辑模式来使其与额外的语言知识融合起来。 然后, 我们训练了四个神经网络网络模型和一个经过预先训练的模型, 以及两个DA程序提出的相应增强的训练的数据集。 五个分类模型的性能显示, 增量性语言知识作为限制, 使DA 程序的基础程序程序程序变得更好, 因为没有明显的不易操作。