这篇文章是为了纪念这个系列的一周年,在这个系列中,我们研究了由知识图谱驱动的NLP和图形ML的进步! 观众的反馈促使我继续说下去,所以请系紧安全带(或许也可以系上一些),在这一集中,我们来看看与知识图谱(KG)相关的ACL 2020进程。 今天的议程如下:
-
结构化数据的问答
-
KG嵌入:双曲空间和超关系
-
数据到文本NLG:准备你的Transformer
-
对话式AI:改进面向目标的机器人
-
信息提取:OpenIE和链接预测
-
结论
KG嵌入:双曲空间和超关系
双曲空间是ML中最近的热门话题之一。用更简单的术语来说,在双曲空间中(得益于其属性),你可以使用更少的维数有效地表示层次结构和树状结构。

基于这个动机,Chami等人提出了AttH,一种双曲线的KG嵌入算法,在KG中利用使用旋转、反射和转换对逻辑和层次模式进行建模。Att来自于应用于旋转和反射矢量的双曲注意。绕过不稳定的黎曼优化的诀窍是使用正切空间,d维的庞加莱球的每个点都可以映射到正切空间。在这个明显不平凡的设置中,每个关系不仅与一个向量相关,而且与描述特定关系的反射和旋转的参数相关。然而,在现实生活中,KGs中R << V,所以开销不是很大。 在实验中,AttH在具有一定层次结构的WN18RR和Yago3和Yago10上表现优越,在FB15k-237上的差距较小。更重要的是,仅32维的AttH就显示了巨大的优势,相比于真实和复杂平面的32维模型。此外,WN18RR和FB15k-237的32维在评价标准MRR评分上仅比SOTA 500维的嵌入模型分别小0.02和0.03。消融研究证明了可学习的曲率的重要性,而其优于最接近的匹配模型MurP。
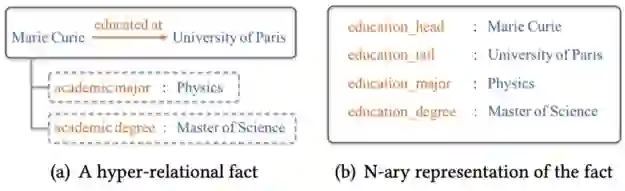
图表示学习的另一个趋势是超越简单的KG组成的三元组和学习表示对于更复杂,超关系KG,当每一个三元组可能有一组键-值对属性,提供细粒度细节三在各种情况下的有效性。事实上,Wikidata在其Wikidata语句模型中采用了超关系模型,其中属性被称为限定符。重要的是不要将模型与n元事实(生成冗余谓词)和超图混合在一起。也就是说,如果你只在三元组层面上与Wikidata一起工作,你就会失去一大半的内容。 Guan等人不想失去Wikidata的一半,他们提出了NeuInfer,一种学习超关系KGs嵌入的方法(他们之前的工作,NaLP,更适合n元事实)。
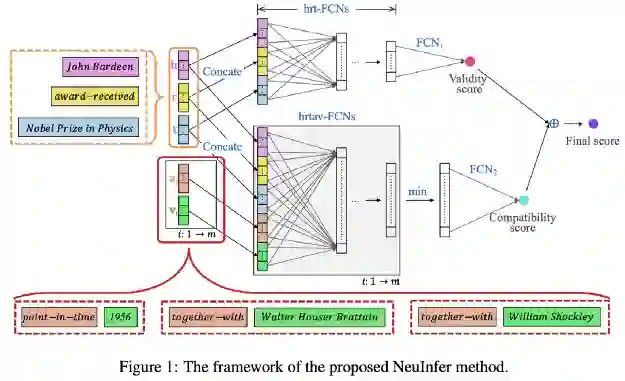
NeuInfer的思想是计算一个超关系事实(见图)的有效性和兼容性评分。首先,(h,r,t)嵌入输入到一个全连接的网络(FCN)来估计这个三元组(有效性)的合理的概率。其次,为每个键值对构造一个五组(h,r,t,k,v),并通过另一组FCNs传递。有m对,m个向量经过最小池化,得到表示相容度评分的结果,即这些限定符在主要三元组中的表现如何。最后,用两个分数的加权和得到最终评分。 作者在标准基准JF17K(提取自Freebase)和WikiPeople(来自Wikidata)上评估了NeuInfer,并报告说JF17K在预测头实体、尾实体和属性值方面比NaLP有显著的改进。我鼓励作者将他们的数字与HINGE(来自Rosso等人)进行比较,因为这两种方法在概念上是相似的。 现在我们需要谈谈顶级会议上发布的KG嵌入算法的复现性,比如ACL 2019,Sun, Vashishth, Sanyal等人发现,报告SOTA结果(明显优于现有基线)的几个最近的KGE模型受到测试集泄漏的影响,或在ReLU激活有效三元组得分后出现许多异常零化的神经元。此外,他们还表明,他们的性能度量标准(如Hits@K和MRR)取决于在有效三元组负采样(实际上,这是不应该发生的)中的位置。另一方面,现有的强基线在任何位置的表现都是一样的。我们要做的就是使用评估原则,将一个有效的三元组随机放置在负样本的位置上。
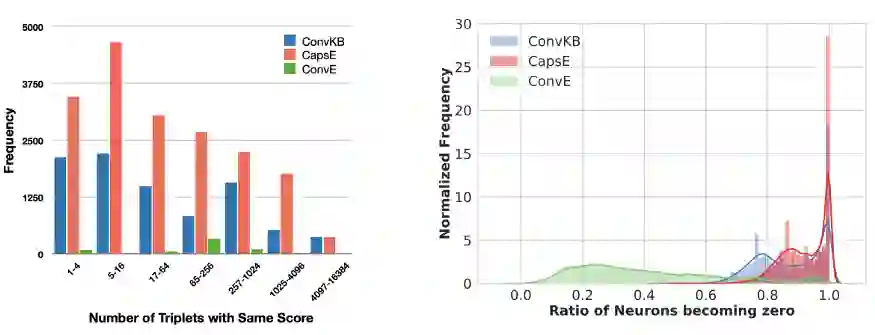
我们的团队对这个问题也有话要说:在我们的新论文《让黑暗变得光明》(bring Light Into the Dark)中:大规模评估知识图谱嵌入模型的一个统一的框架下我们执行65 k +实验和k + GPU 21小时评估19模型从RESCAL首先发表在2011年RESCAL到2019年末 RotatE 和TuckER,,5种损失函数,各种训练策略有/没有负采用,和更多重要考虑的超参数。我们还将为您和我们热爱的社区发布为所有模型找到的最佳超参数。此外,我们正在发布PyKEEN 1.0,这是一个PyTorch库,用于训练和基准测试KG嵌入式模型! 我鼓励你仔细阅读其他一些作品:Sachan研究了通过离散化压缩KG实体嵌入的问题,例如,Barack Obama将被编码为“2 1 3 3”,而不是200维的32位的浮点向量,Michelle Obama将被编码为“2 1 3 2”。

也就是说,你只需要一个有K个值的D维长向量(这里D=4, K=3)。对于离散化,Softmax被发现性能更好。并且作为一个从KD代码返回到n维浮点数向量的反向函数,作者建议使用一个简单的Bi-LSTM。实验结果显示,FB15k-237和WN18RR的压缩率达到了100-1000倍,但在推理时(当需要解码KD代码时)的性能下降和计算开销可以忽略不计(最大MRR为2%)。 我建议大家坐下来,重新考虑一下KGE的pipelines(特别是在生产场景中)。例如,通过PyTorch-BigGraph获得的78M Wikidata实体的200维嵌入需要110 GB的空间。想象一下压缩100倍会有什么可能? 还有一系列的工作改进了流行的KGE模型:
- Tang等人用正交关系变换将二维旋转推广到高维空间,这种正交关系变换对1-N和N-N关系更有效。
- Xu等人通过对K个部分的稠密向量进行分块,将双线性模型推广为多线性模型。结果表明,当K=1时,该方法等于DistMult,当K=2时,该方法简化为 ComplEx 和 HolE,并在K=4和K=8时进行了实验。
- Xie等人对ConvE进行了扩展,将标准的卷积滤波器替换为计算机视觉领域中最著名的Inception网络。
- Nguyen等人应用了一个自注意风格的编码器和一个CNN解码器的三元组分类和个性化搜索任务。
结论
在今年的ACL2020中,我们看到了更少的KG增强的语言模型(但是可以看看TaPas和TABERT,它们被设计用于在 tables上工作),NER可能也少了一些。另一方面,图形到文本的NLG正在上升!