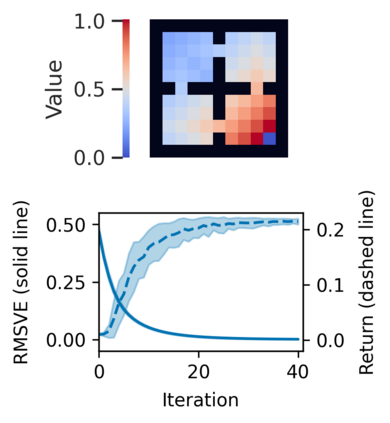
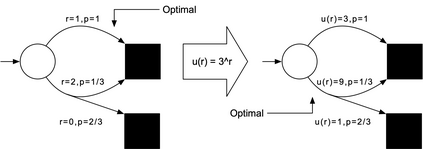
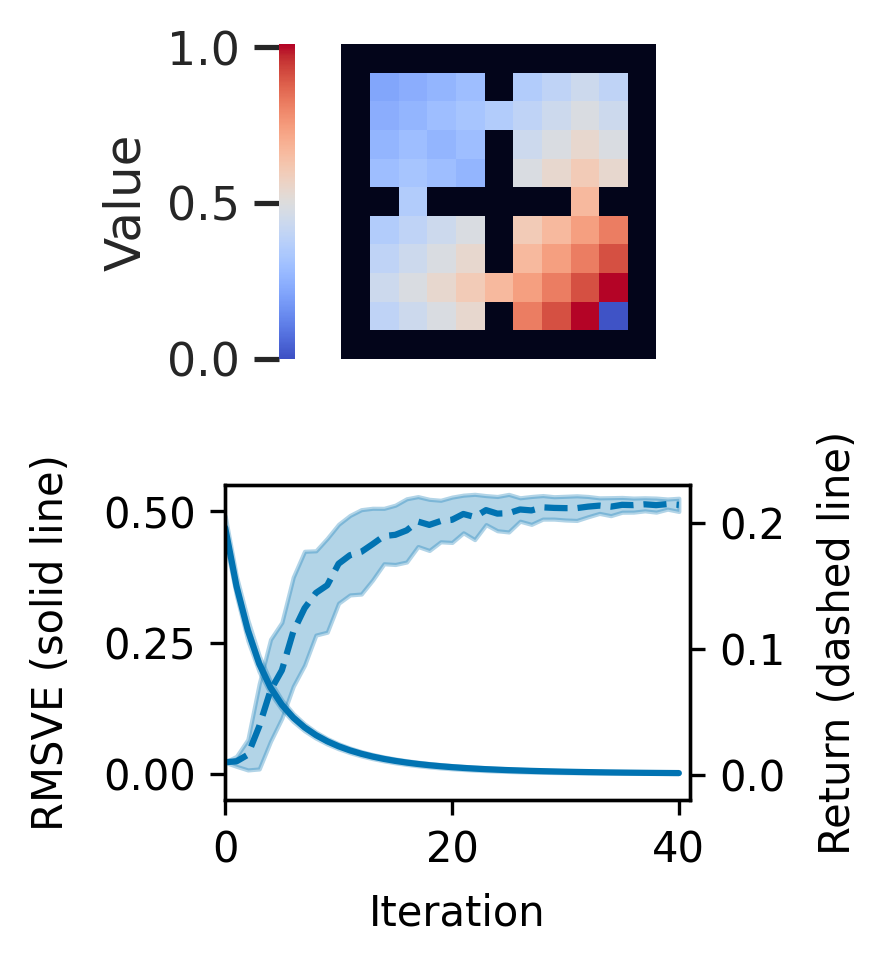
Reward-Weighted Regression (RWR) belongs to a family of widely known iterative Reinforcement Learning algorithms based on the Expectation-Maximization framework. In this family, learning at each iteration consists of sampling a batch of trajectories using the current policy and fitting a new policy to maximize a return-weighted log-likelihood of actions. Although RWR is known to yield monotonic improvement of the policy under certain circumstances, whether and under which conditions RWR converges to the optimal policy have remained open questions. In this paper, we provide for the first time a proof that RWR converges to a global optimum when no function approximation is used, in a general compact setting. Furthermore, for the simpler case with finite state and action spaces we prove R-linear convergence of the state-value function to the optimum.
翻译:重负回归(RWR) 属于一个以期望-最大化框架为基础的广为人知的迭代强化学习算法大家庭。在这个大家庭中,每次迭代学习都包括利用现行政策抽样一组轨迹,并采用新政策最大限度地实现回报加权日志行动。虽然据知RWR在某些情况下会产生政策单一的改进,但RWR是否和在何种条件下与最佳政策趋同仍然是开放的问题。 在本文中,我们首次提供了证据,证明RWR在没有使用函数近似值的情况下,在一般契约环境下,RWR会与全球最佳一致。此外,对于使用有限状态和行动空间的简单案例,我们证明国家价值功能与最佳状态的R线性趋同。