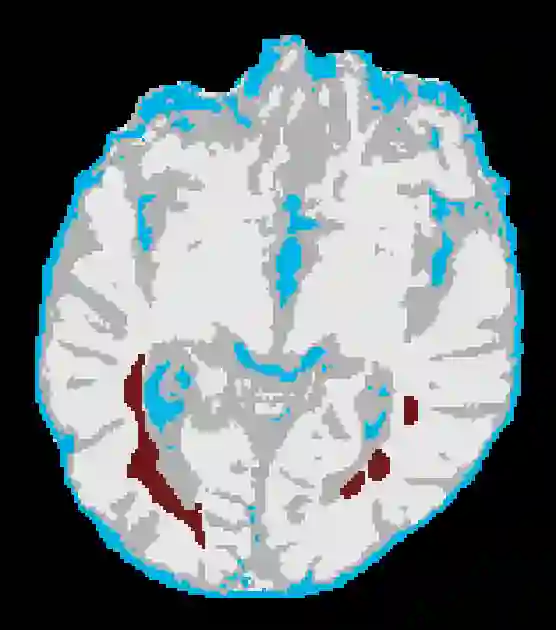
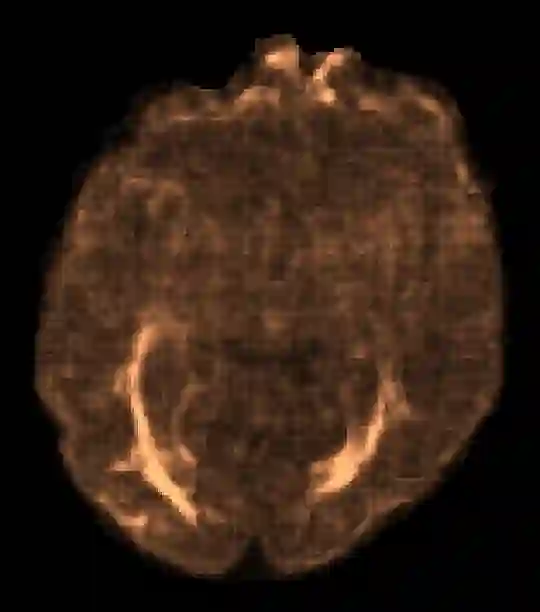
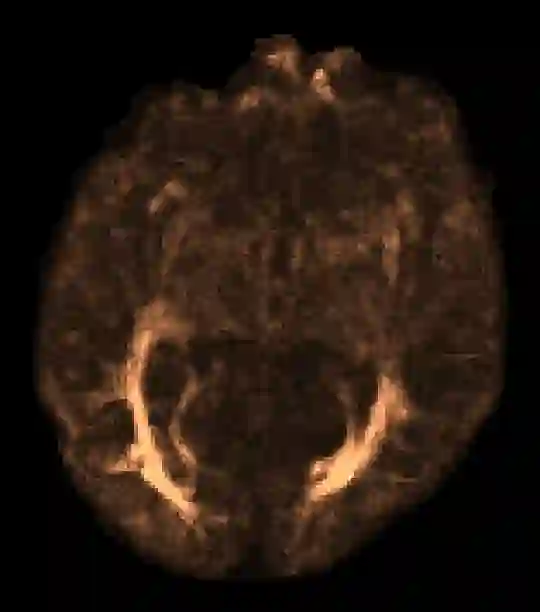
In machine learning, novelty detection is the task of identifying novel unseen data. During training, only samples from the normal class are available. Test samples are classified as normal or abnormal by assignment of a novelty score. Here we propose novelty detection methods based on training variational autoencoders (VAEs) on normal data. Since abnormal samples are not used during training, we define novelty metrics based on the (partially complementary) assumptions that the VAE is less capable of reconstructing abnormal samples well; that abnormal samples more strongly violate the VAE regularizer; and that abnormal samples differ from normal samples not only in input-feature space, but also in the VAE latent space and VAE output. These approaches, combined with various possibilities of using (e.g. sampling) the probabilistic VAE to obtain scalar novelty scores, yield a large family of methods. We apply these methods to magnetic resonance imaging, namely to the detection of diffusion-space (q-space) abnormalities in diffusion MRI scans of multiple sclerosis patients, i.e. to detect multiple sclerosis lesions without using any lesion labels for training. Many of our methods outperform previously proposed q-space novelty detection methods. We also evaluate the proposed methods on the MNIST handwritten digits dataset and show that many of them are able to outperform the state of the art.
翻译:在机器学习中,新发现的检测是查明新隐蔽数据的任务。在培训期间,只有普通类的样本,只有普通类的样本。测试样品通过分配新评分被归类为正常或异常。在这里,我们提出基于正常数据培训变异自动算数(VAE)的新颖检测方法。由于在培训期间没有使用异常样本,我们根据VAE不善于重建异常样本的(部分互补)假设来定义新颖的衡量标准;异常样品更强烈地违反VAE正规化器;异常样品不仅在输入-功能空间,而且在VAE潜藏空间和VAE输出中也不同于正常样品。这些方法,加上使用(例如抽样)变异自动变异的VAE来获取变异性新分数,产生一大批方法。我们将这些方法应用于磁共振动成成像,即检测多种硬性硬性硬性硬性硬性反应病人的MRI扫描,即检测多种硬性硬性硬性硬性反应病人的样本,即用多种硬性硬性组织式的检测方法,同时评估我们提议的前变变形系统测试。