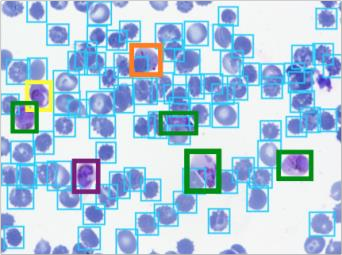
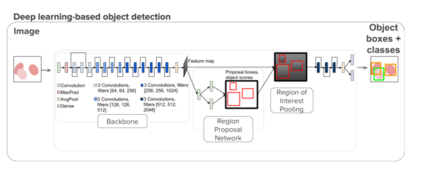
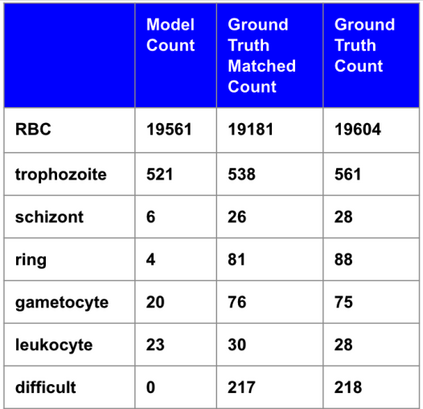
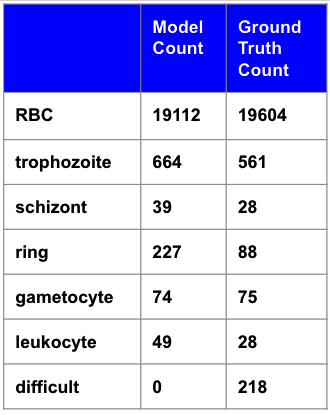
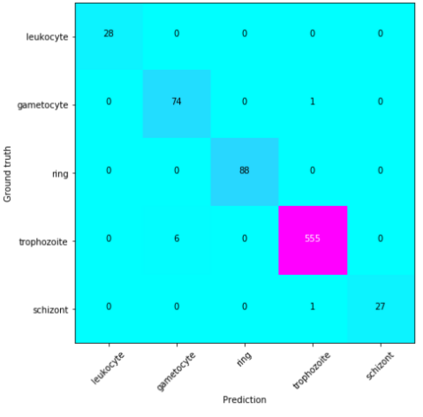
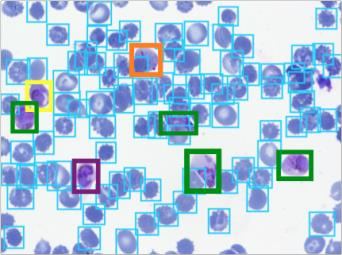
Deep learning based models have had great success in object detection, but the state of the art models have not yet been widely applied to biological image data. We apply for the first time an object detection model previously used on natural images to identify cells and recognize their stages in brightfield microscopy images of malaria-infected blood. Many micro-organisms like malaria parasites are still studied by expert manual inspection and hand counting. This type of object detection task is challenging due to factors like variations in cell shape, density, and color, and uncertainty of some cell classes. In addition, annotated data useful for training is scarce, and the class distribution is inherently highly imbalanced due to the dominance of uninfected red blood cells. We use Faster Region-based Convolutional Neural Network (Faster R-CNN), one of the top performing object detection models in recent years, pre-trained on ImageNet but fine tuned with our data, and compare it to a baseline, which is based on a traditional approach consisting of cell segmentation, extraction of several single-cell features, and classification using random forests. To conduct our initial study, we collect and label a dataset of 1300 fields of view consisting of around 100,000 individual cells. We demonstrate that Faster R-CNN outperforms our baseline and put the results in context of human performance.
翻译:深层学习模型在物体检测方面取得了巨大成功,但先进模型的状况尚未被广泛应用于生物图像数据。我们首次应用了先前在自然图像上使用的物体检测模型,以识别细胞,并辨别其在受疟疾感染血液光外显微镜图像中的阶段。许多微生物,如疟疾寄生虫,仍然由专家手工检查和手计来研究。由于细胞形状、密度和颜色的变化以及某些细胞类别的不确定性等因素,这类物体检测任务具有挑战性。此外,用于培训的附加说明的数据非常稀少,班级分布因未受感染的红血细胞占优势而必然高度不平衡。我们使用了基于更快区域的神经神经神经网络(Aster R-CNN),这是近年来最高级的性物体检测模型之一,事先经过了图像网络的训练,但与我们的数据进行了细微调,并将它与基线进行比较,该基线基于传统的方法,包括细胞分解、提取若干单细胞特征以及使用随机森林进行分类。我们进行的初步研究时,我们收集并标注了1300个区域光谱域的数据集。我们展示了10万个基本结果。