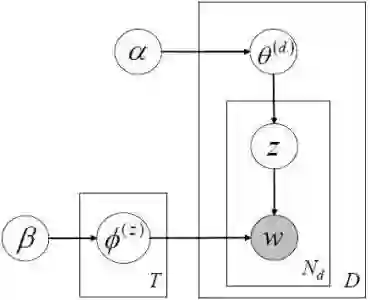
It has always been a burden to the users of statistical topic models to predetermine the right number of topics, which is a key parameter of most topic models. Conventionally, automatic selection of this parameter is done through either statistical model selection (e.g., cross-validation, AIC, or BIC) or Bayesian nonparametric models (e.g., hierarchical Dirichlet process). These methods either rely on repeated runs of the inference algorithm to search through a large range of parameter values which does not suit the mining of big data, or replace this parameter with alternative parameters that are less intuitive and still hard to be determined. In this paper, we explore to "eliminate" this parameter from a new perspective. We first present a nonparametric treatment of the PLSA model named nonparametric probabilistic latent semantic analysis (nPLSA). The inference procedure of nPLSA allows for the exploration and comparison of different numbers of topics within a single execution, yet remains as simple as that of PLSA. This is achieved by substituting the parameter of the number of topics with an alternative parameter that is the minimal goodness of fit of a document. We show that the new parameter can be further eliminated by two parameter-free treatments: either by monitoring the diversity among the discovered topics or by a weak supervision from users in the form of an exemplar topic. The parameter-free topic model finds the appropriate number of topics when the diversity among the discovered topics is maximized, or when the granularity of the discovered topics matches the exemplar topic. Experiments on both synthetic and real data prove that the parameter-free topic model extracts topics with a comparable quality comparing to classical topic models with "manual transmission". The quality of the topics outperforms those extracted through classical Bayesian nonparametric models.
翻译:统计主题模型的用户总是要预先确定主题的正确数量,这是大多数主题模型的一个关键参数。 常规上, 该参数的自动选择是通过统计模型选择( 交叉校验、 AIC 或 BIC ) 或巴伊西亚非参数模型( 例如等级分级 Drichlet 进程) 完成的。 这些方法要么依靠反复运行的推算算算法来通过不适应大数据挖掘的多种自由参数值来搜索, 要么用其他参数取代这个参数, 这些参数不太直观, 仍然难以确定。 在本文件中, 我们探索从新角度“ 终结” 这个参数。 我们首先对称为非参数性直观潜伏隐变色分析( nPLSA ) 的PLSA 模型进行不偏重的解析。 NPLSA 的推论程序允许在一次执行中探索和比较不同主题的模型数量, 并且与 PLSA 的比对等简单。 这是通过替换模型的参数参数的参数来完成的。 我们通过两个不同的模型来“ 比较 ” 演示论题的演示文的理论,, 通过一种最优的理论的理论, 使得这些论子的理论的理论的理论的转而更接近于被揭示。