选自TensorFlow Blog
机器之心编译
编辑:小舟、蛋酱
今天,谷歌正式发布了 TensorFlow 2.4,带来了多项新特性和功能改进。
![]()
TensorFlow 2.4 的更新包括对于分布式训练和混合精度的新功能支持,对 NumPy API 子集的试验性支持以及一些用于监测性能瓶颈的新工具。
根据 TensorFlow 官方博客,本次更新的主要内容整理如下:
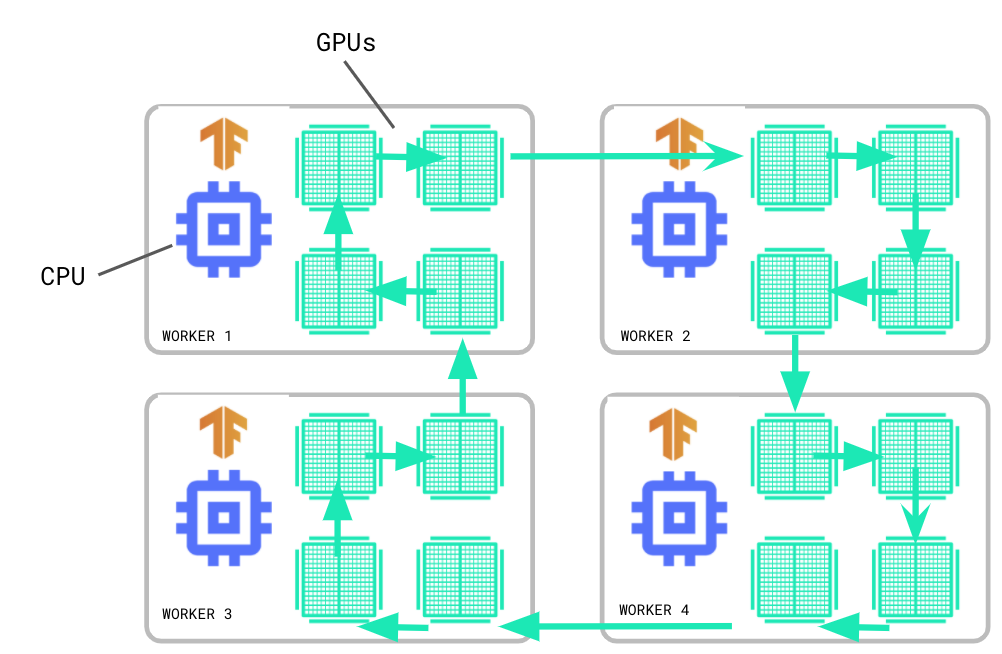
在 TensorFlow 2.4 中,tf.distribute 模块引入了对使用 ParameterServerStrategy 和自定义训练循环进行模型异步训练的试验性支持。和 MultiWorkerMirroredStrategy 类似,ParameterServerStrategy 是一种多工作器(multi-worker)数据并行策略,但梯度更新是异步的。
参数服务器训练集群由工作服务器和参数服务器组成。变量在参数服务器上创建,然后在每个步骤中由工作器读取和更新。变量的读取和更新在工作器之间是独立进行的,不存在任何同步。由于工作器彼此不依赖,因此该策略具有工作器容错的优势,如果使用可抢占 VM,该策略将很有用。
MultiWorkerMirroredStrategy 已经脱离试验阶段,成为稳定的 API。像单工作器的 MirroredStrategy 一样,MultiWorkerMirroredStrategy 通过同步数据并行实现分布式训练,顾名思义,借助 MultiWorkerMirroredStrategy 可以在多台机器上进行训练,每台机器都可能具有多个 GPU。
![]()
在 TensorFlow 2.4 中,Keras 混合精度 API 已经脱离试验阶段,成为稳定的 API。大多数 TensorFlow 模型使用 float32 dtype,但现在有些低精度数据类型占用的内存更少,比如 float16。混合精度指的是在同一模型中使用 16 位和 32 位浮点数以进行更快的训练。这一 API 可将模型性能在 GPU 上提高到 3 倍,在 TPU 上提高 60%。要使用混合精度 API,必须使用 Keras 层和优化器,但不一定需要使用其他 Keras 类。
本次更新包括重构 tf.keras.optimizers.Optimizer 类,让 model.fit 的用户和自定义训练循环的用户能够编写可与任何优化器一起使用的训练代码。所有内置 tf.keras.optimizer.Optimizer 子类都可接受 gradient_transformers 和 gradient_aggregator 参数,轻松定义自定义梯度变换。
重构之后,使用者可以在编写自定义训练循环时直接将损失张量传递给 Optimizer.minimize:
tape = tf.GradientTape()with tape: y_pred = model(x, training=True) loss = loss_fn(y_pred, y_true)
optimizer.minimize(loss, model.trainable_variables, tape=tape)
这些更新的目标是让 Model.fit 和自定义训练循环与优化器细节更加不相关,从而让使用者无需修改即可编写出与任何优化器共同使用的训练代码。
最后,TensorFlow 2.4 的更新还包括 Keras Functional API 内部的重构,改善了函数式模型构造所产生的内存消耗并简化了触发逻辑。这种重构可以保证 TensorFlowOpLayers 的行为可预测,并且可以使用 CompositeTensor 类型签名(type signature)。
TensorFlow 2.4 引入了对 NumPy API 子集的试验性支持。该模块可以运行由 TensorFlow 加速的 NumPy 代码,由于这一 API 是基于 TensorFlow 构建的,因此可与 TensorFlow 无缝衔接,允许访问所有 TensorFlow API 并通过编译和自动矢量化提供优化后的运行。
例如,TensorFlow ND 数组可以与 NumPy 函数互通,类似地,TensorFlow NumPy 函数可以接受包括 tf.Tensor 和 np.ndarray 在内的不同类型输入。
import tensorflow.experimental.numpy as tnp# Use NumPy code in input pipelines
dataset = tf.data.Dataset.from_tensor_slices( tnp.random.randn(1000, 1024)).map(lambda z: z.clip(-1,1)).batch(100)# Compute gradients through NumPy codedef grad(x, wt):with tf.GradientTape() as tape: tape.watch(wt) output = tnp.dot(x, wt) output = tf.sigmoid(output)return tape.gradient(tnp.sum(output), wt)
TensorFlow Profiler 是度量 TensorFlow 模型的训练性能和资源消耗情况的工具,用来诊断性能瓶颈,最终加快训练速度。
此前,TensorFlow Profiler 支持多 GPU 单主机训练。到了 2.4 版本,使用者可以测试 MultiWorkerMirroredStrategy 的训练工作了,比如使用采样模式 API 按需配置,并连接到 MultiWorkerMirroredStrategy 工作器正在使用的同一服务器。
# Start a profiler server before your model runs.
tf.profiler.experimental.server.start(6009)# Model code goes here....# E.g. your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you# would like to profile for a duration of 2 seconds. The profiling data will# be saved to the Google Cloud Storage path “your_tb_logdir”.
tf.profiler.experimental.client.trace('grpc://10.0.0.2:6009,grpc://10.0.0.3:6009,grpc://10.0.0.4:6009','gs://your_tb_logdir',2000)
另外,你可以通过向捕获配置文件工具提供工作器地址来使用 TensorBoard 配置文件插件。配置之后,你可以使用新的 Pod Viewer tool 来选择训练步骤,并查看所有工作器上该步骤的 step-time 的细分。
TFLite Profiler 则支持在 Android 中跟踪 TFLite 内部信息,以识别性能瓶颈。
TensorFlow 2.4 与 CUDA 11 和 cuDNN 8 配合运行,支持最新发布的英伟达安培架构 GPU,对于 CUDA 11 的新特性,可以参考英伟达开发者博客:
https://developer.nvidia.com/blog/cuda-11-features-revealed/
在新版本中,默认情况下会启用安培 GPU 的新特性——对 TensorFloat-32 的支持。TensorFloat-32 又简称为 TF32,是英伟达 Ampere GPU 的一种数学精度模式,可导致某些 float32 运算(如矩阵乘法和卷积)在安培架构 GPU 上运行得更快,但精度略有降低。
https://www.tensorflow.org/api_docs/python/tf/config/experimental/enable_tensor_float_32_execution
「三小时AI开发进阶」公开课上线!本周四(12月17日)20:00,百度高级研发工程师可乐老师将在第一课《小目标检测技术详解》中介绍:
-
-
技术讲解:小目标检测场景定义、难点分析与相应算法讲解
-
-
现场实战:基于EasyDL完成物体检测模型开发与部署
扫码进群听课
,还有机会赢取100元京东卡、《智能经济》实体书、限量百度鼠标垫多重好奖!
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com