爱奇艺深度语义表示学习的探索与实践


分享嘉宾:奇文 爱奇艺
编辑整理:Hoh
内容来源:爱奇艺技术产品团队
出品平台:DataFunTalk
注:转载请联系原作者。
导读:基于学术界和工业界经验,爱奇艺设计和探索出了一套适用于爱奇艺多种业务场景的深度语义表示学习框架。在推荐、搜索、直播等多个业务中的召回、排序、去重、多样性、语义匹配、聚类等场景上线,提高视频推荐的丰富性和多样性,改善用户观看和搜索体验。本文将介绍爱奇艺深度语义表示框架的核心设计思路和实践心得。
英国语言学家 J.R.Firth 在1957年曾说过:" You shall know a word by the company its keeps. " Hinton 于1986年基于该思想首次提出 Distributed representation ( 分布式表示 ) 的概念,认为具有相似上下文的词往往具有相似的语义,其中 distributed 是指将词语的语义分布到词向量的各个分量上。该方法可以把词映射到连续实数向量空间,且相似词在该空间中位置相近,典型的代表作是基于神经网络的语言模型 ( Neural Network Language Model,NNLM ) [1]。2003年 Google 提出 word2vec [2] 算法学习 word embedding ( 词嵌入或词向量 ),使 Distributed representation 真正受到学术界、工业届的认可, 从而开启了 NLP embedding 发展的新元代。
在万物皆 embedding 的信息流时代,embedding 能够将文本、图像、视频、音频、用户等多种实体从一种高维稀疏的离散向量表示 ( one-hot representation ) 映射为一种低维稠密的连续语义表示 ( distributed representation ),并使得相似实体的距离更加接近。其可用于衡量不同实体之间的语义相关性,作为深度模型的语义特征或离散特征的预训练 embedding, 广泛应用于推荐和搜索等各个业务场景,比如推荐中的召回、排序、去重、多样性控制等, 搜索中的语义召回、语义相关性匹配、相关搜索、以图搜剧等。
相比传统的 embedding 模型, 深度语义表示学习将实体丰富的 side information ( e.g. 多模态信息, 知识图谱,meta 信息等 ) 和深度模型 ( e.g. Transformer [3],图卷积网络 [4] 等 ) 进行深度融合,学习同时具有较好泛化性和语义表达性的实体 embedding,为下游各业务模型提供丰富的语义特征,并在一定程度上解决冷启动问题, 进而成为提升搜索和推荐系统性能的利器。
爱奇艺设计和探索出了这套适用于爱奇艺多种业务场景的深度语义表示学习框架,并在推荐的多个业务线以及搜索中成功上线。在短&小视频、图文信息流推荐以及搜索、直播等15个业务中的召回、排序、去重、多样性、语义匹配、聚类等7种场景,完成多个 AB 实验和全流量上线,短&小视频以及图文推荐场景上,用户的人均消费时长共提升5分钟以上,搜索语义相关性准确率相比 baseline 单特征提升6%以上。
传统的 embedding 学习模型主要基于节点序列或基于图结构随机游走生成序列构建训练集,将序列中的每个节点编码为一个独立的 ID,然后采用浅层网络 ( e.g. item2vec [6],node2vec [7] ) 学习节点的 embedding。该类模型只能获取训练语料中节点的浅层语义表征,而不能推理新节点的 embedding,无法解决冷启动问题,泛化性差。将传统的 embedding 学习模型应用于爱奇艺业务场景中主要面临以下问题:
1. Embedding 实体种类及关系多样性
传统的 embedding 模型往往将序列中的 item 视为类型相同的节点,节点之间的关系类型较单一。爱奇艺各业务线中的用户行为数据往往包含多种类型的数据,比如,文本 ( 长短文本,句子&段落&篇章级别 )、图像、图文、视频 ( 比如,长、短、小视频 )、用户 ( 比如 up 主、演员、导演、角色 )、圈子 ( 泡泡、文学等社区 )、query 等;不同类型节点之间具有不同的关系,比如用户行为序列中节点之间的关系包括点击、收藏、预约、搜索、关注等,在视频图谱中节点之间的关系包括执导、编写、搭档、参演等。
2. Side information 丰富
传统的 embedding 模型往往采用浅层网络 ( 比如3层 DNN,LSTM 等 ),特征抽取能力较弱;此外将 item 用一个独立 ID 来表示,并未考虑 item 丰富的 side information 和多模态信息,往往仅能学到 item 的浅层语义表征。而爱奇艺各业务中的 item 具有丰富的多模态信息 ( 比如,文本、图像、视频、音频 ) 和各种 meta 信息 ( 比如视频类型、题材、演员属性等 ),如何有效和充分的利用这些丰富的 side information 以及多模态特征的融合,对于更好的理解 item 的深层语义至关重要。
3. 业务场景多样
Embedding 可用于推荐中的召回、排序、去重、多样性以及用户画像建模等,搜索中的语义召回、排序、视频聚类、相关搜索等,以及作为各种下游任务的语义特征等多种业务场景。不同的业务场景往往需要不同类型的 embedding。
推荐召回场景:
基于行为的 embedding 模型召回偏热门,效果较好;
基于内容的 embedding 模型召回偏相关性,对相关推荐场景和新内容冷启动更有帮助;
基于行为和内容的 embedding 模型介于前两者之间,能同时保证相关性和效果。
排序场景:
往往使用后两种 embedding 模型,可基于训练好的模型和内容实时获取未知节点的 embedding 特征。
多样性控制:
基于内容原始表示的 embedding 模型用于去重和多样性打散效果往往较好。
深度语义表示学习在传统的 embedding 学习模型基础上,引入节点丰富的 side information ( 多模态信息和自身 meta 信息 ) 以及类型的异构性,并对多模态特征进行有效融合,将浅层模型替换为特征抽取能力更强的深度模型,从而能够学习节点的深度语义表征。
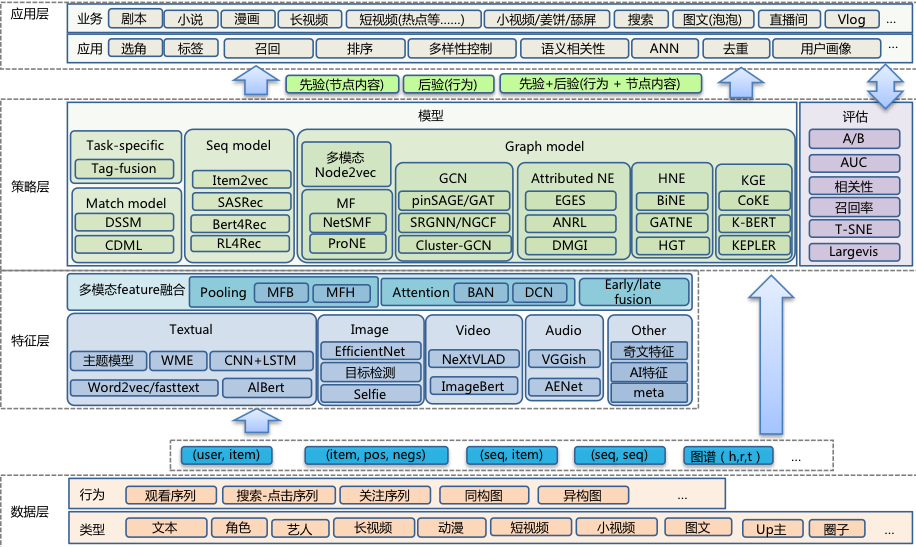
针对爱奇艺的业务场景和数据特点,我们设计出了一种满足现有业务场景的深度语义表示学习框架 ( 如图 1所示 ),该框架主要包含四层:数据层、特征层、策略层和应用层。
数据层:主要搜集用户的各种行为数据构建节点序列和图,构建 embedding 模型训练数据;
特征层:主要用于各种模态 ( 文本、图像、音频、视频等 ) 特征的抽取和融合,作为深度语义表示模型中输入的初始语义表征;
策略层:提供丰富的深度语义表示模型及评估方法,以满足不同的业务场景;
应用层:主要为下游各业务线的各种场景提供 embedding 特征、近邻以及相关度计算服务。
下面主要从特征层和策略层中的各种深度语义表示模型两方面进行详细介绍。
1. 多模态特征抽取
在自然语言处理 ( NLP ) 领域,预训练语言模型 ( 比如 BERT [8] ) 能够充分利用海量无标注语料学习文本潜在的语义信息,刷新了 NLP 领域各个任务的效果。爱奇艺作为中国领先的影音视频平台,涵盖视频、图文的搜索、推荐、广告、智能创作等多种业务场景,除了文本 ( 标题,描述等 ) 外,还需进一步对图像、视频和音频等多种模态信息进行深入理解。借鉴预训练语言模型的思想,我们尝试借助大规模无标注的视频和图文语料,学习不同粒度文本 ( query、句子、段落、篇章 )、图像、音频和视频的通用预训练语义表征,为后续深度语义表示模型提供初始语义表征。
文本语义特征:
根据文本长度,可将文本语义特征抽取分为四个等级:
词级别 ( Token-level ),比如用户搜索串,通常为2~6个字;
句子级别 ( Sentence-level ),比如视频&漫画标题和描述、人物小传、艺人简介等;
段落级别 ( Paragraph-level ),比如影视剧描述,剧本片段等;
篇章级别 ( Document-level ),比如剧本、小说等长文本。
受限于现有预训练语言模型处理长文本的局限性,对于不同级别的文本需要采用不同的方案。一方面,结合主题模型 [10] 和 ALBert [9] 学习 Topic 粒度的语义特征;另一方面,基于 ALBert,利用 WME [11],CPTW [12] 等方法将 token-level 语义组合为段落和篇章级别的细粒度语义特征。
图像语义特征:
对于视频封面图、视频帧、影视剧照、艺人图片、漫画等图像,基于 State-of-Art 的 ImageNet 预训练分类模型 ( e.g. EfficientNet [13] ) 抽取基础语义表示,并采用自监督表示学习思想 ( e.g. Selfish [14] ) 学习更好的图像表示。
音视频语义特征:
对于视频中的音频信息,利用基于 YouTube-AudioSet 数据上预训练的 Vggish [15] 模型从音频波形中提取具有语义的128维特征向量作为音频表示。对于视频内容的语义建模,我们选择一种简单而高效的业界常用方法,仅利用视频的关键帧序表示视频内容,并通过融合每个关键帧的图像级别语义特征得到视频级别的语义特征。
2. 多模态特征融合
融合时机:
主要包含 late fusion,early fusion 和 hybrid fusion。顾名思义,early fusion 是指将多个特征先进行融合 ( e.g. 拼接 ),再通过特征学习模块进行训练;late fusion 是指每个特征先通过各自的特征学习模块变换后再进行融合;hybrid fusion 组合两种 fusion 时机,可学习丰富的特征交叉,效果通常最好。
融合方式:
高效合理的融合各种多种模态信息,能够较大程度上提升视频的语义理解。目前多模态融合方法主要包括三大类方法:
最为直接的方法:通过 element-wise product/sum 或拼接,融合多模态特征,但不能有效的捕捉多模态特征之间的复杂关联。
基于 pooling 的方法:主要思想是通过 bilinear pooling 的思想进行多种模态特征融合,典型代表作包括 MFB [16] 和 MFH [17] 等。
基于注意力机制的方法: 借鉴 Visual Question Answering ( VQA ) 的思想,注意力机制能够根据文本表示,让模型重点关注图像或视频中相关的特征部分,捕捉多种模态之间的关联性,典型代表作有 BAN ( Bilinear Attention Network ) [18] 等。
-
先使用大量无监督语料进行进行预训练 ( pretraining ),学习通用的语义表示; -
再基于该通用语义表示,使用少量标注语料在特定任务上进行微调 ( finetuning )。
类似地,在文本、图片、音频、视频的通用预训练语义表征基础上,我们尝试在特定的任务中 ( 比如召回、语义匹配等 ) 引入视频丰富的 side information ,以及节点和边类型异构等特点, 并借助抽取能力更强的深度模型进行微调,以学习满足不同业务场景的语义特征。根据建模方式可将深度语义表示模型大致分为以下几类:
1. 基于内容的深度语义模型
基于内容的深度语义模型,顾名思义,模型以单个节点的内容 ( 元数据和多模态信息等 ) 作为输入,并基于人工标注数据作为监督信号进行训练,不依赖任何用户行为数据。该类模型可直接基于节点内容进行推理获取节点语义表示,无冷启动问题;但往往需要大量的人工标注数据进行模型训练。
① 基于 ImageNet 分类的图像 embedding 模型
该类模型主要是基于 State-of-Art的ImageNet 图像预训练分类模型的中间层或最后一层,抽取图像或视频的纯内容表示,并基于自监督表示学习思想 finetuning,作为图像或视频的语义表征,应用于去重 ( 图 2 ) 和推荐 post-rank 阶段多样性控制两种场景的效果较好。

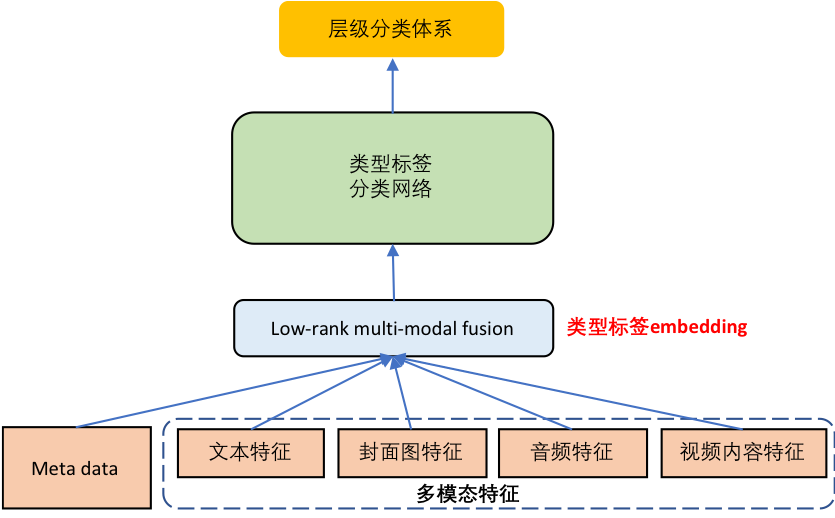
② 基于特定任务的 embedding 模型
该类模型通常基于海量标注数据进行特定任务有监督训练,并抽取模型中间层或最后一层作为文本或视频的表征,比如基于标签分类任务的 embedding 模型 ( 如图 3所示 ),该模型基于视频元数据、文本、图像、音频和视频特征,在大规模标注数据上训练,识别视频的类型标签和内容标签。往往抽取模型 fusion 层的表示作为视频的 topic 粒度语义表征,可有效解决冷启动问题,广泛应用于推荐的召回、排序、多样性控制场景中。
2. 基于匹配的深度语义模型
该类模型是一种结合内容和行为的深度语义模型,主要通过融合文本、图像、视频和音频等多模态信息,并基于用户的点击、观看或搜索等共现行为作为监督信号,构建正负样本对 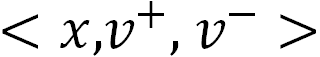
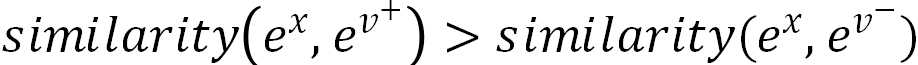
其中 e 表示样本的语义表征,x 表示视频或用户等。该类模型缺乏对节点的长距离依赖关系和结构相似性建模;但建模相对简单,模型训练后可以直接用于推理,可有效解决冷启动问题,用于召回和排序场景效果较好。
基于匹配的深度语义模型主要基于 Siamese network ( 孪生网络或双塔结构 ) 或多塔结构实现,目前业界较流行的方法包括 DSSM ( Deep Structured Semantic Model ) [5] 和 CDML [20]。DSSM 最初用于搜索建模文本的语义相关性,而 CDML 基于音频和视频帧特征,用于建模视频的语义相关性,并认为 late fusion 方式的多模态特征融合效果较好。对于视频的语义建模,在 DSSM 文本输入的基础上,我们额外引入封面图和视频两个模态的预训练语义表示,改善视频语义表征效果。类似地,CDML 还引入文本、封面图两种模态的预训练语义表示,以丰富节点信息;同时针对 CDML 仅采用 late fusion 的特征融合时机,特征交互有限且缺乏多样性的问题,我们采用 hybrid fusion 融合多种模态特征,学习更为丰富的多模态特征交叉 ( 如图 4所示 )。
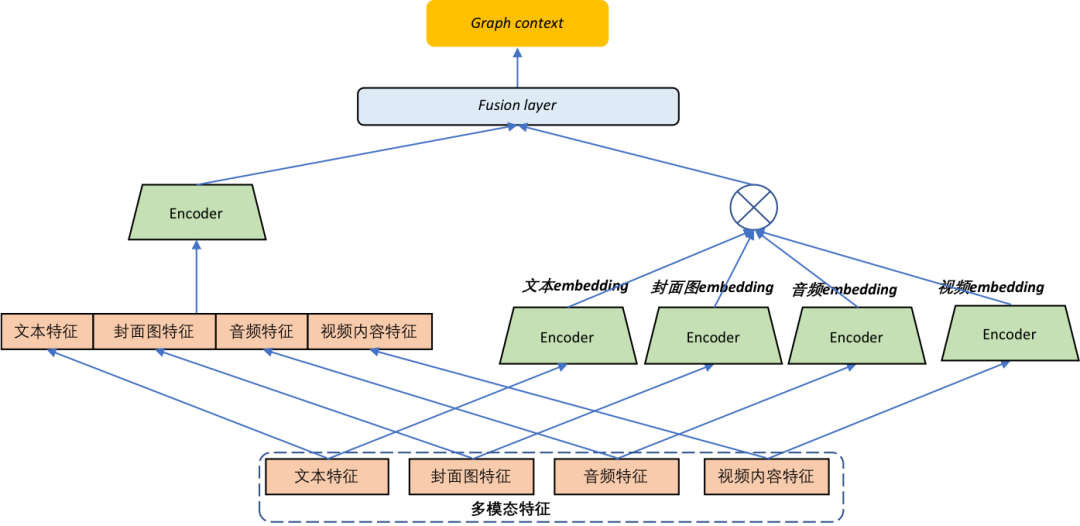
3. 基于序列的深度语义模型
该类模型是一种基于行为的深度语义模型,通过将传统的浅层网络 ( e.g. skip-gram,LSTM ) 替换为特征抽取能力更强的深度网络 ( e.g. Transformer ) 学习节点的深度语义表征。给定用户的行为序列 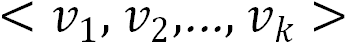
序列建模的方法主要包含三类:
基于 MDPs ( Markov decision Processes ):通过状态转移概率计算点击下一个 item 的概率,当前状态仅依赖前一个状态,模型较为简单,适用于短序列和稀疏数据场景建模;
基于 CNN:利用 CNN 捕获序列中 item 的短距离依赖关系,比如 Caser [21],易并行化;
基于 RNN:可以捕获长距离依赖关系,适用于长序列和数据丰富的场景,不过模型更复杂,不易并行化,比如 GRU4Rec [22]。
目前较为流行的序列建模方法主要基于 RNN,为解决 RNN 不易并行和效率较低等问题,我们借鉴业界经验,采用特征抽取能力更强, 且易并行的 Transformer ( 如图 5所示 ) 替换 RNN 进行序列建模,典型的工作包括 SASRec [23],Bert4Rec [24]。SASRec 使用单向 Transformer decoder ( 右半部分,N=2 ),基于上文建模下一个 item 的点击概率;而 Bert4Rec 采用双向 transformer encoder ( 左半部分,N=2 ),借鉴 BERT 的掩码思想,基于上下文预测 masked items 的点击概率。此外,由于 BERT 假设 masked items 之间相互独立,忽略了 masked items 之间的相关性,我们借鉴 XLNet [25] 的自回归 ( Auto-regressive ) 思想和排列组合语言模型 ( permutation language model ) 思想,同时建模双向 context 和 masked item 之间的相关性,提高序列建模效果。
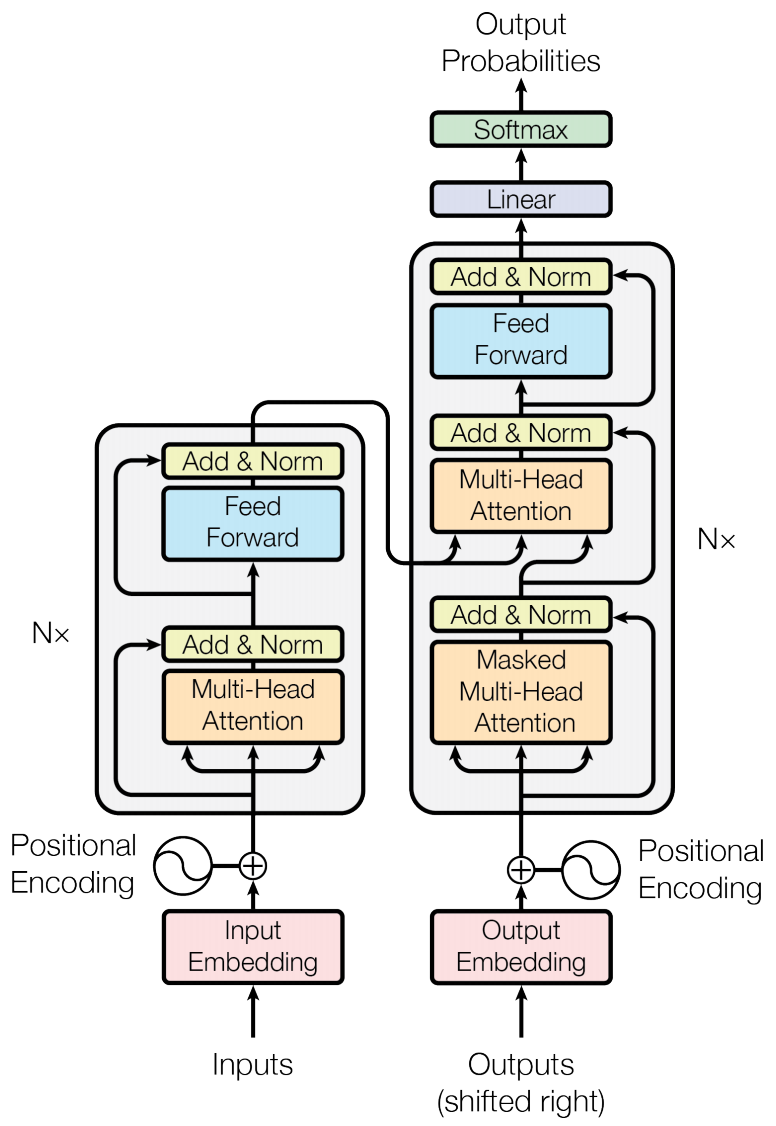
4. 基于 Graph 的深度语义模型
Graph embedding 模型 ( 又称为图嵌入或网络嵌入 ),可将图中的节点投影到一个低维连续空间,同时保留网络结构和固有属性。深度图嵌入模型在节点同构图或异构图 ( 节点类型或边类型不同 ) 的基础上,引入节点丰富的 side information 和多模态特征,并采用特征抽取能力更强的网络,学习节点的深度语义表征。该类方法建模相比前几种深度语义模型更加复杂,但可以充分利用丰富的图结构信息建模节点的高阶依赖关系。
① 引入丰富的 side information 和多模态信息
传统 graph embedding 方法主要基于图结构和某种节点序列采样策略生成序列数据,并基于 skip-gram 方式学习节点 embedding,如图 6所示。典型工作包括 DeepWalk,LINE,Node2vec,三者主要区别在于序列生成的采样策略不同。传统 graph embedding 模型将所有节点视为 ID,仅能覆盖训练集中的高频节点,无法获取新节点的 embedding。
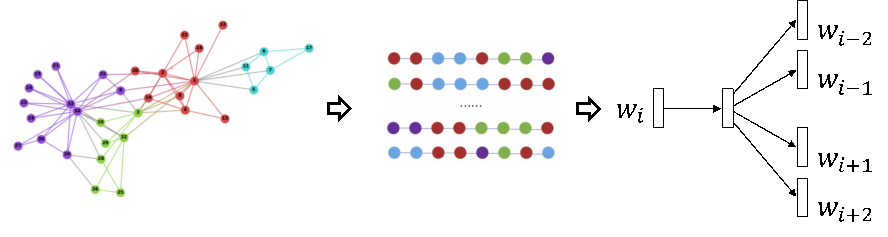
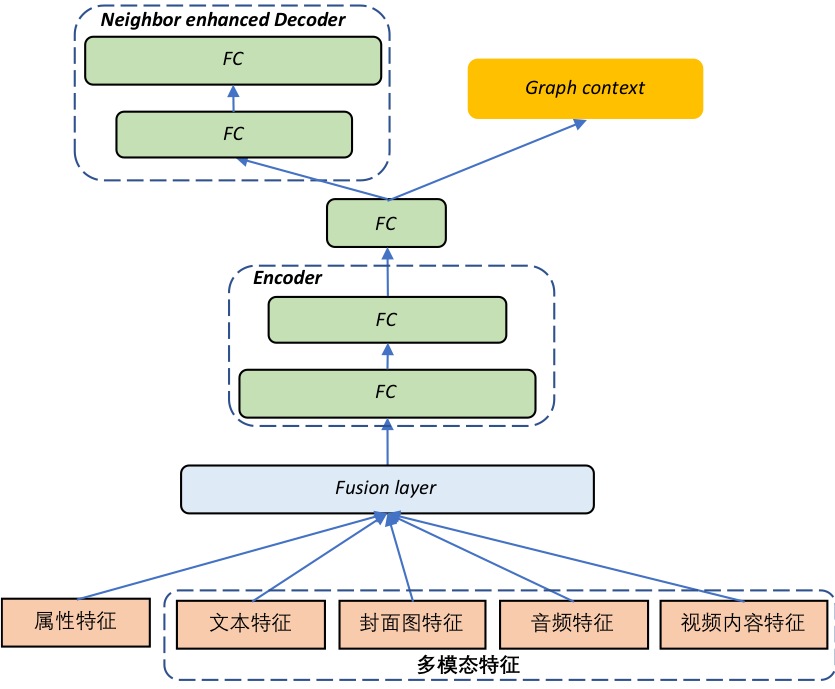
为解决新节点的冷启动问题,一方面,可以在传统图嵌入模型中引入节点的多种模态信息,另一方面,还可以充分利用节点丰富的 meta 信息 ( 比如类别,上传者等 )。属性网络 ( Attributed Network Embedding ) 在图结构的基础上,额外引入节点的属性信息,丰富节点的语义表征,使得具有相似拓扑结构和属性的节点语义更为接近。对于冷启动问题,可直接通过节点的属性 embedding 可获取新节点 embedding。EGES [26] 和 ANRL [27] 是其中的两个典型工作。其中,EGES 在 skip-gram 模型的输入中引入属性信息。ANRL 将 skip-gram 和 AE 相结合,仅使用属性特征作为节点表示,并将传统 AE 中的 decoder 替换为 neighbor enhancement decoder,使节点和其上下文节点 ( 而非其自身 ) 更为相似。EGES 和 ANRL 主要用于属性信息丰富的电商领域的图嵌入,但在视频推荐领域,除少量长视频 ( 影视剧 )、演员等具有丰富的属性外,大部分短、小视频属性较稀缺,无法直接复用。为解决该问题,我们提出多模态 ANRL,如图 7 所示,将节点的属性特征和多种模态 ( 文本、封面图、视频 ) 的预训练语义表示特征一起用于表征节点,作为模型输入。对新节点,可直接基于训练好的模型和节点自身内容 ( 即属性和多模态特征 ) 进行推理获取, 基于多模态 ANRL embedding 的近邻示例如图 8 所示。此外,知识图谱也可以视为一种丰富的 side information,可以尝试通过引入外部先验知识进一步学习更好的深度语义表示。

② 更先进的特征抽取器
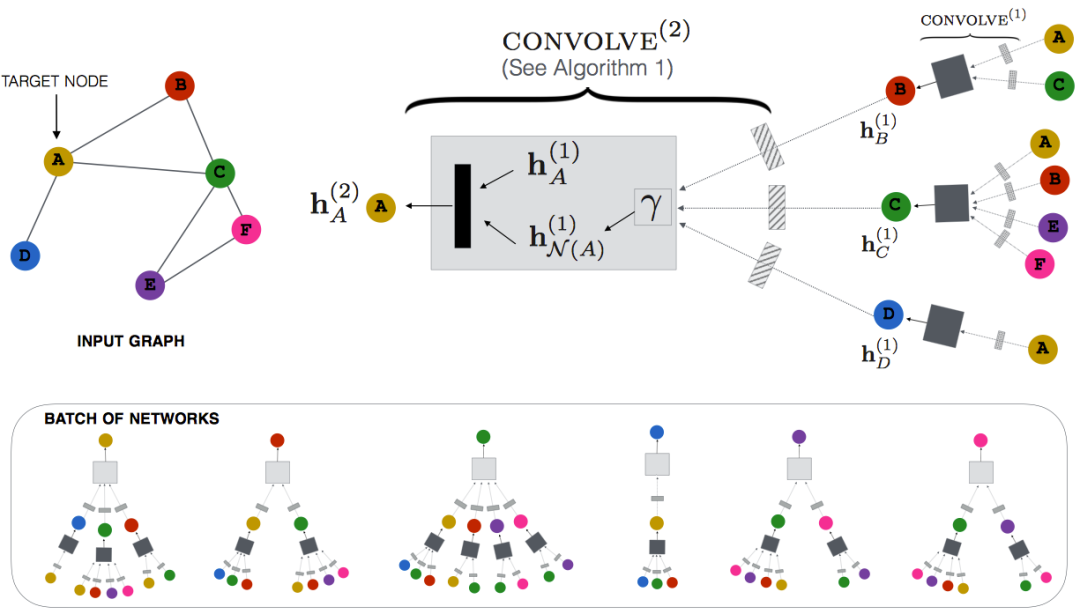
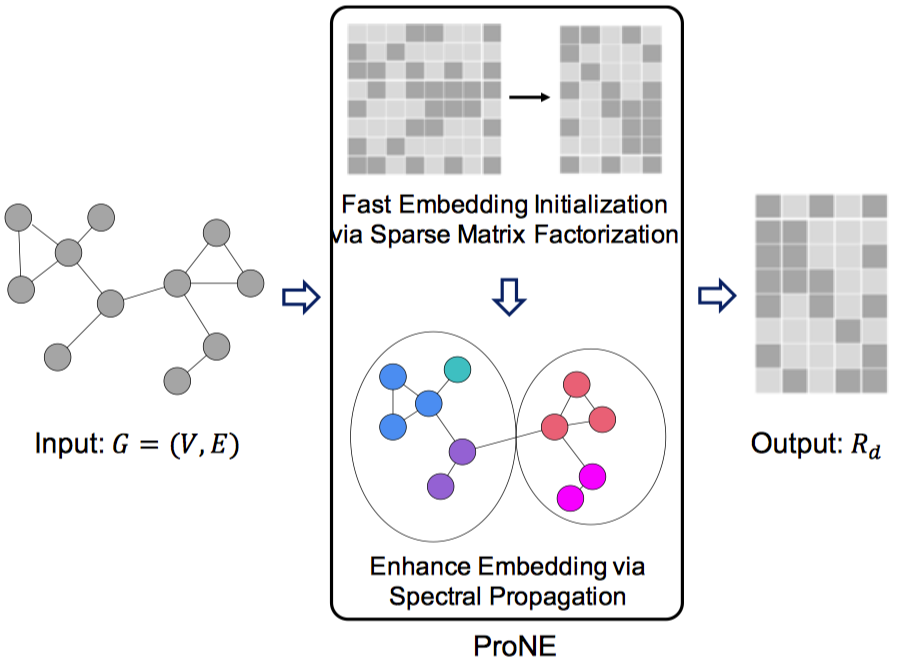
传统的图嵌入模型通常是基于图生成序列数据,并采用简单的 skip-gram 模型学习节点 embedding, 模型过于简单,特征抽取能力较弱,仅能建模局部邻居信息 ( 通常为一阶或二阶 )。图神经网络 ( GNN,Graph Neural Network ) 或图卷积网络 ( GCN,Graph Convolutional Network ) 可以直接基于图结构和节点的多模态特征,利用特征抽取能力更强的多层图卷积迭代的对节点的邻域子图进行卷积操作,聚合邻居特征 ( textual、visual 特征等 ),生成节点的深度语义表示。借鉴业界经验,我们复现了多种 GCN 模型,比如 PinSAGE [28] ( 如图 9 所示 ),ClusterGCN [29] 等。此外,我们还使用了一个在大规模图数据上非常快速和可扩展的图嵌入算法 ProNE [30]。如图 10 所示,ProNE 先将图嵌入问题转换为稀疏矩阵分解问题,高效获得具有一阶邻居信息的特征向量,作为节点的初始 embedding;然后再通过频谱传播,基于频域上的 filter 对其进行过滤从而融合高阶邻居信息作为最终的节点深度语义表示,可同时将低阶和高阶邻居信息融入节点语义表示。更重要的是,可将常见的网络嵌入算法 ( 比如 Node2vec 等 ) 生成的 embedding 作为 ProNE 中第一步的节点初始 embedding,再进行频谱传播,效果平均会提升~10%。
③ 建模多元异构图
现有方法主要基于具有单一类型节点&边的网络图 ( 同构图 ),但现实世界中大部分图都包含多种类型的节点和边,不同类型的节点往往具有不同的属性和多模态特征。比如,在搜索场景中,最简单的异构图是用户的搜索-点击二部图,具有两种类型的节点:query 和视频,视频具有丰富的属性和多模态特征;而在推荐场景也包含大量异构图,比如用户-视频、视频-圈子-内容标签、演员-角色-作品等。
传统的 graph embedding 算法会忽略图中边的类型以及节点的特征,比如 node2vec,metapath2vec,虽然 metapath2vec 可用于异构节点的表示学习,但仍然将节点视为 ID,忽略节点丰富的特征。异构图 ( HINE,Heterogenous Information Network Embedding ) 深度语义模型同时引入节点的多种模态特征,和图中节点和边类型的多样性,对不同类型的节点和边分别建模,其中多元是指图中具有多种类型的边。
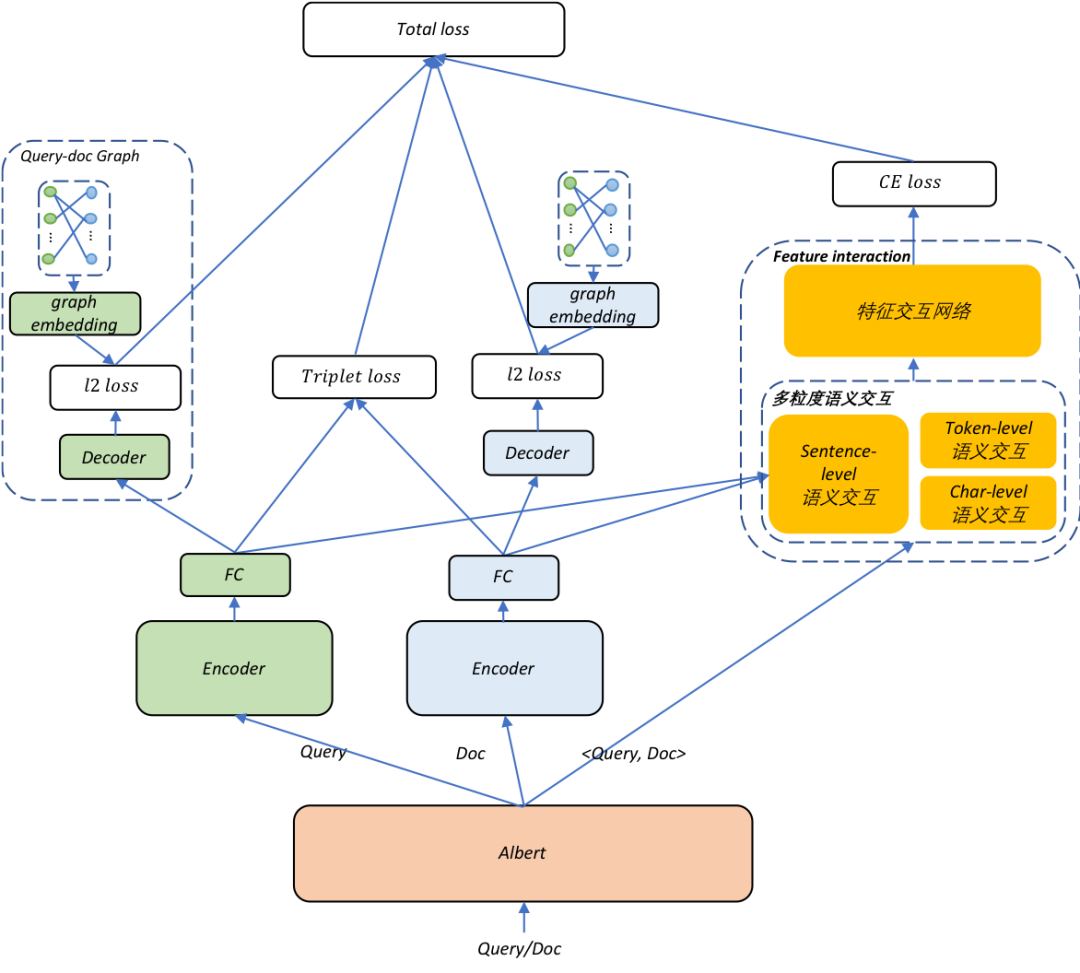
我们首先在搜索场景的语义相关性任务中进行了异构图深度语义表示学习的初步尝试。语义相关性在搜索中扮演重要角色,可用于搜索语义召回和语义相关性匹配。为衡量 query 和视频标题的语义相关性,学习 query 和视频在同一个空间的深度语义表征,我们基于搜索查询-点击异构图,通过组合 representation-based 和 interaction-based 两者思想,学习 query 和视频标题的语义相关性 embedding,模型结构如图 11 所示, 左边的 encoder 建模 query 或视频标题的深度语义表示,用于学习文本的显示语义相关性;decoder 引入行为相关性约束,用于建模隐式的语义相关性,比如 <query:李菁菁,title:欢天喜地对亲家>, 前者是后者的主要演员之一。右侧用于建模 query 和视频标题之间的多粒度交互语义。相比于 baseline,语义相关性准确率提升6%以上, 表 1给出了部分 query-title 语义相关性例子。除点击类型外,目前还在尝试引入收藏、评论、点赞等边类型,和视频类型 ( 比如长、短、小视频, 专辑和播单等 ),以及在视频侧引入封面图和视频模态特征,进行更为细致的建模。
目前也正在将该模型迁移到推荐场景中学习用户和视频、圈子以及标签等之间的同空间语义相关性。此外,最近还引入了阿里在异构图表示学习方面的工作 GATNE-I [31],支持多源异构网络的表示学习和以及具有强大特征抽取器的 HGT ( Heterogeneous Graph Transformer ) [32] 网络,并引入节点的多模态特征,尝试学习效果更好的节点深度语义表示。

1. 视频通用预训练语义表示
由于时间性能和视频语义表示预训练数据缺乏等因素,目前仅简单的通过融合视频关键帧序的图像级别特征得到视频的语义特征。后续将基于大量 video captioning 数据,借鉴 BERT 思想学习视频预训练语义模型 ( e.g.UniViLM [35] ) 抽取视频的深度语义表征。
2. 融入知识图谱先验的深度语义表示学习
视频的文本和描述中往往包含一些实体 ( 比如标题"漫威英雄内战,钢铁侠为队友量身打造制服,美队看傻了"中包含实体"漫威、钢铁侠" ),通过在文本表征中引入图谱中的实体,以及实体之间关系等先验知识 ( "钢铁侠"和"复仇者联盟" ),能够进一步提升语义表征的效果。后续将尝试在 NLP 预训练语言模型和推荐场景中引入知识图谱,分别用于提升文本语义表征效果 ( 比如 KEPLER [33] ) 和发现用户深层次用户兴趣,提升推荐的准确性,多样性和可解释性 ( e.g. KGCN [34] )。
3. 覆盖更多的业务
深度语义表示通常用于视频智能分发场景,目前已经覆盖爱奇艺的长&短&小视频、直播、图文、漫画等推荐和搜索业务;后续将持续增加爱奇艺智能制作场景的支持,为各种业务场景提供深层次语义特征。
今天的分享就到这里,谢谢大家。
感谢您的阅读,如果对你有帮助,麻烦把文章分享到朋友圈,谈谈你的感受吧~~
社群推荐:
欢迎加入 DataFunTalk 推荐算法交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:datafun-coco ),回复:推荐算法,逃课儿会自动拉你进群。
参考文献:
[1] Yoshua Bengio, et al. A Neural Probabilistic Language Model. The Journal of Machine Learning Research, 3:1137–1155, 2003.
[2] Tomas Mikolov, et al. Efficient Estimation of Word Representations in Vector Space. In International Conference on Learning Representations (ICLR), 2013.
[3] Ashish Vaswani, et al. Attention Is All You Need. In International conference on Neural Information Processing Systems (NeurIPS), 2017.
[4] Thomas N. Kipf. et al. Semi-Supervised Classification with Graph Convolutional Networks. In International Conference on Learning Representations (ICLR), 2017.
[5] Po-Sen Huang, et al. Learning Deep Structured Semantic Models for Web Search using Clickthrough Data. In ACM International Conference on Information and Knowledge Management (CIKM), 2013.
[6] Oren Barkan, et al. Item2Vec: Neural Item Embedding for Collaborative Filtering. arXiv preprint, arXiv: 1603.04259v3, 2017.
[7] Aditya Grover, et al. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2016.
[8] Jacob Devlin, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint, arXiv: 1810.04805v2, 2019.
[9] Zhenzhong Lan, et al. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In International Conference on Learning Representations (ICLR), 2020.
[10] David M. Blei, et al. Latent Dirichlet Allocation. The Journal of Machine learning Research, 3:993-1022, 2003.
[11] Lingfei Wu, et al. Word Mover’s Embedding: From Word2Vec to Document Embedding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018.
[12] Casper Hansen, et al. Contextually Propagated Term Weights for Document Representation. In International Interest Group on Information Retrieval (SIGIR), 2019.
[13] Mingxing Tan, et al. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), 2019.
[14] Trieu H. Trinh, et al. Selfie: Self-supervised Pretraining for Image Embedding. arXiv preprint, arXiv 1906.02940, 2019.
[15] Shawn Hershey, et al. CNN Architectures for Large-Scale Audio Classification. In International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2017.
[16] Zhou Yu, et al. Multi-modal Factorized Bilinear Pooling with Co-Attention Learning for Visual Question Answering. In International Conference on Computer Vision (ICCV), 2017.
[17] Zhou Yu, et al. Beyond Bilinear: Generalized Multimodal Factorized High-order Pooling for Visual Question Answering. IEEE Transactions On Neural Networks And Learning Systems, 26:2275-2290, 2015.
[18] Jin-Hwa Kim, et al. Bilinear Attention Networks. In International conference on Neural Information Processing Systems (NeurIPS), 2018.
[19] Francois Chollet. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv preprint, arXiv: 1610.02357, 2017.
[20] Joonseok Lee, et al. Collaborative Deep Metric Learning for Video Understanding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2018.
[21] Jiaxi Tang, et al. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. In ACM International Conference on Web Search and Data Mining (WSDM), 2018.
[22] Balazs Hidasi, et al. Session-based Recommendations with Recurrent Neural Networks. In International Conference on Learning Representations (ICLR), 2016.
[23] Wang-Cheng Kang, et al. Self-Attentive Sequential Recommendation. In IEEE International Conference on Data Mining (ICDM), 2018.
[24] Fei Sun, et al. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In ACM International Conference on Information and Knowledge Management (CIKM), 2019.
[25] Zhilin Yang, et al. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In International conference on Neural Information Processing Systems (NeurIPS), 2019.
[26] Jizhe Wang, et al. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2018.
[27] Zhen Zhang, et al. ANRL: Attributed Network Representation Learning via Deep Neural Networks. In Proceedings of the 27th International Joint Conference on artificial Intelligence (IJCAI), 2018.
[28] Rex Ying, et al. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2018.
[29] Wei-Lin Chiang, et al. Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2019.
[30] Jie Zhang, et al. ProNE: Fast and Scalable Network Representation Learning. In Proceedings of the 28th International Joint Conference on artificial Intelligence (IJCAI), 2019.
[31] Yukuo Cen, et al. Representation Learning for Attributed Multiplex Heterogeneous Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2019.
[32] Ziniu Hu, et al. Heterogeneous Graph Transformer. In Proceedings of the World Wide Web Conference (WWW), 2020.
[33] Xiaozhi Wang, et al. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. arXiv preprint, arXiv: 1911.06136, 2020.
[34] Hongwei Wang, et al. Knowledge Graph Convolutional Networks for Recommender Systems. In Proceedings of the World Wide Web Conference (WWW), 2019.
[35] Huaishao Luo, et al. UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation. arXiv preprint, arXiv: 2002.06353, 2020.

关于我们:

一个在看,一段时光!👇




