![]()
作者:Michael Armanious
翻译:欧阳锦
校对:阿笛
本文通过一个A/B测试的实例,介绍了贝叶斯方法的各种优点和具体的实现方法,同时也将贝叶斯推断方法与传统的频率推断估计进行了对比。
本文以一种直观的方式介绍了A/B测试、贝叶斯方法的优点以及它的具体实现方法。
![]()
“批判性思维是一个活跃而持续不断的过程。它要求我们所有人都像贝叶斯主义者那样思考,随着新信息的到来更新我们的知识。”
—— Daniel J. Levitin,说谎的实地指南:信息时代的批判性思维
在深入研究使用贝叶斯估计方法之前,我们需要了解一些概念。这些概念包括:
推论统计
贝叶斯主义者与频率主义者
A / B测试
概率分布
推论统计是指根据人口总体样本推断某个总体人口的某些信息,而不是描述整个人口总体的描述性统计信息。
当涉及推理统计时,主要有两种哲学:频率推断和贝叶斯推断。众所周知,频率推断方法是更传统的统计推断方法,因此在大多数统计课程(尤其是入门课程)中都进行了更多的研究。然而,许多人认为贝叶斯方法更接近于人类自然地认识概率的方式。
![]()
贝叶斯方法包含了根据新证据去改变一个人的想法。例如,你去看医生是因为你感觉不适,并且认为自己患有某种疾病。几个医生对你进行检查,他们对你的症状都有不同的看法。这些被称为先验想法(先验概率)。经过检查后,他们会对你进行血液检查。根据测试,他们排除了最初预期的某些可能的疾病,并根据结果更新了自己的想法。这种新的想法称为后验想法(后验概率)。
2. 选择一个概率分布来表示数据。这成为了你的似然函数。
3. 考虑你对似然函数参数的主观想法去选择一个先验分布。
4. 通过使用贝叶斯方法使用后验数据更新先验分布,以获得后验分布。后验分布是一种概率分布,它描述了观察数据后你对参数的更新想法。
我知道这里有很多专业术语,但我会尽力解释例子中的所有内容。
随着证据实例的数量接近无穷大(即样本量越大),贝叶斯结果与频率推断方法结果越一致。随着证据实例的数量变少(即样本量越小),推断就变得越不稳定。这导致频率估计具有更大的方差,从而导致更大的置信区间。但是,由于贝叶斯方法涉及合并先验概率和回归概率,因此我们可以保留不确定性。先验越合适,结果的偏差就越小。而且,频率推断估计经常导致不收敛、不可接受的参数解和不准确的估计。另外,频率推断方法假设概率是事件的长期发生频率,因此依赖于渐近理论[1]。
如前所述,贝叶斯学说接近于人类的思维方式,这意味着推理可以更容易解释。我们将通过A/B测试示例来证明贝叶斯方法的直观性。
![]()
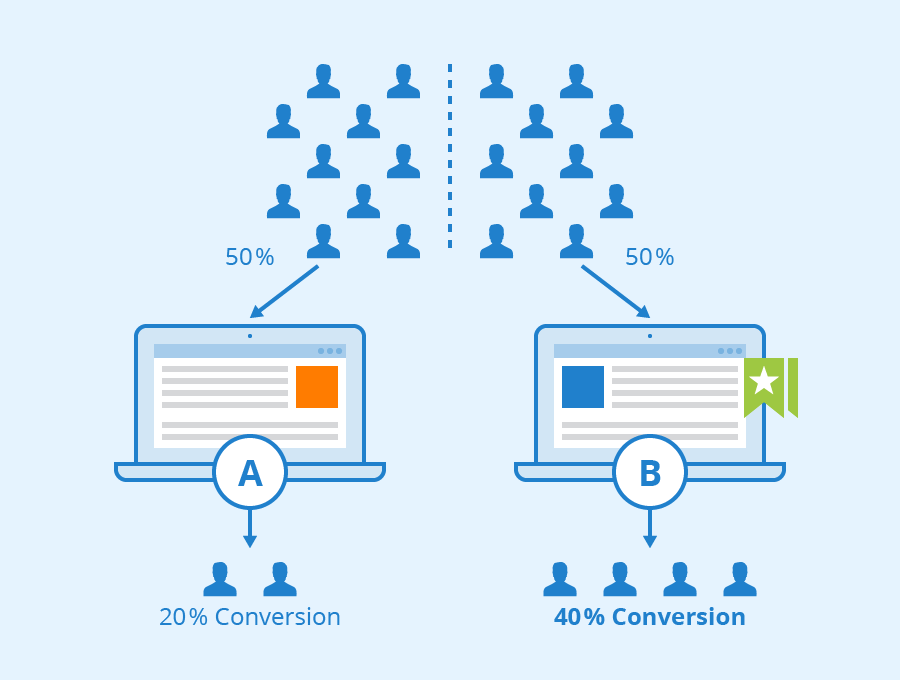
AB 测试 —作者: Seobility —证书: CC BY-SA 4.0
A / B测试是一种广泛使用的研究方法,用于比较单一变量的两个变体(A和B)并找出差异。它有许多应用,但是最常用于比较网站、应用程序的布局。频率推断方法通过计算Z值,p值等其他值进行假设检验。
在此示例中,我们将对受欢迎的移动益智游戏Cookie Cats进行A/B测试。你可以在此处
(https://www.kaggle.com/yufengsui/mobile-games-ab-testing)
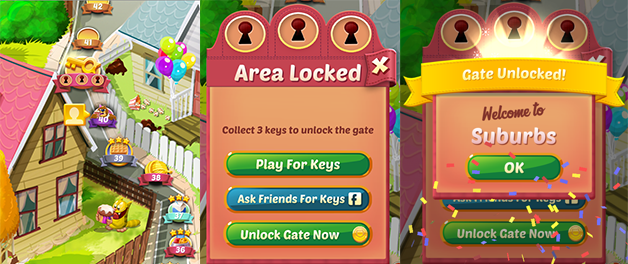
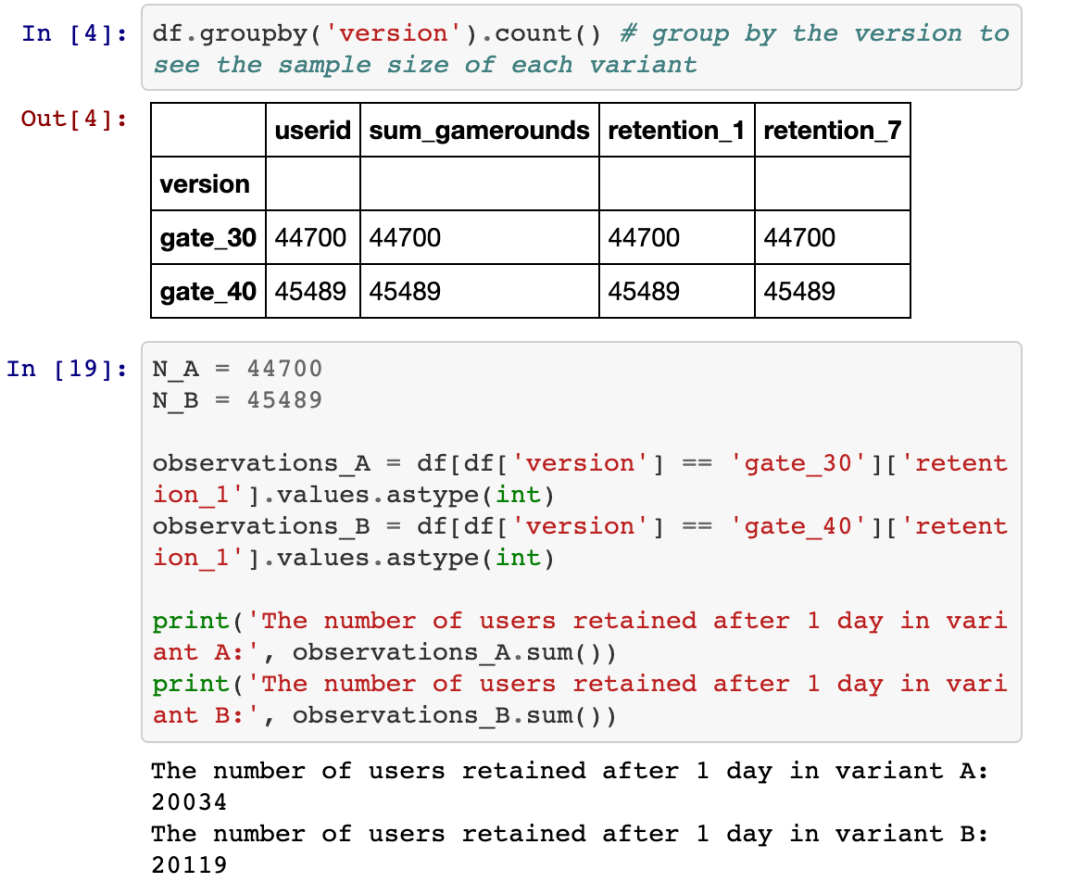
找到数据集。在此游戏中,玩家会进入关卡,有时他们到达闸门,这使得玩家等待一定时间或进行应用内购买项目。该应用程序的创建者希望根据闸门的两个不同位置查看用户的保留率:第30级闸门和第40级闸门。
![]()
游戏截屏
![]()
![]()
![]()
![]()
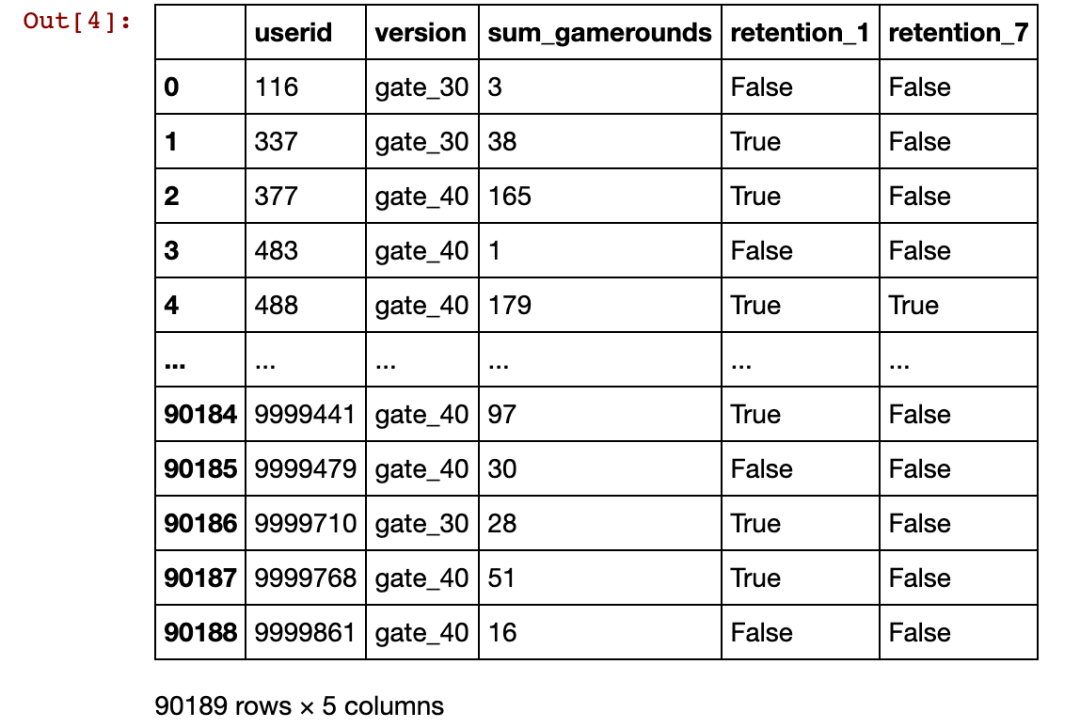
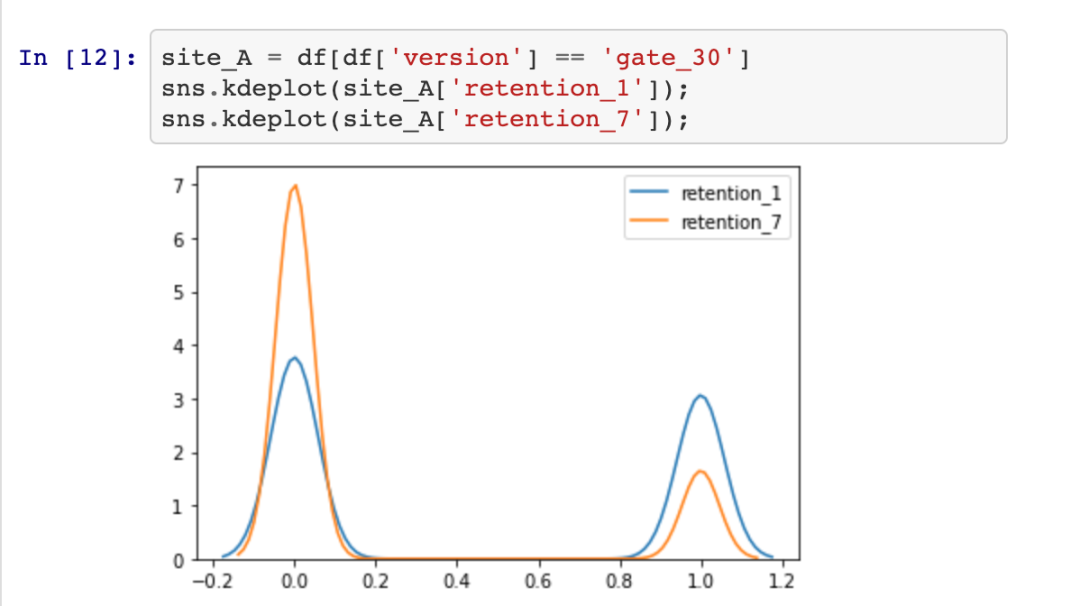
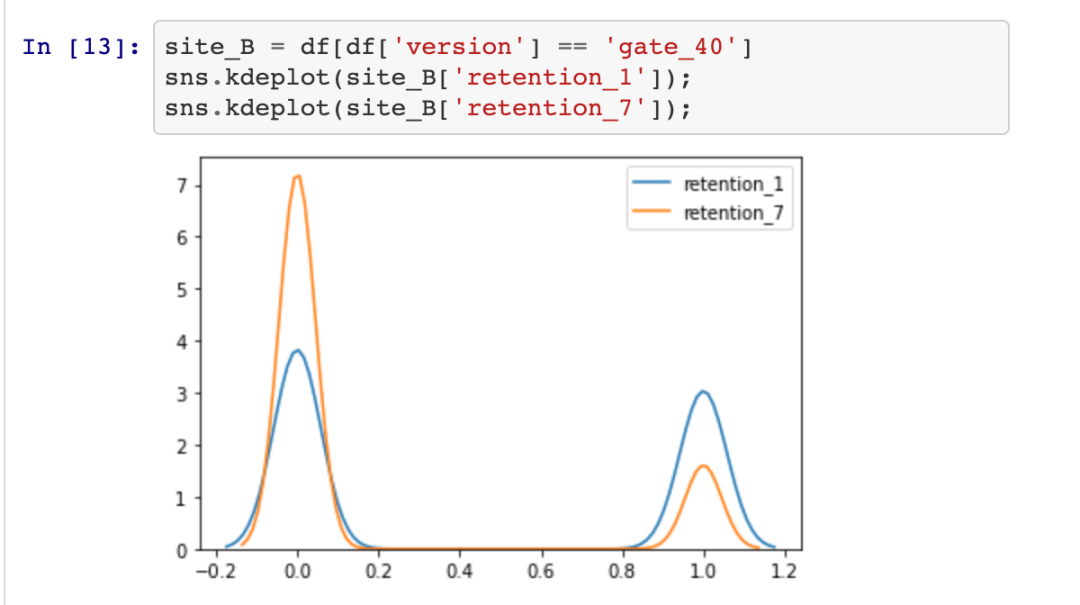
通过绘制数据(数据已经被清洗)并查看响应变量的分布图来开始我们的分析。我们有两个响应变量,我们将分别对它们进行分析。响应变量分别是是1天和7天的保留率。当用户变量A玩了30轮或更多轮游戏时,1天保留时间为True,否则为False。对于变量B,当用户玩了40轮或更多轮游戏时,1天保留时间为True,否则为False。这种保留可能性可以表示为伯努利分布,可以将其视为返回布尔值(是或否)的任何单个试验的可能结果集的分布。
选择你先验分布可能很棘手。通常,样本量越小,你应该获得的先验分布信息越丰富,从而得到更准确的结果。例如,如果你的样本量很大,则可以选择信息量较弱的先验分布,从而获得与选择信息量较大的先验分布相似的结果。
在你有确凿证据时,信息先验可以表达有关变量的明确信息。共轭先验与后验分布具有相同的概率分布族,它们也可作为信息先验[2]。
弱信息先验表示了有关变量的部分信息,并用于将推理保持在合理的范围内(将其视为防止过度拟合的原因)。
非信息先验表达了关于变量的模糊信息,并且会增加欠拟合的可能性。
应该根据现有证据的级别选择这些先验条件。这是非常直观的,因为通常,你拥有的证据越多,对初始假设的依赖就越少。
![]()
![]()
![]()
![]()
2. 然后,我们需要获取每个变体的观察值;它存储为0和1的数组。
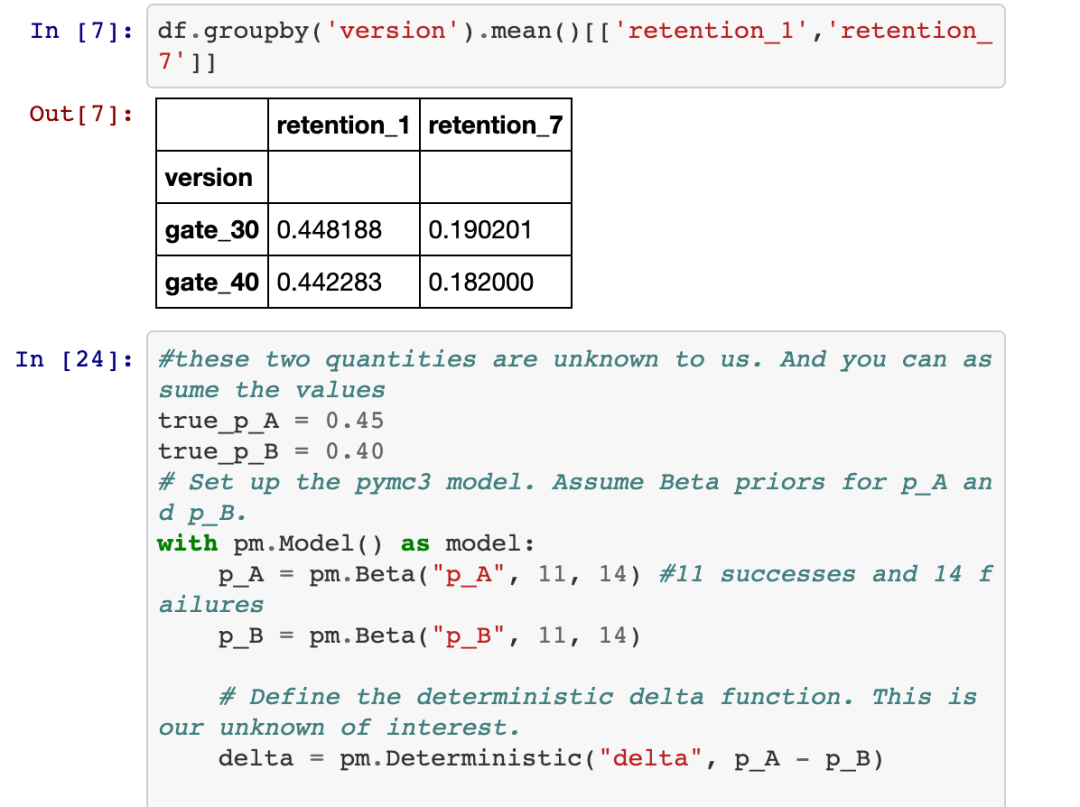
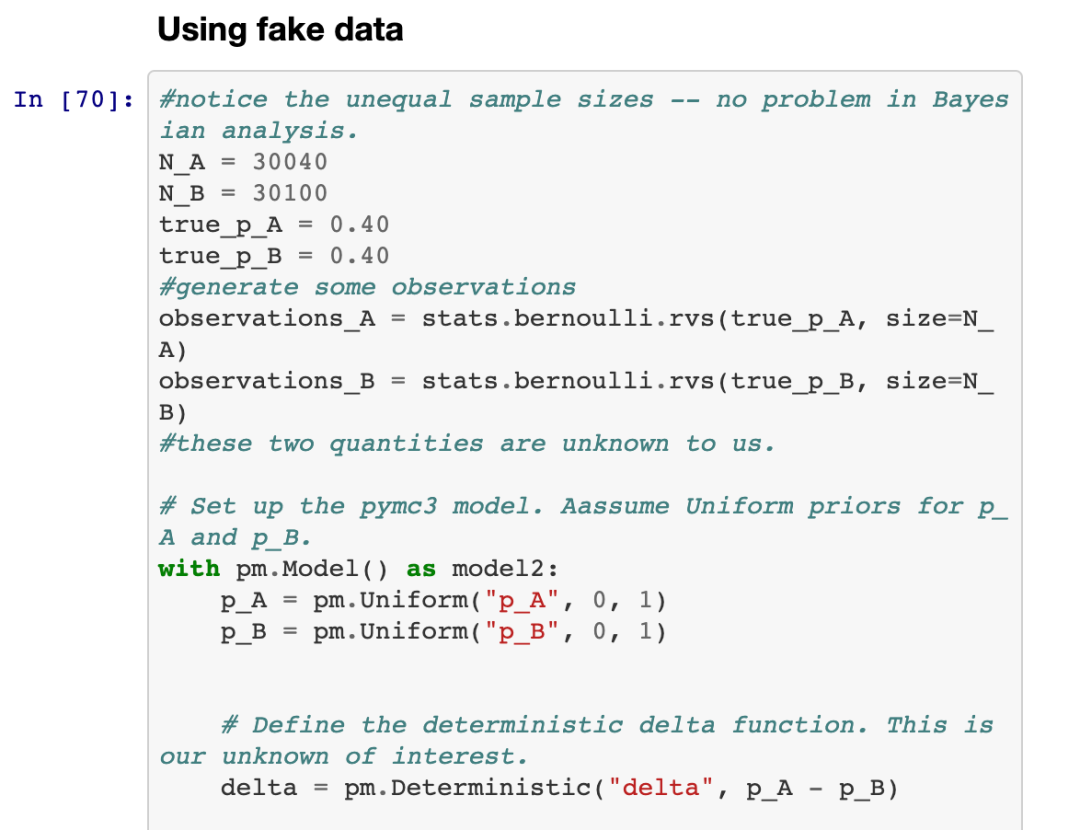
3. 假设两个变量的保留率的真实概率。你的先验知识越强,信息量越大,你对假设的依赖就越少。后验主要由证据决定,而不是任何原始假设,前提是原始假设承认证据暗示的可能性。在此示例中,我使用了不太可能是真实概率的值(因为它们与样本均值不同)。
4. 使用pyMC3
(https://docs.pymc.io/)
创建一个模型,并假设不同变量的先验分布(这些先验分布可以彼此不同)。 在此示例中,我们使用Beta分布作为先验,因为它是伯努利和二项式似然函数的共轭先验。Beta分布的参数越大,你应该越有信心。参数是成功和失败。可以使用的弱信息先验的一个例子是具有参数[0,1]的均匀分布。你可以对两者进行测试,并发现最终结果大致相同,因为我们有较大的样本量。
6. 用各自的先验分布定义两个变量的似然函数作为参数。
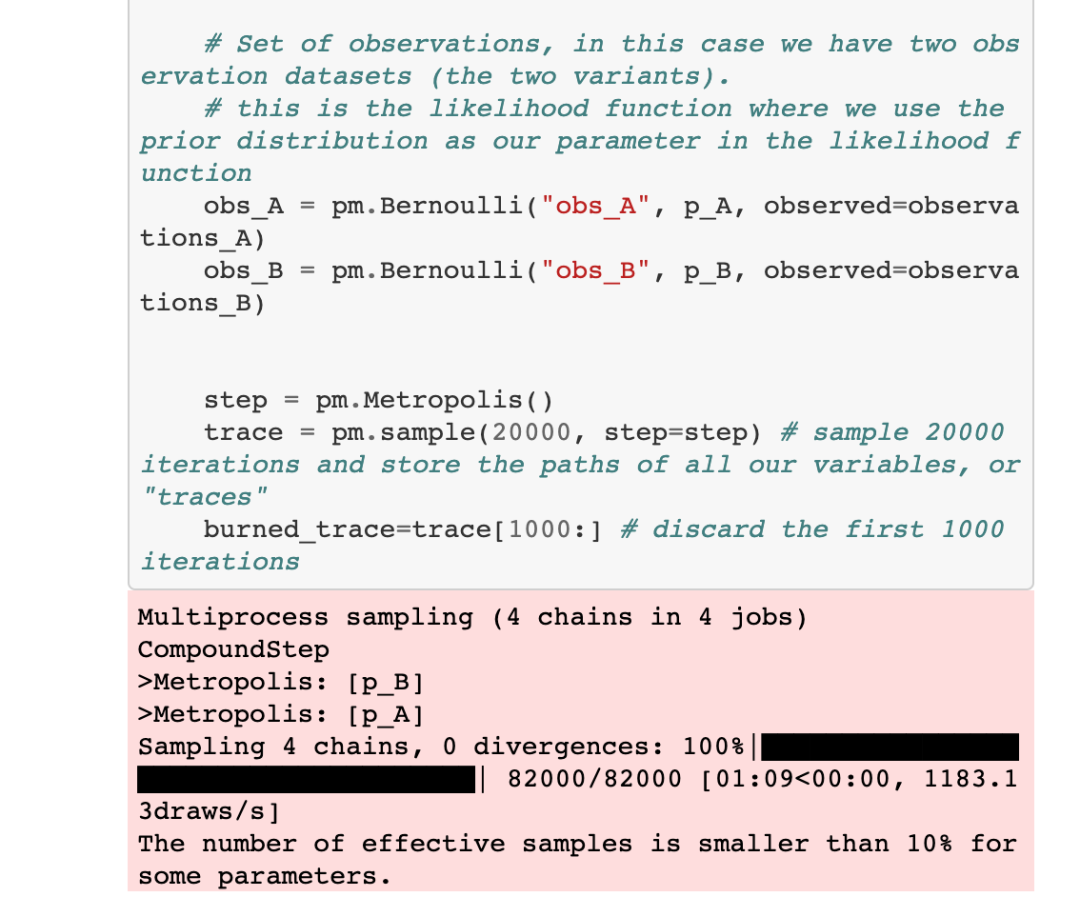
7. 使用MCMC算法对20,000次(或任意数量)迭代进行采样,并丢弃前1000次迭代,因为这些迭代通常与我们感兴趣的最终分布无关。
结果
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
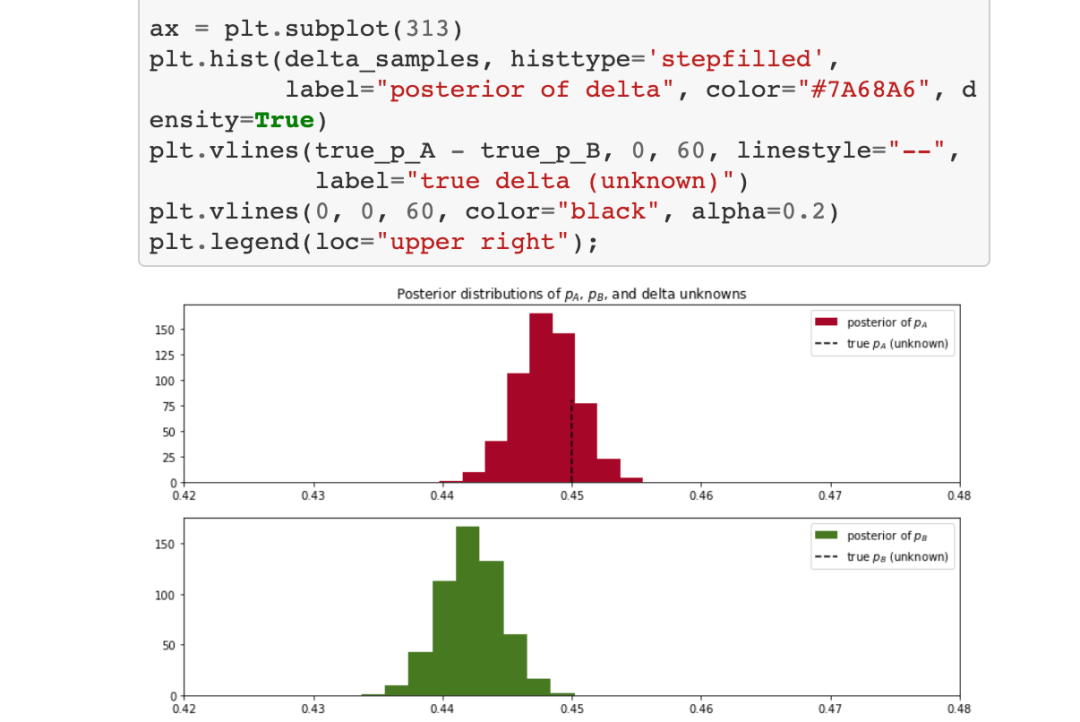
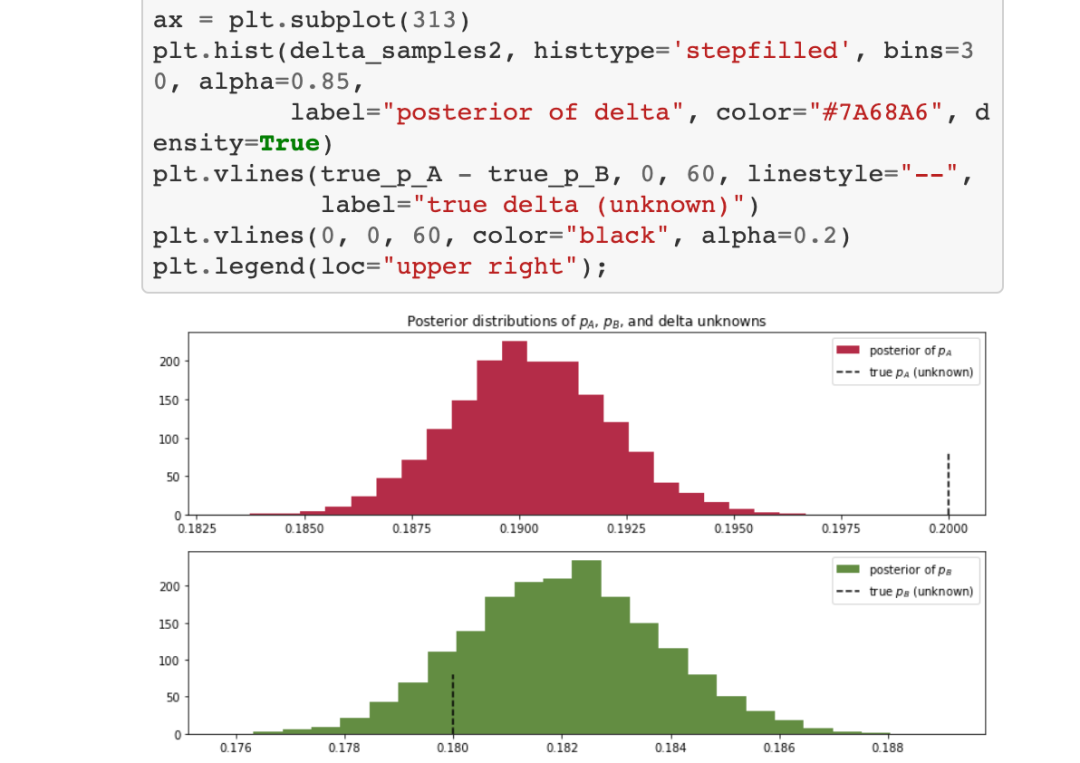
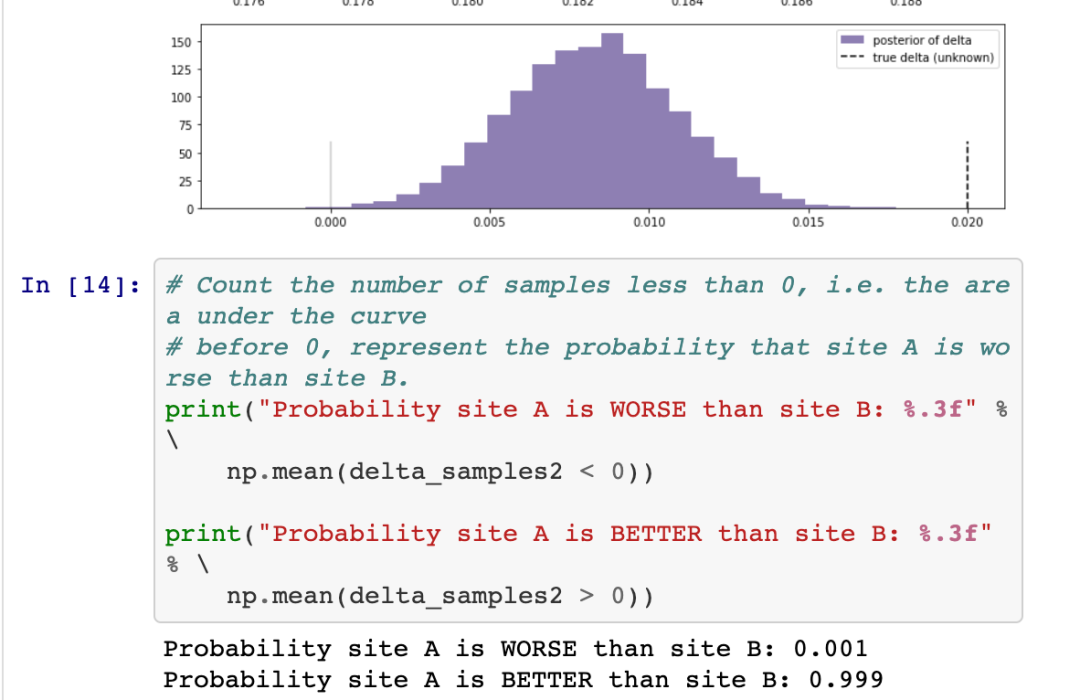
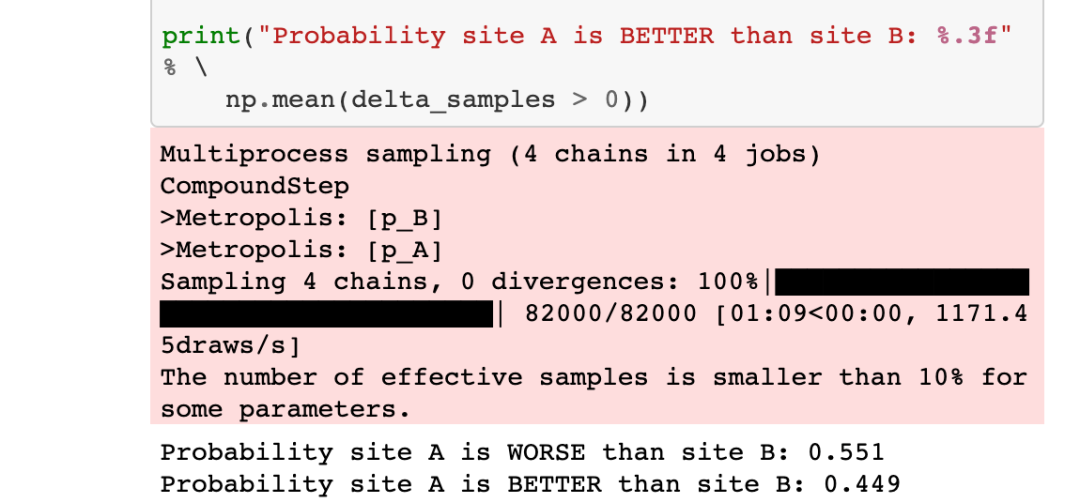
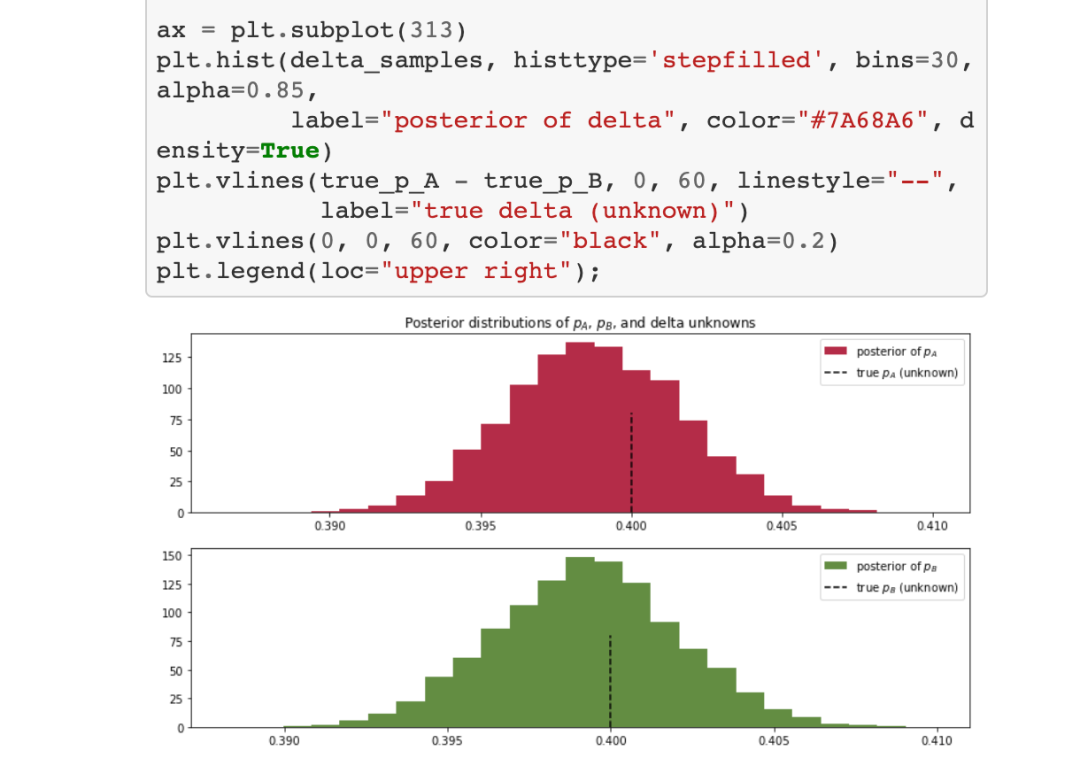
在图中,我们可以看到变量的后验分布和变量的差异。分布越宽,我们对p(A)和p(B)的真实值的把握就越小。真实变量的不确定性与样本量的大小成正比。使用贝叶斯方法的好处是现在我们可以量化不确定性了。此外,我们可以看到,delta后验分布的大部分都在delta = 0以上,这意味着变量A可能比变量B更好。
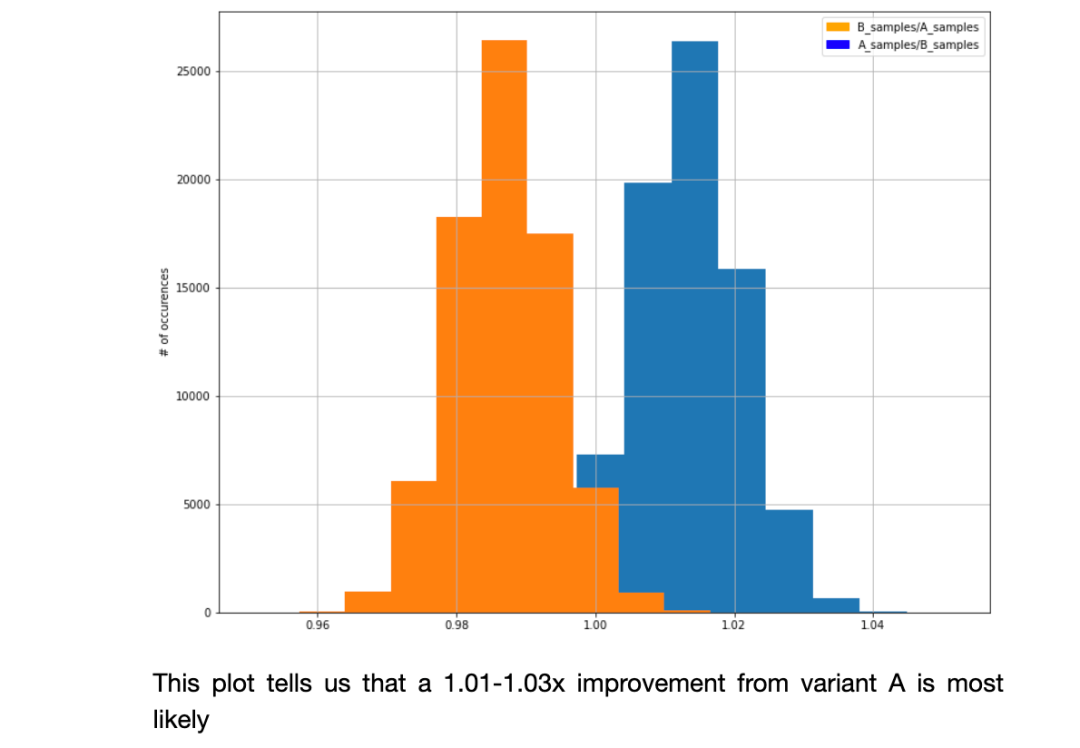
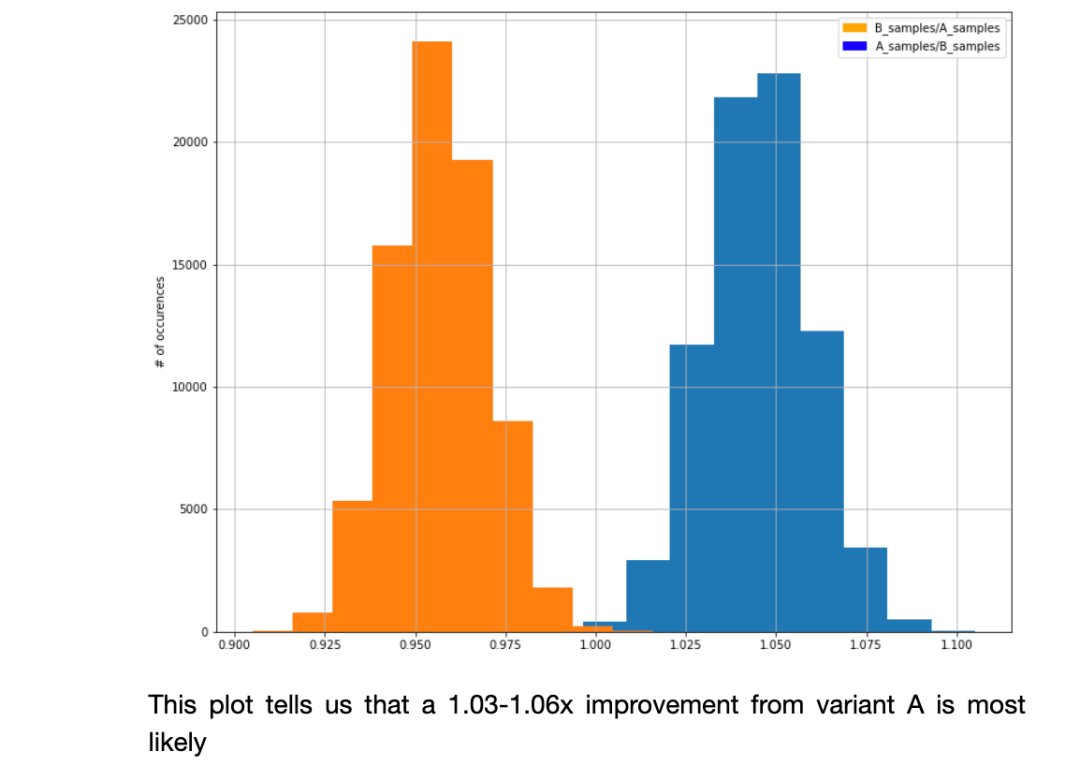
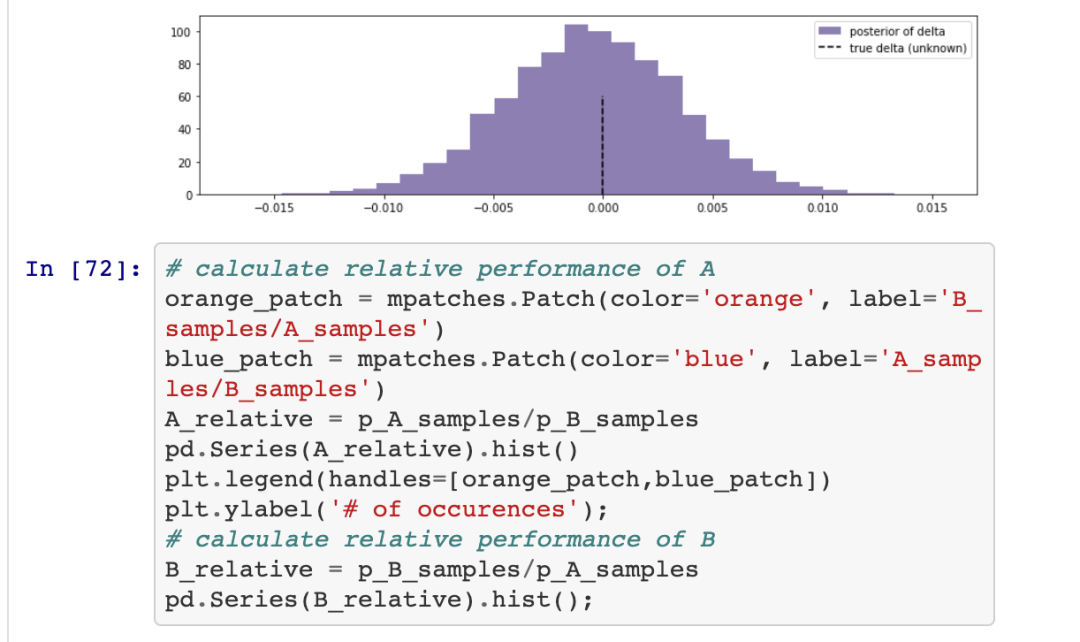
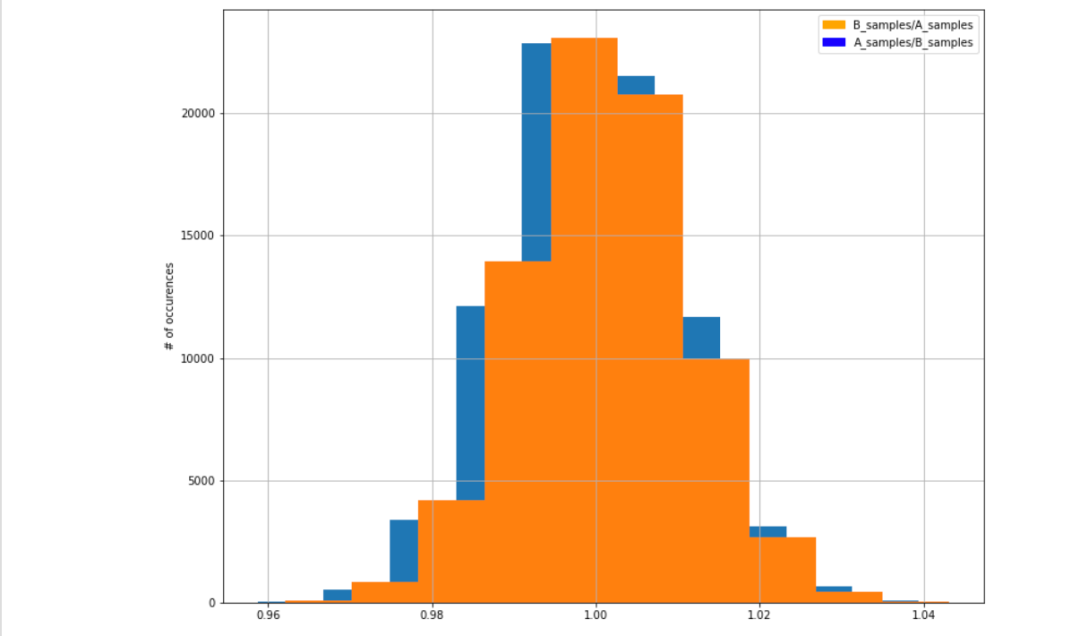
我们还可以计算变量的相对性能并绘制它们。在该图中,你可以从变量A中看出可能有1%-3%的改善。
使用贝叶斯方法进行A / B测试有很多原因。但是,“没有免费的午餐”。这句话适用于所有事物。很棒的是你可以将两种方法都应用于A / B测试,并查看它们的比较方式以及每种方法的可解释性。
样本数量无关紧要
量化不确定性
它非常直观,可以很容易解释
没有无用的p值或Z值
很自然
免责声明:实际上,我对贝叶斯估计并不陌生,可惜的是,我大部分都是以传统方式学习的。
https://github.com/michaelarman/Bayesian_A-B_testing
Davidson-Pilon, C. (2016). Bayesian methods for hackers: Probabilistic programming and bayesian inference.
Sanne C. Smid, Daniel McNeish, Milica Miočević & Rens van de Schoot (2020) Bayesian Versus Frequentist Estimation for Structural Equation Models in Small Sample Contexts: A Systematic Review, Structural Equation Modeling: A Multidisciplinary Journal, 27:1, 131–161, DOI: 10.1080/10705511.2019.1577140 [1]
Gutierrez-pena, Eduardo, and Pietro Muliere. “Conjugate Priors Represent Strong Pre-Experimental Assumptions.” Blackwell PublishingLtd, 9600 Garsington Road, Oxford OX4 2DQ, UK, 2004.[2]
Why you should try the Bayesian approach of A/B testing
https://towardsdatascience.com/why-you-should-try-the-bayesian-approach-of-a-b-testing-38b8079ea33a
欧阳锦,我是一名即将去埃因霍芬理工大学继续攻读数据科学专业的硕士生。本科毕业于华北电力大学,自己喜欢的科研方向是隐私安全中的数据科学算法。有很多爱好和兴趣(摄影、运动、音乐),对生活中的事情充满兴趣,是个热爱钻研、开朗乐观的人。为了更好地学习自己喜欢的专业领域,希望能够接触到更多相关的事物以开拓自己的眼界和思路。
![]()
![]()