Transformer在深度推荐系统中的应用及2019最新进展
作者:Alex-zhai
来源:https://zhuanlan.zhihu.com/
p/85825460
整理:深度传送门
最近基于Transformer的一些NLP模型很火(比如BERT,GPT-2等),因此将Transformer模型引入到推荐算法中是近期的一个潮流。Transformer比起传统的LSTM、GRU等模型,可以更好地建模用户的行为序列。本文主要整理Transformer在推荐模型中的一些应用以及在2019年的最新进展。
Self-Attentive Sequential Recommendation, ICDM 2018
模型结构
问题定义:模型输入是用户 u 的一个历史交互序列: 

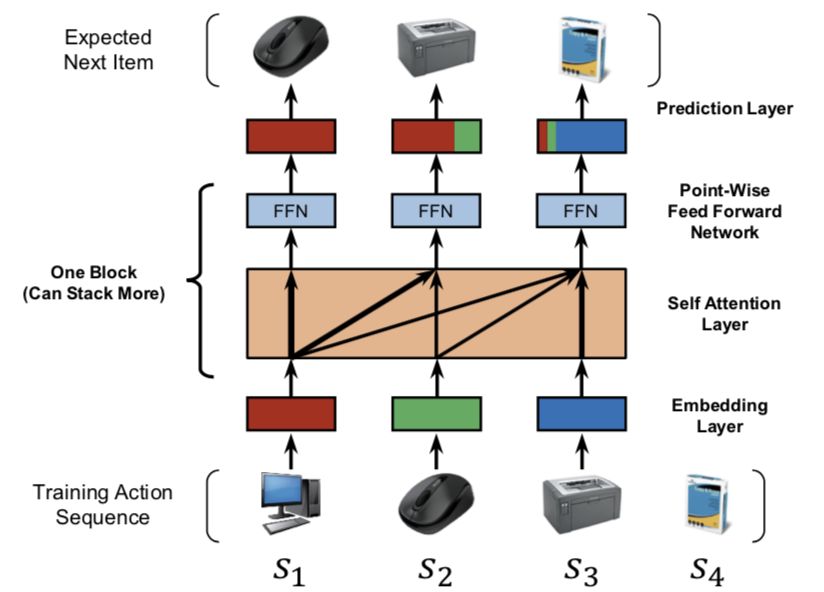
Embedding层
将输入序列 
位置embedding:因为self-attention并不包含RNN或CNN模块,因此它不能感知到之前item的位置。本文输入embedding中也结合了位置Embedding P信息,并且位置embedding是可学习的。
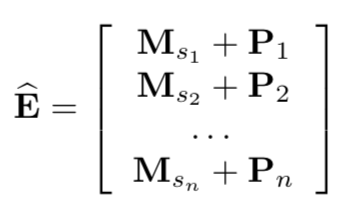
Self-Attention层
Transformer中Attention的定义为:
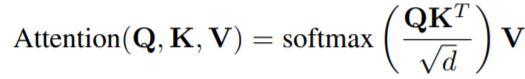
本文中,self-attention以embedding层的输出作为输入,通过线性投影将它转为3个矩阵,然后输入attention层:
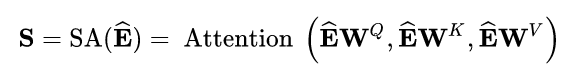
为了避免在预测i时刻的item时用到后续时刻的信息,本文将符合(j > i)条件的 

Point-wise前馈网络
尽管self-attention能够用自适应权重并且聚焦之前所有的item,但最终它仍是个线性模型。可用一个两层的point-wise前馈网络去增加非线性同时考虑不同隐式维度之间的交互:
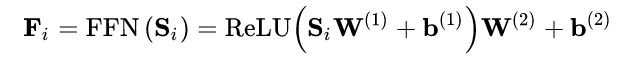
预测层
最后采用MF层来预测相关的item i:
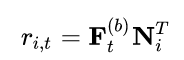
其中 
显式用户建模
为了提供个性化推荐,当前主要有两种方法:学习显式的用户embedding表示用户偏好(MF,FPMC,Caser);考虑用户之前的行为,通过访问过的item的embedding推测隐式的用户embedding。本文采用第二种方式,同时额外在最后一层插入显式用户embedding 
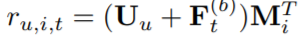
但是通过实验发现增加显式用户embedding并没有提升效果。
Next Item Recommendation with Self-Attention, 2018
模型结构
本文亮点是同时建模用户短期兴趣(由self-attention结构提取)和用户长期兴趣。
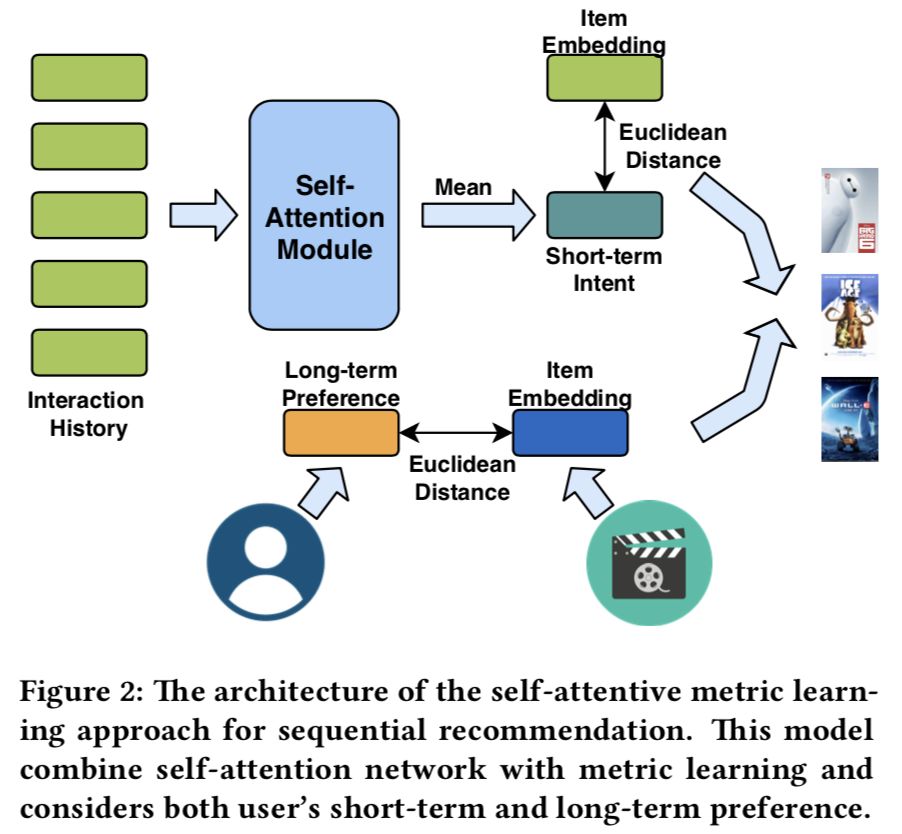
短期兴趣
其短期兴趣建模过程如下:假定使用用户最近的 L 条行为记录来计算短期兴趣。可使用X表示整个物品集合的embedding,那么,用户 u 在 t 时刻的前 L 条交互记录所对应的embedding表示如下:
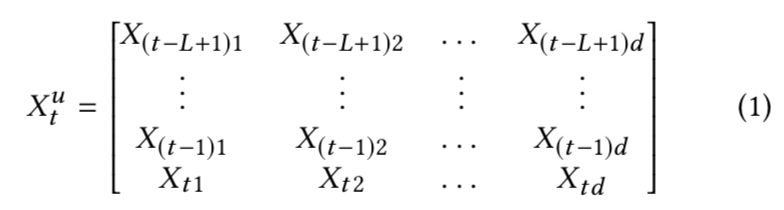
其中每个item的embedding维度为d,将 
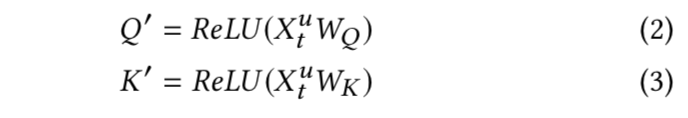
这里需要注意和传统transformer的不同点:
计算softmax前先掩掉
矩阵的对角线值,因为对角线其实是item与本身的一个内积值,容易给该位置分配过大的权重。
没有将输入
乘以
得到
,而是直接将输入
乘以softmax算出来的score。
直接将embedding在序列维度求平均,作为用户短期兴趣向量。
 矩阵的对角线值,因为对角线其实是item与本身的一个内积值,容易给该位置分配过大的权重。
矩阵的对角线值,因为对角线其实是item与本身的一个内积值,容易给该位置分配过大的权重。 得到
得到  ,而是直接将输入
,而是直接将输入长期兴趣
self-attention模块只使用用户最近的L个交互商品作为用户短期的兴趣。那么怎么建模用户的长期兴趣呢?可认为用户和物品同属于一个兴趣空间,用户的长期兴趣可表示成空间中的一个向量,而某物品也可表示为成该兴趣空间中的一个向量。那如果一个用户对一个物品的评分比较高,说明这两个兴趣是相近的,那么它们对应的向量在兴趣空间中距离就应该较近。这个距离可用平方距离表示。
综合短期兴趣和长期兴趣,可得到用户对于某个物品的推荐分,推荐分越低,代表用户和物品越相近,用户越可能与该物品进行交互:
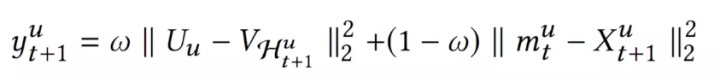
模型采用pair-wise的方法训练,即输入一个正例和一个负例,希望负例的得分至少比正例高γ,否则就发生损失,并在损失函数加入L2正则项:
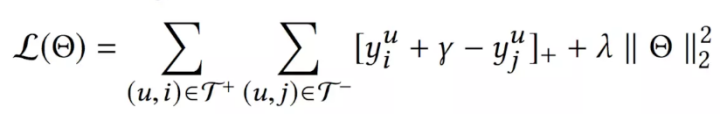
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, CIKM 2019
模型架构
显而易见,本文的亮点是结合使用预训练的BERT模型。
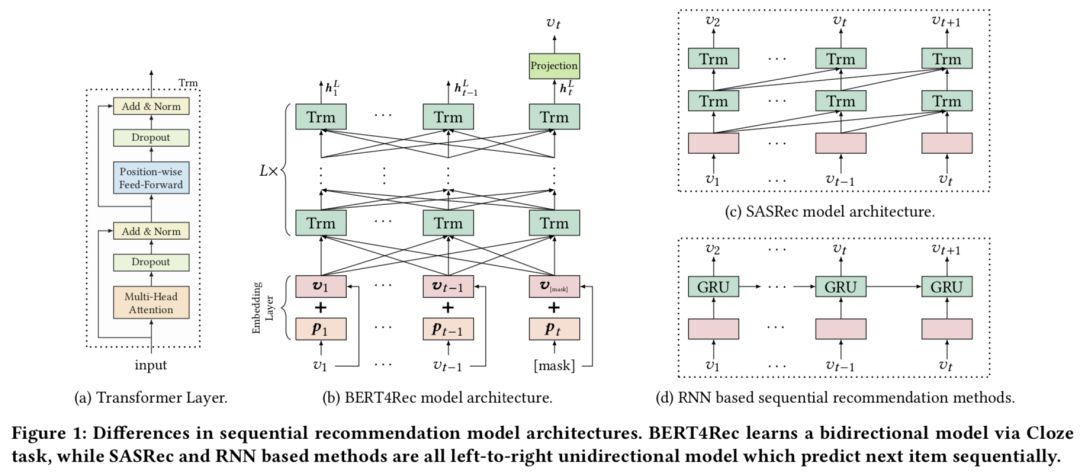
Embedding Layer
模型的输入是用户历史交互序列,对交互序列中的每一个物品 i,其Embedding包含两部分,一部分是物品的Embedding,用vi表示;另一部分是位置信息的Embedding,用 pi 表示。这里的pi是可学习的。
Transformer Layer
主要包括Multi-Head Self-Attention层和Position-Wise Feed-Forward Network,其中Multi-Head Self-Attention计算过程如下:
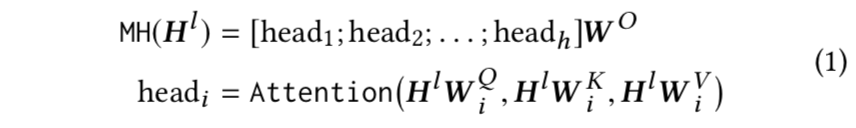
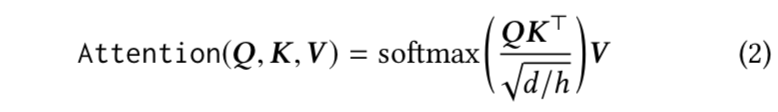
Stacking Transformer Layer使用了类似于resnet的skip连接结构。
模型训练
因为在BERT4Rec中,输入历史序列[v1, v2, ..., vt-1],输出的是包含上下文信息的向量[h1, h2, ..., ht-1],这里每个向量ht都包含了整个序列的信息。如果要预测用户t时刻的交互物品vt,如果直接把 vt 作为输入,那么其余每个物品在Transformer Layer中会看到目标物品vt的信息,造成一定程度的信息泄漏。
因此可把对应位置的输入变成[mask]标记。打标记的方式和BERT一样,随机把输入序列的一部分遮盖住,然后让模型来预测这部分对应的商品:
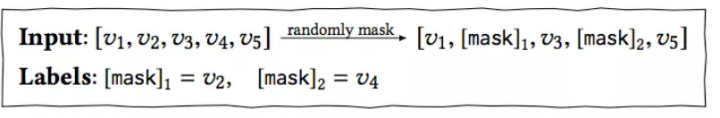
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba, 2019
模型结构
问题建模:给定一个用户u的行为序列:S(u) = {v1, v2, ..., vn },学习一个函数F用于预测用户 u 点击item vt的概率。
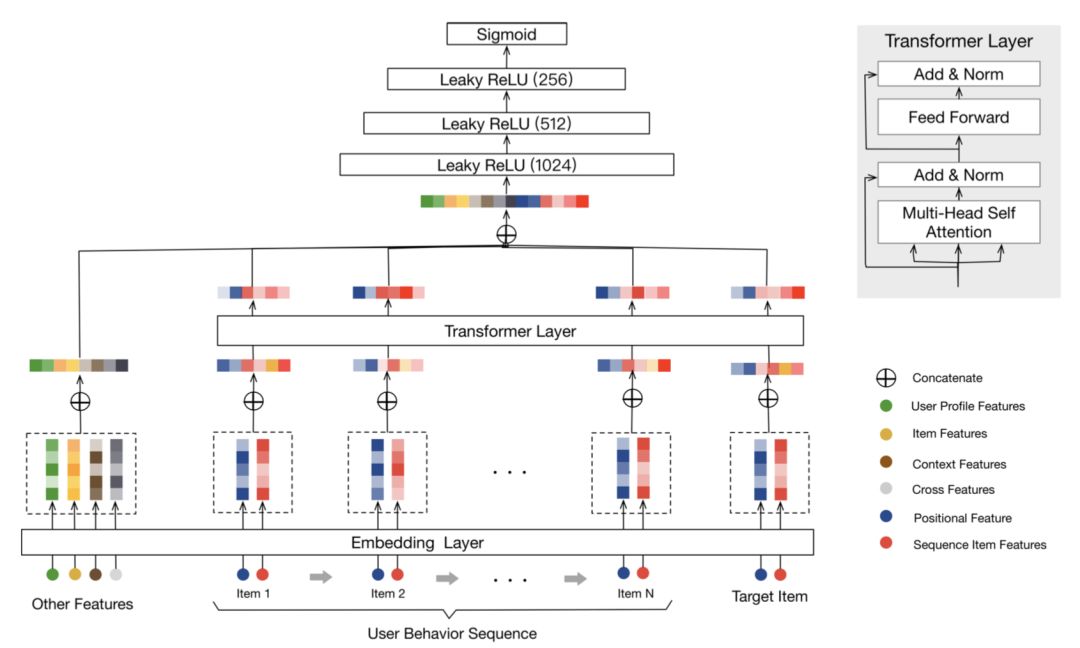
Transformer layer
对于每个item抽取了一个更深层次的representation,用于捕捉该item和历史行为序列中的其他item的关系。
DIN、DIEN、DSIN和本文BST模型的区别和联系
1. DIN模型使用注意力机制来捕获目标商品与用户先前行为序列中商品之间的相似性,但是未考虑用户行为序列背后的序列性质,并且未捕捉用户兴趣的动态变化性。
2. DIEN主要解决DIN无法捕捉用户兴趣的动态变化性的缺点,提出了兴趣抽取层Interest Extractor Layer、兴趣进化层Interest Evolution Layer。
3. DSIN针对DIN和DIEN没考虑用户历史行为中的会话信息,因为在每个会话中的行为是相近的,而在不同会话之间差别是很大的。DSIN主要是在session层面上来利用用户的历史行为序列信息。
4. BST模型通过Transformer模型来捕捉用户历史序列中各个item的关联特征,并且通过加入待推荐的商品item,也可抽取出行为序列中商品与待推荐商品之间的相关性。
延伸阅读
除了上面介绍了的这几篇Transformer应用在推荐的论文,其实今年还有更多的相关的工作列在了下面的参考文献列表中。更多最前沿的推荐广告方面的论文分享请移步如下的GitHub项目进行学习交流、star以及fork,后续仓库会持续更新最新论文。
https://github.com/imsheridan/DeepRec
1. [AutoInt][CIKM 19] AutoInt_Automatic Feature Interaction Learning via Self-Attentive Neural Networks
2. [PRM][RecSys 19][Alibaba] Personalized Re-ranking for Recommendation
3. [SDM][CIKM 19][Alibaba] Sequential Deep Matching Model for Online Large-scale Recommender System
本文转载自公众号:深度传送门,作者:Alex-zhai
推荐阅读
Google工业风最新论文, Youtube提出双塔结构流式模型进行大规模推荐
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。






