Fast-OCNet: 更快更好的OCNet.
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:RainBowSecret
来源:https://zhuanlan.zhihu.com/p/43902175
论文链接:https://arxiv.org/pdf/1809.00916.pdf
代码链接:
https://github.com/PkuRainBow/OCNet.pytorch
场景分割问题在最近几年吸引了很多研究人员的兴趣与关注,其中最出名的工作比如DeepLab系列跟PSPNet,而PSPNet还有DeepLabv3的一个很重要的实验结论就是image-level的context对于分割的结果性能提升非常重要,这方面的工作比较突出的是之前Liu Wei的ParseNet。
PSPNet,DeepLabv3中采用的context的定义很简单而且有效,在不同的分割任务上都取得了很好的效果。具体的话,就是采用Global Average Pooling 来对feature map处理得到的特征作为context来使用的。
但是这种context也存在一些问题。比如说这种context没有考虑不同的pixel的category信息。对于这种context的理解大家也没有一个公认的解释,在PSPNet的工作中,作者根据ADE20K数据集上存在的一个问题提出了自己的解释“global average pooling的context其实是编码了图片所在的scene的category信息,比如说ADE20K上的图片其实是属于300多个不同的场景类别包括飞机场,洗手间,卧室等等。而如果利用这些scene的category信息可以帮助更好的做分割任务,因为在卧室洗手间不会出现飞机,从而在一定程度上可以reduce一些干扰信息。”。之前在ParseNet论文中作者提到的一个好处是使用global average pooling的context是所有位置共享的,所以可以看做是用smoothness item。
这些不同的解释都有一定的道理,但是我们认为这种解释仍然不够好,所以我们最近做了一篇工作来重新认识一下context, 我们的motivation也比较明确,我们是从scene parsing的问题的定义出发,“the label of each pixel P is defined as the category of the object it belongs to”,所以我们就想是否把像素P所在的物体对应的context拿过来会更好呢?
但是像素P属于什么物体,属于哪一个物体是事先无法获取的,所以怎么去预测像素P所属于的物体呢,我们就想到了尝试采用attention的策略,具体的话可以参考论文中的细节。
后面我会持续分享自己在这方面的思考。
不过说实话自从PSPNet以来,场景分割方面的论文都做的不是很exciting,要么做的比较复杂,要么就是用了更好的backbone network, 要么就是使用更多的额外的数据。我们希望我们这篇工作能提供一个简单并且有效的baseline。我们希望我们的工作也能像PSPNet一样促进场景分割算法更好的发展。
欢迎大家指正讨论。
等有空了我再分享更多细节,以及我们下一步的想法。
09/06/2018
RainbowSecret
就在最近我们加了一组有意思的实验,就是我们在Cityscapes使用训练集合的ground truth来生成真实的Object Context,基于这种设置我们也可以在验证集合上使用ground truth来生成Object Context,惊喜的是我们发现这种方法相对于传统的Global Average Pooling的性能我们可以在Validation Set提高接近10个点。使用Global Average Pooling的结果是mIoU=77.5,使用ground truth来生成Object Context可以做到mIoU=88.5。我们会在后续的更新的论文版本中分享这些实验分析。
所以如何去生成更好的Object Context可能是一个非常值得探索的研究方向!
我们已经完全开源我们的实现,方便大家在我们的工作基础上继续进行工作, 希望更多的同行们可以一起去探索更好的场景分割算法!
09/15/2018
RainbowSecret
拖延了很久,这次我们再分享一下自己的一些最新的思考,首先欢迎大家阅读我们更新后的OCNet (https://arxiv.org/pdf/1809.00916.pdf),写的更干净一些,结果也调的更高一些。
在更新的论文中,主要是我老板帮我梳理了一下Object Context,Object Context Pooling的定义,我们整体论文对这些重要的term定义更加的consistent,比如说我们定义context为一组像素的集合,object context就是那些跟p属于同一类的像素的集合。同时我们也画了不少精力把OCNet的图都重新画了一遍,保证看起来更舒服。
另外最近我们发现有一些有趣的工作,比如CCNet[3]还有同时期的DANet[2],我们认为他们背后work的原因都跟Object Context存在着联系。
这里面其实有一个大家都比较感兴趣的问题,就是如何降低OCNet的计算复杂度还有内存消耗,CCNet就是一个很好的实践,但是CCNet相对而言解释性会差一些,看了CCNet很容易想到为什么不先横向aggregate然后再纵向aggregate其实也可以cover住所有的位置的context,我们认为CCNet是一个不错的工作,但是在对CCNet为什么work的解释方面略微缺乏,尤其是这种十字架的aggregate怎么去解释是不太直观的。
其实对于原始的OCNet是否可以直接采用类似于CGNL[4]中的结合律来直接达到同样的降低复杂度的目的呢(理论上的计算量跟CCNet差不多)?这个问题我们最近也非常感兴趣,我们也在进行一些相关的实验分析,同时我们也有一些其他的策略也可以用于降低Self-Attention的计算复杂度还有内存消耗。后面我们也会在第一时间在我们的github (https://github.com/PkuRainBow/OCNet.pytorch)上跟大家分享我们在这方面的进展。
除了内存的问题,我们更感兴趣的问题是如何更好的逼近true object context,这个问题更难也更具有价值,希望我们能在这个方面找到更好的方法,也欢迎有兴趣的小伙伴找我讨论分享一些想法。
11/30/2018
RainbowSecret
--闲谈--
[3,4,5,6,7] 都提出了用来降低Self-Attention复杂的方法,联系起来之前看过的论文,我们可以说[5,6,7]其实本质上都是完全一样的,都是应用了结合律来降低复杂度,只不过给出了不同的解释,因为使用结合律的时候,我们可以对不同的维度进行归一化(Softmax归一化),这种归一化的物理意义本身就对应于学习了出了一组近似表示,然后再根据这组近似表示去更新context。我们会在后面进行一些实验分析,然后对这几篇论文给出一个比较详细的分析对比总结。
另外说句无关的,[7]看起来是投的CVPR,但是idea跟[5](已经发表了NIPS)是非常像的 (在NIPS开会前投稿是OK,不过[7]里面的公式读起来比较confuse,233333333)
最新的一篇论文[8]的实验结果真的是非常的强!!!不过仔细读了之后感觉本质是在[5]的基础上用了一把Graph Convolution,个人感觉虽然[8]的结果很强,但是缺乏ablation study,比如论文里面的Inter-action space是否有必要呢?我觉得Graph Convolution这步看起来很生硬,没有理解其物理意义。如果能有一个对比实验来验证其Graph Convolution 确实带来了提高(我是对这个持怀疑态度的, 在我的实验中这个所谓的Graph Conv会很大的伤害分割的性能!),并且能解释为什么能带来提高,这篇论文会更有分量。
12/04/2018
RainbowSecret
又过去了快2个月了,已经2019年了,我们会在近期分享在分割方面最新的工作Fast-OCNet,速度比OCNet,CCNet都更快,内存消耗比OCNet, CCNet也都更小。
后续等我们把论文放出来之后再具体介绍我们的实现细节。
提前泄露一下我们的openseg.pytorch的链接:
https://github.com/openseg-group/openseg.pytorch
分享一下目前的性能对比,不同的GPU,cuda版本测试可能效果不一样,仅供参考,具体为什么我们测试的RCCA的内存消耗比论文claim的高很多,我们发现是作者实现的时候里面用了2个3X3的卷积会带来额外的内存消耗,同时RCCA目前的实现版本速度确实非常慢,比Base-OC还要慢。
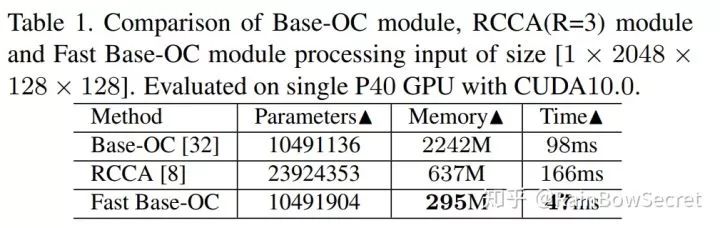
01/23/2019
RainbowSecret
Fast-BaseOCNet在Cityscapes test set 上的结果是81.7, Fast-ASPOCNet 的结果是82.1.
Fast-ASPOCNet 在ADE20K上的val集合的结果是45.69
Fast-BaseOCNet 在LIP的val集合的结果是55.60. Fast-ASPOCNet 在LIP的val集合的结果是55.50.
下面是我们刚刚提交的只用train-val-fine数据训练的FastOCNet在Cityscapes test set上的结果:
https://www.cityscapes-dataset.com/anonymous-results/?id=a56405a7b05cf0d4a36b9be26f08a0e453e7b06c3f9e80e65a631a9516892caf
欢迎大家持续关注我们的工作,我们会在近期分享我们的代码还有checkpoints.
01/27/2019
RainbowSecret
[1] Object Context Network for Scene Parsing
[2] [1809.02983] Dual Attention Network for Scene Segmentation
[3] Criss-Cross Attention for Semantic Segmentation
[4] [1810.13125] Compact Generalized Non-local Network
[5] A^2-Nets: Double Attention Networks
[6] Efficient Coarse-to-Fine Non-Local Module for the Detection of Small Objects
[7]Self-Attention with Linear Complexities
[8] [1811.12814] Graph-Based Global Reasoning Networks
*延伸阅读
双重注意力网络:中科院自动化所提出新的自然场景图像分割框架(附源码)
ECCV18 | UC伯克利提出基于自适应相似场的语义分割(附代码)
语义分割 | context relation
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~




