重新体验NoSQL | 飞雪连天射白鹿 大数狂舞倚灵动(Lindorm)
双11已圆满落幕,但技术的探索,仍未止步。
“阿里巴巴数据库技术” 特此推出《赢战2018双11——阿里数据库 & 存储技术揭秘》系列干货文章,为你讲述2135亿这个超级数字背后的故事,敬请关注!
作者:阿里巴巴存储技术事业部高级开发工程师 天穆

导语
HBase在阿里发展了近8个年头,已经成为阿里技术体系中的核心存储产品之一,全面服务于阿里巴巴生态的等各个领域。随着业务要求不断提高,HBase在宕机恢复时间、抖动与毛刺、强一致Replication、开发易用性等方面的问题逐渐凸显。
为了从根本上解决这些痛点问题,提供更好的用户体验,阿里巴巴打造了新一代大规模NoSQL系统Lindorm(中文:灵动),聚焦于解决大数据(无限扩展、高吞吐)、在线服务(低延时、高可用)、多功能的诉求,致力于成为'大多数的选择',并在2018年双11圆满完成首秀。
本文将透过双十一的具体场景,解读Lindorm在数据访问、可用性、性能、生态等方面的核心设计与关键能力。
关于Lindorm
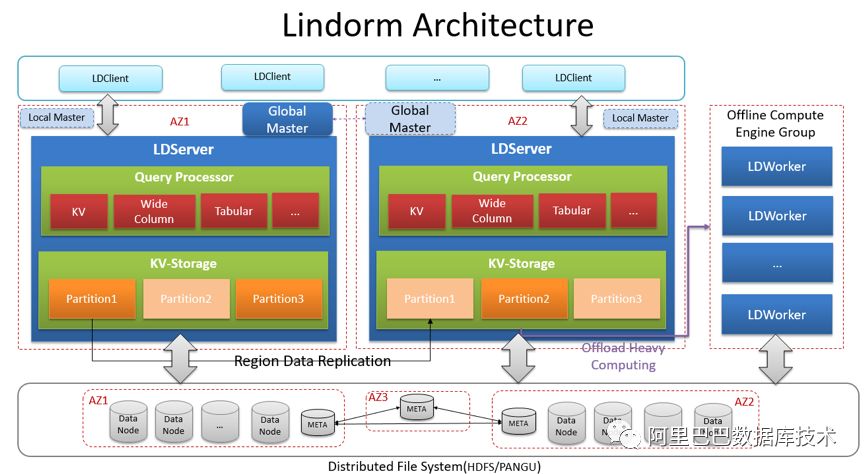
Lindorm(中文:灵动)是新一代的分布式NoSQL数据库,集大规模、高吞吐、快速灵活、实时混合能力于一身,面向海量数据场景提供世界领先的高性能、可跨域、多一致、多模型的混合存储处理能力。Lindorm脱胎于Ali-HBase(基于社区HBase的深度优化版),经过架构和引擎的重大改造和升级,在功能、性能、可用性方面实现重大飞跃。
Lindorm在2018年双11承载了众多核心业务,覆盖电商、蚂蚁、菜鸟、CCO、阿里妈妈、高德、优酷等各大BU,并支撑了蚂蚁风控、集团监控(with TSDB时序时空数据库)、RiskModel等多个千万级吞吐压力的核心链路场景,双11当天处理请求2.4万亿行。文章将从功能、可用性、性能成本、服务生态等维度介绍Lindorm的核心能力与业务表现,最后分享部分我们后续的一些工作。
1、能力进化
1.1. 数据访问
Lindorm是一个支持多模型的系统,目前提供KeyValue、WideColumn、Tabular三种模型,并通过作为TSDB的存储引擎可扩展支持时序、时空模型。KeyValue、WideColumn模型可通过HBase兼容客户端及原生API提供服务,Tabular(关系表)模型通过SQL-like API和JDBC提供服务。Lindorm表天然具备主键索引,可以很好的满足主键匹配模式的查询需求;同时也提供全局强一致二级索引,满足通用的索引查询需求。
除了原生客户端,Lindorm也提供了兼容HBase的客户端,HBase业务可以完全无缝迁移到Lindorm。
目前几种模型和访问方式都有在生产环境大规模使用:
蚂蚁风控和RiskModel都使用WideColumn模型和原生API
时序数据库(tsdb)使用HBase的兼容客户端访问Lindorm
优酷播放记录、商品库存记录使用SQL-Like API和全局二级索引
1.2. 极致可用
可用性是系统应对异常或故障的能力的度量。我们可以从三个方面来理解Lindorm的持续可用能力:
宕机恢复时间(MTTR):宕机对服务的影响时间,系统可以用较长的时间(分钟级)来处理宕机事件,但通过副本切换可以实现业务的秒级恢复。Lindorm可做到
△ 强一致模型,故障恢复 < 30 秒
△ 最终一致模型,故障恢复 < 5秒
容灾:Lindorm标配同城双机房部署,可实现跨机房强一致容灾;也支持异地多活部署(如蚂蚁风控业务)和单元化部署,以获得不同级别的容灾能力。
抖动/毛刺:从工程的角度,毛刺是无法被彻底消除的。在Lindorm中,我们通过多副本冗余请求的设计,使得每个请求能从多副本中寻找健康节点,主动规避因软硬件问题产生的高延时,使得毛刺比率数量级下降。
在生产业务中的表现:
TSDB同时使用强一致和基本一致模型,跨idc流量切换对业务无影响
TSDB从HBase迁移Lindorm后,大batch写(2k-1w行)的秒级毛刺基本消失,99.9%的batch写RT在500ms以下
蚂蚁风控从HBase迁移Lindorm后,在近千万读压力下,最大读RT从秒级减少到100ms左右
分区多副本
软硬件故障是无法彻底避免的,但系统可以通过冗余的方式获得极高的整体可用性。就像我们有两只眼睛,两双手,这是大自然赋予我们的“容灾”设计。虽然一只手也能吃饭,但要两只手才能爽利的剥小龙虾。在分布式系统中,“副本”理应相互配合,而非孤军作战。
(1)切换副本而非等待其恢复
在HBase/BigTable的设计中,实际提供数据服务的region是单点,无法抵御软硬件问题导致的毛刺或抖动,宕机场景的恢复时间较长,在工程上将单机MTTR时间降到3-5分钟已经接近理论极限。所以,要将MTTR降低到秒级,系统必须在内存中拥有多副本,宕机时直接切走,而不是等宕掉的机器完成恢复处理流程。
区别于HBase/BigTable,Lindorm采用了多Region副本的设计,请求会自动选择健康的副本。对于非强一致场景,请求可以在双/多副本中自由选择,从而可规避掉绝大多数毛刺。这种灵活切换的能力保障蚂蚁风控业务,在800W+ qps场景下,RT > 100ms的毛刺小于4个/秒。
(2)一套架构实现可调的多种一致性(专利)
Lindorm能够在一个集群中同时提供多种一致性模型,用户根据自己的需求进行一致性选择。多副本架构设计如下:
例如:
强一致:AZ1的partition1是主副本,客户端日常只读写这个副本,AZ1的parition1会将数据同步给AZ2的partition1。在主副本故障时,等待数据同步完成,将主切换到AZ2的partition1上。切换时间由数据的跨zone同步延迟/速度决定,这个延迟通常在ms级。
最终一致:partition1在多个zone上的副本对等,客户端随机访问一个副本,或者访问离自己近的副本,副本数据相互同步。多个zone上同一片数据的多个副本可同时读写,灵活切换,不必等待数据同步。
配合Lindorm的自动sharding,和分片的split/merge能力,结合底层的共享存储系统,Lindorm获得了灵活的数据分布、负载调整能力,以及极低成本的扩缩容能力。
(3)复制延迟的SLA
复制积压会导致强一致表在宕机场景下MTTR时间变长,最终一致场景下数据偶发不可读。Lindorm采用了多种技术实现同城ms级同步延迟,包括:异步的内存队列(BufferTunnel)和同步的文件队列(FileTunnel),以及一些从TCP借鉴过来的机制如滑动窗口和累积确认等。
1.3. 极致性能
下表是Lindorm在2018双11一些核心业务的数据:
业务 |
写峰值(tps) |
读峰值(qps) |
蚂蚁风控 |
1960w |
822w |
RiskModel |
2365w |
428w |
时序数据库(TSDB) |
960w |
54w |
蚂蚁风控峰值吞吐提升到去年的3倍
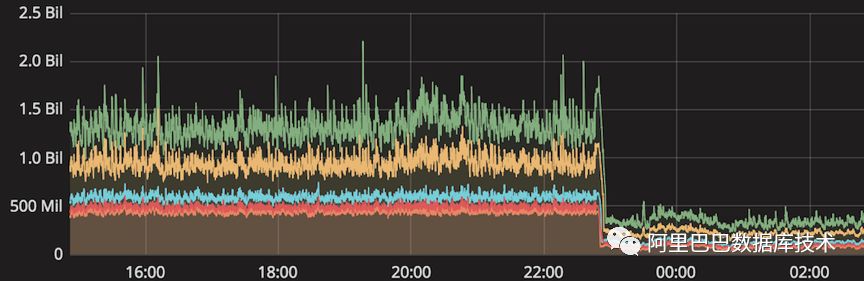
TSDB从HBase迁移至Lindorm,大batch写(2K-1w行/次)场景下平均RT从500ms左右下降到150ms左右。迁移前后的RT对比如下图所示(单位:ns,曲线含义从上至下分别是99% RT、95% RT、75% RT、中位数、平均数)
性能冲刺
性能大幅超越HBase是Lindorm立项时设立的目标,经过多轮性能冲刺,最终实现了对Ali-HBase基准性能3倍超越的阶段性目标。
场景 |
HBase |
Lindorm |
提升比 |
Get |
343k |
1043k |
204% |
Put |
121k |
441k |
264% |
下面讨论几个关键点的优化思路。
(1)高性能无锁队列LindormBlockingQueue(专利)
Lindorm服务端是一个典型的生产者消费者模型,请求队列是整套机制的核心,而JDK自带的BlockingQueue实现无法支撑百万级吞吐要求。因此我们设计了LindormBlockingQueue,采用多种免锁技术减少临界区的开销,通过多种级别的等待策略提升生产者消费者之间的协同效率。在1000w元素的生产消费压测中,相比LinkedBlockingQueue性能提升6倍。
(2)基于版本的高并发多路线程同步机制(专利)
写WAL(Write Ahead Log)包含分布式IO操作,占据了写RT的绝大部分。写WAL是一个保序的多生产者多消费者模型。Lindorm采用了一套基于版本的高并发多路线程同步机制,来解决保序场景下的生产者消费者线程协同问题,并据此重写了整套MVCC机制,大幅度提高了WAL的写能力。
(3)无锁化Metrics
为了详细监控系统运行状态,一个请求处理往往会触发数十次Metric更新,在高并发场景下,metric内部的锁冲突会迅速成为系统瓶颈。Lindorm采用了ThreadLocal的方式重构了Metric,实现无锁化的Metric更新。
(4)协程
一个请求的处理会经过数个线程池中流转,数量众多的线程导致频繁的ContextSwitch。考虑到工程代价、代码的可读性和可维护性,Lindorm选择协程来解决这个问题,在引入协程机制后,可降低2% - 4%的CPU开销。
(5)轻客户端
Lindorm采用了无状态的客户端设计,最大程度上将功能下沉到服务端实现,大幅减少客户端依赖,相比HBase可有效减少客户端CPU占用40%。同时,使用弱路由缓存、netty、异步化、黑名单等一系列技术,来提客户端的整体高吞吐和可用性。
(6)Linux内核调优
性能优化不是单个模块或系统的事情,一定是全链路拉通进行的。调整内核参数往往会起到立竿见影的效果,包括内存回收、dirty page、huge page、tcp等。
1.4. 巨人肩膀-盘古
过去我们自己维护了一个HDFS分支,在性能、稳定性、可用性、运维等方面做了很多工作。随着业务要求的不断提高,HDFS在架构上已经愈发不能满足我们的需求。HDFS的主要问题是远程读性能不足(与本地读相比),毛刺和抖动问题,无法快速使用新的硬件技术(如RDMA,Open Channel SSD等)。
经过调研,Lindorm选择了盘古作为未来的底层共享存储系统。在盘古团队的大力支持下,RiskModel业务的部分日常流量已经运行在了盘古上,并支持了2018年双十一。
盘古通过RDMA网络可以提供媲美本地读的远程读性能,在坏慢盘、宕机等场景下几乎不产生毛刺或抖动。通过分层存储(基于混合存储机型)与分池存储(不同机型混部):充分利用整体的SSD空间,相比独立部署有效减少存储碎片。
1.5. 更多
更安全:Lindorm集群支持多租户运行,并且不同的租户拥有不同的命令空间namespace,通过分组功能进行租户间的资源隔离,通过ACL进行租户间的数据访问隔离,使得数据访问的认证、鉴权更加完善可控。
更弹性:面对预分区不合理产生特大Region后无法有效弹性扩展的痛点,Lindorm支持级联Split特性,彻底消除极致弹性的最后拦路点。
更便宜:Lindorm完全透明地支持数据的冷热自动分层特性,可以将冷、温、热数据自动按产生时间分层,并异构化存储,如冷数据存储在HDD介质和并使用高压缩比算法。
更细致:Lindorm新增Accumulator特性,一种面向频繁计数更新场景的数值类型,区别于increment操作的基于旧值读取更新的方式,其每次计数增减只做变更记录的追加,数值的更新在后台的Flush/Compaction中进行,从而大幅提升计数操作的吞吐。

2、生态
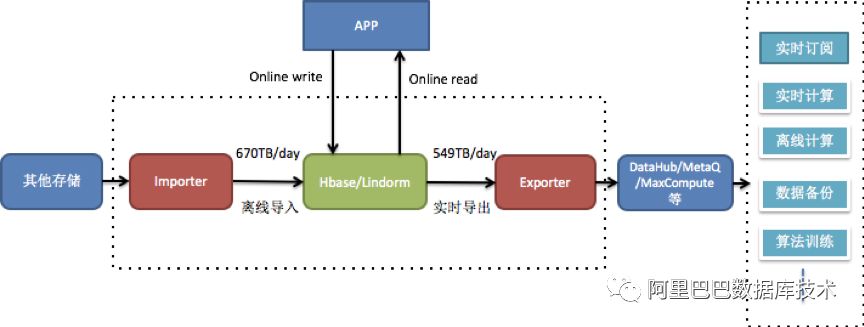
Lindorm已经对接了阿里的产品生态,接入OneService和Blink等产品,也提供了datax插件进行全量数据的导入导出,实现与其他产品的数据流转。
目前,每日导入的数据量为670TB,约3.2万亿条记录;同时,又有约549TB的数据导出到MaxCompute/DataHub/MetaQ等其他系统。因此,有必要建造一个足够粗壮的“水管”来承载如此大规模数据流。在从HBase到Lindorm的演进过程中,导入和增量数据导出也演变成了两个独立的服务Importer和Exporter,两个服务与datax和Lindorm解耦,独立部署和演进。
Importer
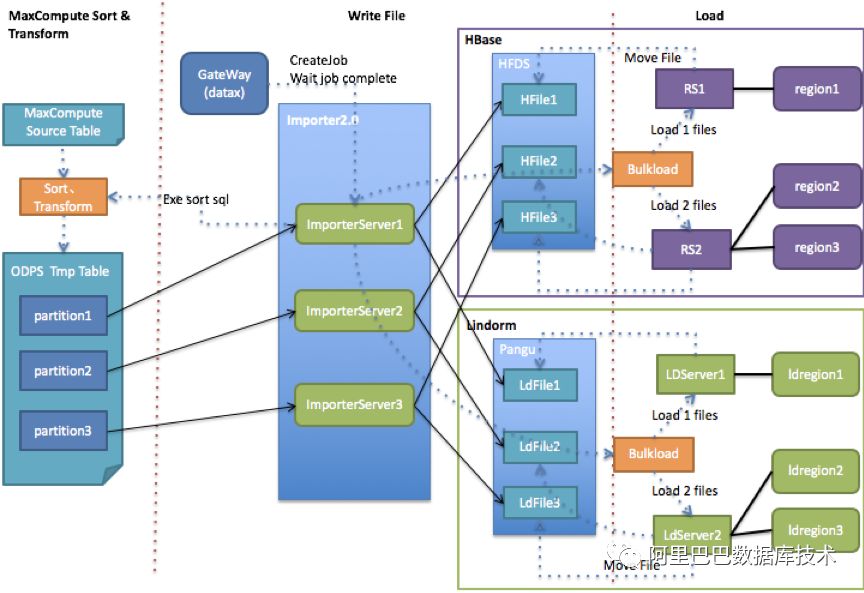
4倍速度:线上95%以上的导入流量都是从MaxCompute流入,因此,Importer专门为MaxCompute数据源场景做了别的优化。Importer直接读MaxCompute分区数据,减少数据从datax中转的开销,获得4倍以上的速度提升。
兼容Lindorm和HBase:支持同时导入Lindorm和HBase,使HBase导入任务无缝迁移到Lindorm。
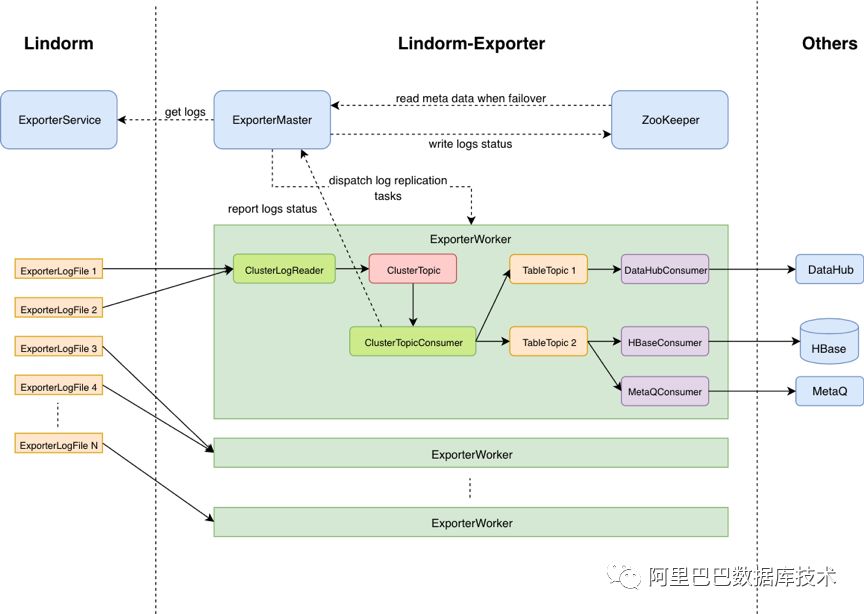
Exporter
全新架构:采用“拉”(直接读log)来替代过去的“推”(replication),减少了log的序列化、反序列化次数有效提升了log消费的效率。通过分布式提供可伸缩的导出能力和全局视角的任务调度,有效解决了数据同步积压和log单机热点问题。在TSDB迁移Lindorm过程中,支撑了千万级的增量数据同步。
自定义数据消费:支持自定义consumer,官方提供HBase/Lindorm/
TimeTunnel/MaxCompute/MetaQ的consumer,用户也可以开发自己的consumer。菜鸟智能仓储项目使用了Lindorm到MetaQ的增量同步功能。
3、后续工作
介绍几个进行中项目
Hash Engine:面向只有随机查询的场景,数据的排序组织显得有点多余。今年4月,我们重新设计了一种新的在内存、持久化上纯哈希组织的新引擎,可以大幅减少索引数据和查询过程中的CPU开销,从而大幅优化该场景的性能吞吐。该特性即将上线,欢迎关注。
Compaction:compaction是LSM存储引擎中的核心功能,在运行期间会消耗较多CPU和IO,从而对用户的读写请求产生抖动影响。目前,我们正在尝试与FPGA结合,加速compaction的执行,降低其资源开销。
Range Filter:SuRF是2018年SIGMOD最佳论文,其范围过滤和高效压缩效果拥有很高的生产价值预期,我们正在尝试将其应用于我们的系统,以提升部分场景的性能。
智能运维:评估集群的整体负载和存储水位,自动进行扩容和缩容;根据机房、机型等情况对资源进行全局调度,最大化资源的利用率。
4、总结与展望
通过架构和引擎的升级,Lindorm已经实现了功能、可用性、性能等方面的飞跃。未来将结合盘古、新硬件、新数据结构等实现更多内核上的突破,打造更快、更好用的NoSQL系统。
5、招贤纳士
欢迎大家加入阿里巴巴存储技术事业部在线大数据存储团队。存储技术事业部是阿里基础设施事业群的重要组成之一,为阿里巴巴生态中的各大业务群提供高扩展、高性能、易使用的通用存储服务。大数据在线存储团队,专注于大数据场景的分布式结构化存储系统,在阿里集团、蚂蚁金服、菜鸟等大规模使用。
在这里,你会遇到亿级别访问的尖峰时刻,不同类型业务错综复杂的场景需求,万台规模服务器集群的运营支撑,业务全球化等各类技术挑战。
期待优秀的你加入我们。简历投递方式:yanghan.y@alibaba-inc.com

推荐阅读





