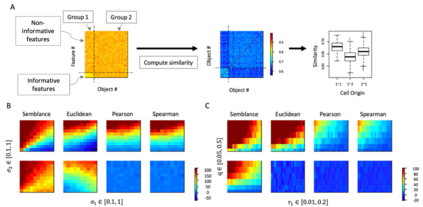
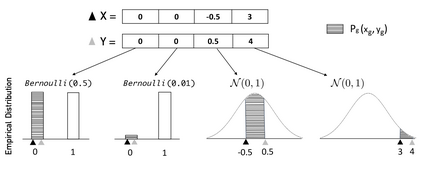
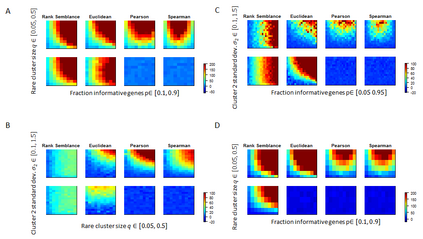
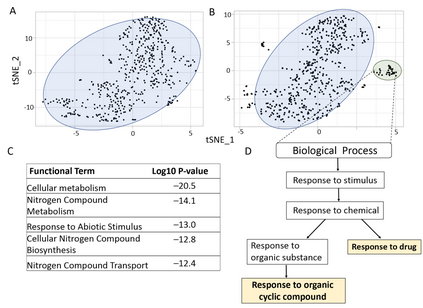
In data science, determining proximity between observations is critical to many downstream analyses such as clustering, information retrieval and classification. However, when the underlying structure of the data probability space is unclear, the function used to compute similarity between data points is often arbitrarily chosen. Here, we present a novel concept of proximity, Semblance, that uses the empirical distribution across all observations to inform the similarity between each pair. The advantage of Semblance lies in its distribution free formulation and its ability to detect niche features by placing greater emphasis on similarity between observation pairs that fall at the outskirts of the data distribution, as opposed to those that fall towards the center. We prove that Semblance is a valid Mercer kernel, thus allowing its principled use in kernel based learning machines. Semblance can be applied to any data modality, and we demonstrate its consistently improved performance against conventional methods through simulations and three real case studies from very different applications, viz. cell type classification using single cell RNA sequencing, selecting predictors of positive return on real estate investments, and image compression.
翻译:在数据科学方面,确定观测之间的接近性对于诸如集群、信息检索和分类等许多下游分析至关重要。然而,当数据概率空间的基本结构不明确时,用来计算数据点之间相似性的功能往往被任意选择。在这里,我们提出了一个关于接近性(Semblance)的新概念,即“Semblance”,它利用所有观测的实验性分布来说明每一对观测的相似性。“Semblance”的优势在于它的分布自由配制,以及它通过更多地强调数据分布边缘的观测对对的相似性,而不是流向中心的观测对等,从而能够探测其独特性特征。我们证明“Semblance”是一种有效的Mercer内核,因此允许其在以内核为基础的学习机器中有原则地使用。“Semblance”可以应用于任何数据模式,我们通过模拟和从非常不同的应用中的三个实际案例研究,即使用单细胞RNA测序、选择房地产投资正回报预测器和图像压缩来显示其业绩的一贯提高。