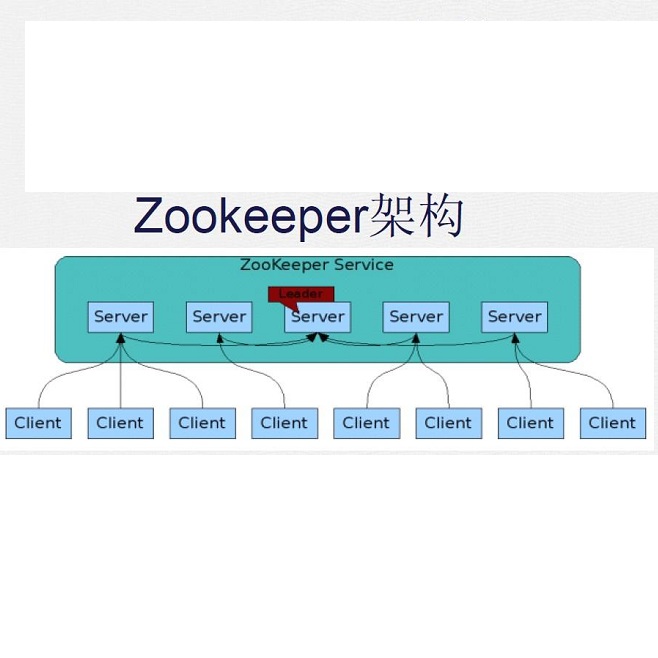
Coordination services are a fundamental building block of modern cloud systems, providing critical functionalities like configuration management and distributed locking. The major challenge is to achieve low latency and high throughput while providing strong consistency and fault-tolerance. Traditional server-based solutions require multiple round-trip times (RTTs) to process a query. This paper presents NetChain, a new approach that provides scale-free sub-RTT coordination in datacenters. NetChain exploits recent advances in programmable switches to store data and process queries entirely in the network data plane. This eliminates the query processing at coordination servers and cuts the end-to-end latency to as little as half of an RTT---clients only experience processing delay from their own software stack plus network delay, which in a datacenter setting is typically much smaller. We design new protocols and algorithms based on chain replication to guarantee strong consistency and to efficiently handle switch failures. We implement a prototype with four Barefoot Tofino switches and four commodity servers. Evaluation results show that compared to traditional server-based solutions like ZooKeeper, our prototype provides orders of magnitude higher throughput and lower latency, and handles failures gracefully.
翻译:以服务器为基础的传统解决方案需要多个圆程时间来处理查询。本文展示了NetChain, 这是一种在数据中心提供无比例的子RTT协调的新方法。NetChain利用可编程开关的最新进展将数据和处理查询完全储存在网络数据平面上。这消除了协调服务器的查询处理,并将终端到终端的嵌入时间减少到只有一半的客户只能经历从自己的软件堆叠加网络延迟的处理过程,而在数据中心设置中,这种延误通常要小得多。我们根据链式复制设计新的协议和算法,以保证强有力的一致性并高效处理开关故障。我们使用一个有四个赤脚托菲诺开关和四个商品服务器的原型。评价结果显示,与传统的服务器解决方案相比,如Zookefer,我们的原型通过平面和低底层处理的失灵。