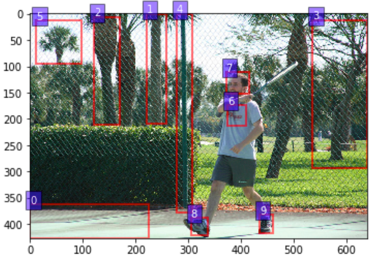
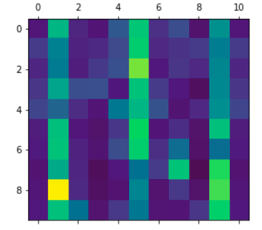
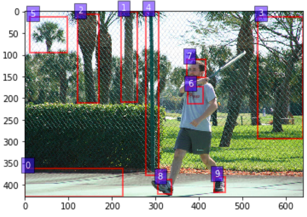
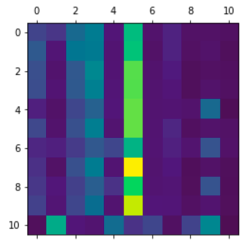
Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly, the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality Encoder Representations from Transformers) framework to learn these vision-and-language connections. In LXMERT, we build a large-scale Transformer model that consists of three encoders: an object relationship encoder, a language encoder, and a cross-modality encoder. Next, to endow our model with the capability of connecting vision and language semantics, we pre-train the model with large amounts of image-and-sentence pairs, via five diverse representative pre-training tasks: masked language modeling, masked object prediction (feature regression and label classification), cross-modality matching, and image question answering. These tasks help in learning both intra-modality and cross-modality relationships. After fine-tuning from our pre-trained parameters, our model achieves the state-of-the-art results on two visual question answering datasets (i.e., VQA and GQA). We also show the generalizability of our pre-trained cross-modality model by adapting it to a challenging visual-reasoning task, NLVR2, and improve the previous best result by 22% absolute (54% to 76%). Lastly, we demonstrate detailed ablation studies to prove that both our novel model components and pre-training strategies significantly contribute to our strong results; and also present several attention visualizations for the different encoders. Code and pre-trained models publicly available at: https://github.com/airsplay/lxmert
翻译:视觉和语言推理要求理解视觉概念、语言语义以及最重要的这两个模式之间的校正和关系。 因此,我们提出LXMERT(从变异器中学习跨模版编码器)框架来学习这些视觉和语言连接。 在LXMERT中,我们建立了一个大型变异器模型,由三个编码器组成:一个对象关系编码器、一个语言编码器和一个跨模式编码器。接下来,为了将我们的模型与视觉和语言语义连接起来,我们先用大量的图像和感知配对进行模型培训,通过五种不同的培训前任务:遮掩语言模型、遮掩的物体预测(畸形回归和标签分类)、交叉模式匹配和图像解答。这些任务有助于学习内部模式和前模式/模式的注意。在经过对我们之前的参数进行微调后,我们的模型在两种视觉和感知化的图像模型模型模型中都实现了坚固的读取结果:我们现在的视觉和现在的图像解析结果, 也显示我们现在的视觉和现在的GA的精确度。