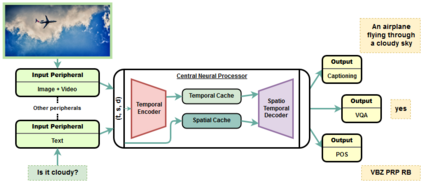
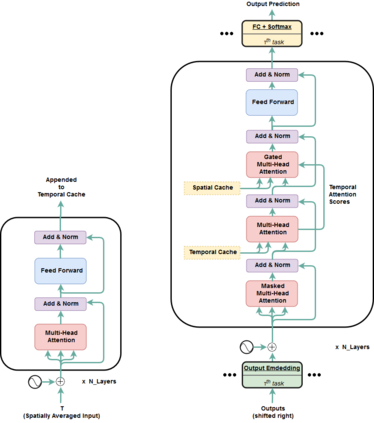
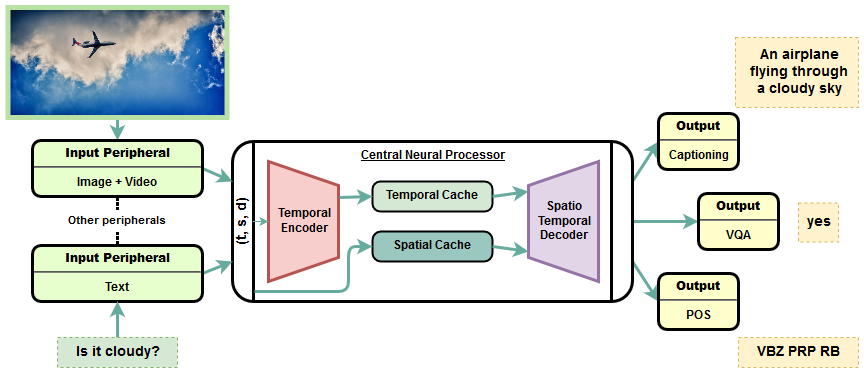
Transformer is a popularly used neural network architecture, especially for language understanding. We introduce an extended and unified architecture which can be used for tasks involving a variety of modalities like image, text, videos, etc. We propose a spatio-temporal cache mechanism that enables learning spatial dimension of the input in addition to the hidden states corresponding to the temporal input sequence. The proposed architecture further enables a single model to support tasks with multiple input modalities as well as asynchronous multi-task learning, thus we refer to it as OmniNet. For example, a single instance of OmniNet can concurrently learn to perform the tasks of part-of-speech tagging, image captioning, visual question answering and video activity recognition. We demonstrate that training these four tasks together results in about three times compressed model while retaining the performance in comparison to training them individually. We also show that using this neural network pre-trained on some modalities assists in learning an unseen task. This illustrates the generalization capacity of the self-attention mechanism on the spatio-temporal cache present in OmniNet.
翻译:变换器是一个常用的神经网络架构, 特别是语言理解。 我们引入了一个扩展和统一的架构, 可用于涉及图像、 文本、 视频等多种模式的任务。 我们提出一个spatio- 时空缓存机制, 能够学习与时间输入序列相对应的隐藏状态之外输入内容的空间层面。 拟议的架构还使一个单一模式能够支持多种输入模式和同步多任务学习的任务, 因此我们称之为 OmniNet 。 例如, OmniNet 的单一实例可以同时学习执行部分语音标记、 图像说明、 视觉问题解答和视频活动识别等任务。 我们证明, 将这四项任务结合起来的培训将产生大约三倍的压缩模型, 同时保留其性能, 以单独培训它们。 我们还表明, 使用该神经网络就某些模式进行预先培训, 有助于学习一项不可见的任务。 这说明了OmniNet 的磁场缓存机制的一般能力 。