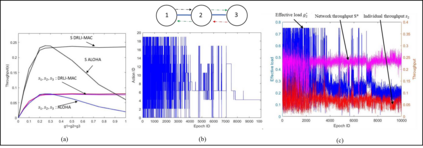
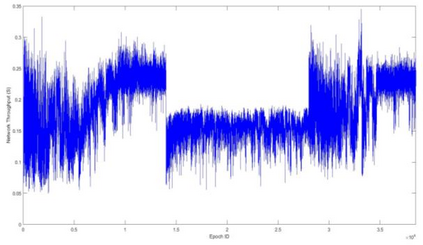
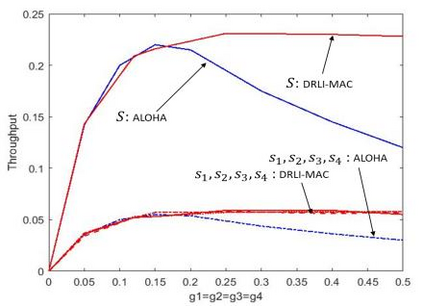
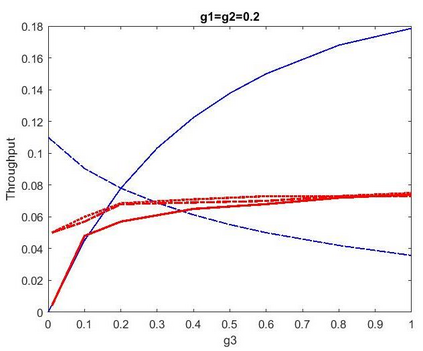
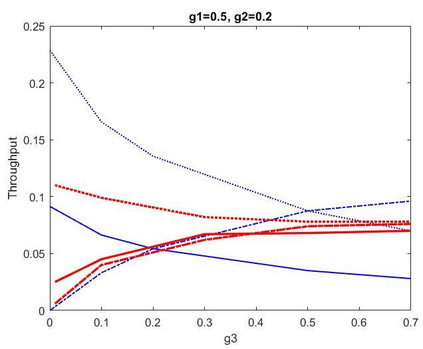
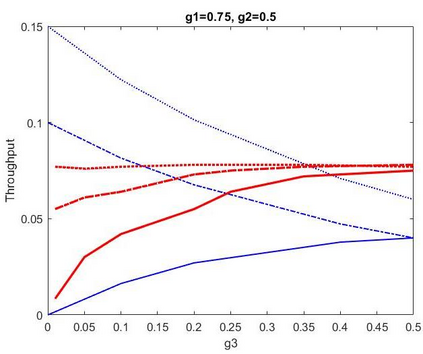
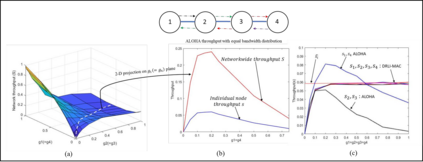
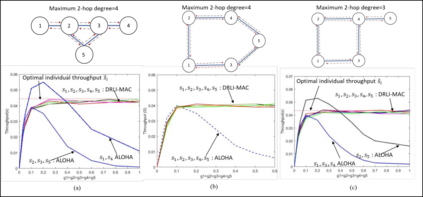
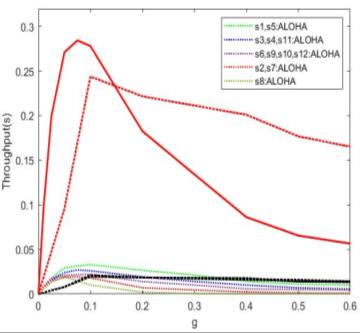
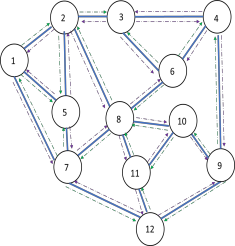
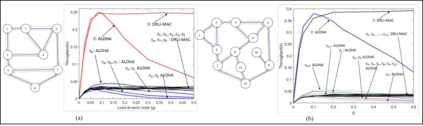
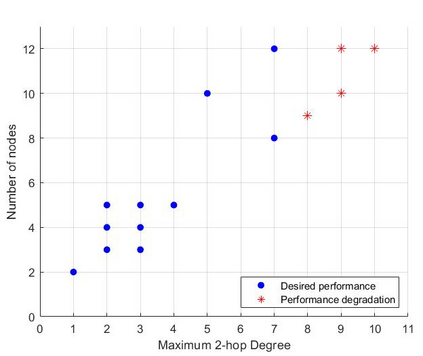
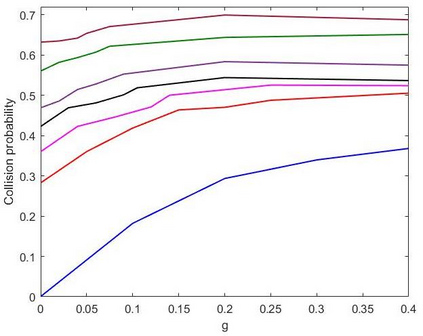
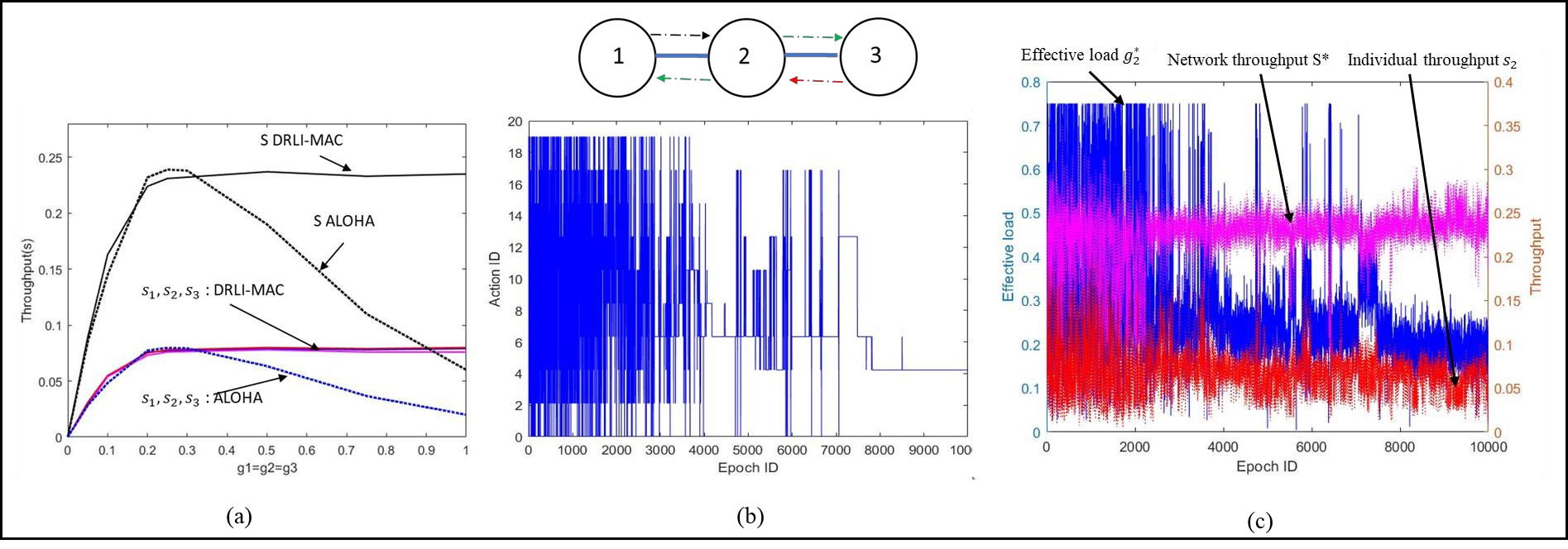
This paper proposes a distributed Reinforcement Learning (RL) based framework that can be used for synthesizing MAC layer wireless protocols in IoT networks with low-complexity wireless transceivers. The proposed framework does not rely on complex hardware capabilities such as carrier sensing and its associated algorithmic complexities that are often not supported in wireless transceivers of low-cost and low-energy IoT devices. In this framework, the access protocols are first formulated as Markov Decision Processes (MDP) and then solved using RL. A distributed and multi-Agent RL framework is used as the basis for protocol synthesis. Distributed behavior makes the nodes independently learn optimal transmission strategies without having to rely on full network level information and direct knowledge of behavior of other nodes. The nodes learn to minimize packet collisions such that optimal throughput can be attained and maintained for loading conditions that are higher than what the known benchmark protocols (such as ALOHA) for IoT devices without complex transceivers. In addition, the nodes are observed to be able to learn to act optimally in the presence of heterogeneous loading and network topological conditions. Finally, the proposed learning approach allows the wireless bandwidth to be fairly distributed among network nodes in a way that is not dependent on such heterogeneities. Via simulation experiments, the paper demonstrates the performance of the learning paradigm and its abilities to make nodes adapt their optimal transmission strategies on the fly in response to various network dynamics.
翻译:本文提出一个分布式强化学习(RL)基础框架,可用于在具有低复杂度无线收发器的IoT网络中合成 MAC 层无线协议。拟议框架并不依赖于承运人遥感等复杂硬件能力及其相关的算法复杂性,而这种能力往往在低成本和低能IoT设备的无线收发器中得不到支持。在此框架内,访问协议首先作为Markov 决策程序(MDP)制定,然后用RL解决。一个分布式和多偏好RL框架被用作协议合成的基础。分散式行为使节点独立学习最佳传输战略,而不必依赖完全的网络级信息和对其他节点行为的直接知识。节点学会尽量减少组合碰撞,以便实现最佳的吞吐量,并维持高于已知的无复杂传感器的基准协议(如ALOHA),然后使用RL。此外,人们观察到,各种节点框架能够学习最优化地在混合装载和网络模式中进行传输能力,因此无法在移动式网络上进行顺利地学习。最后,他所提议在模拟的网络上学习的升级能力,他不能够以这种方式进行。