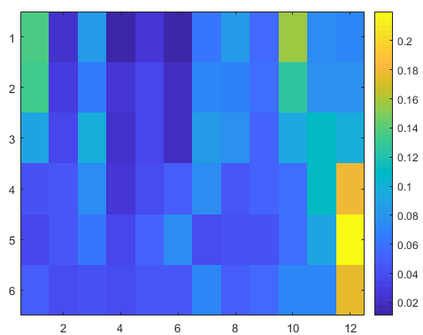
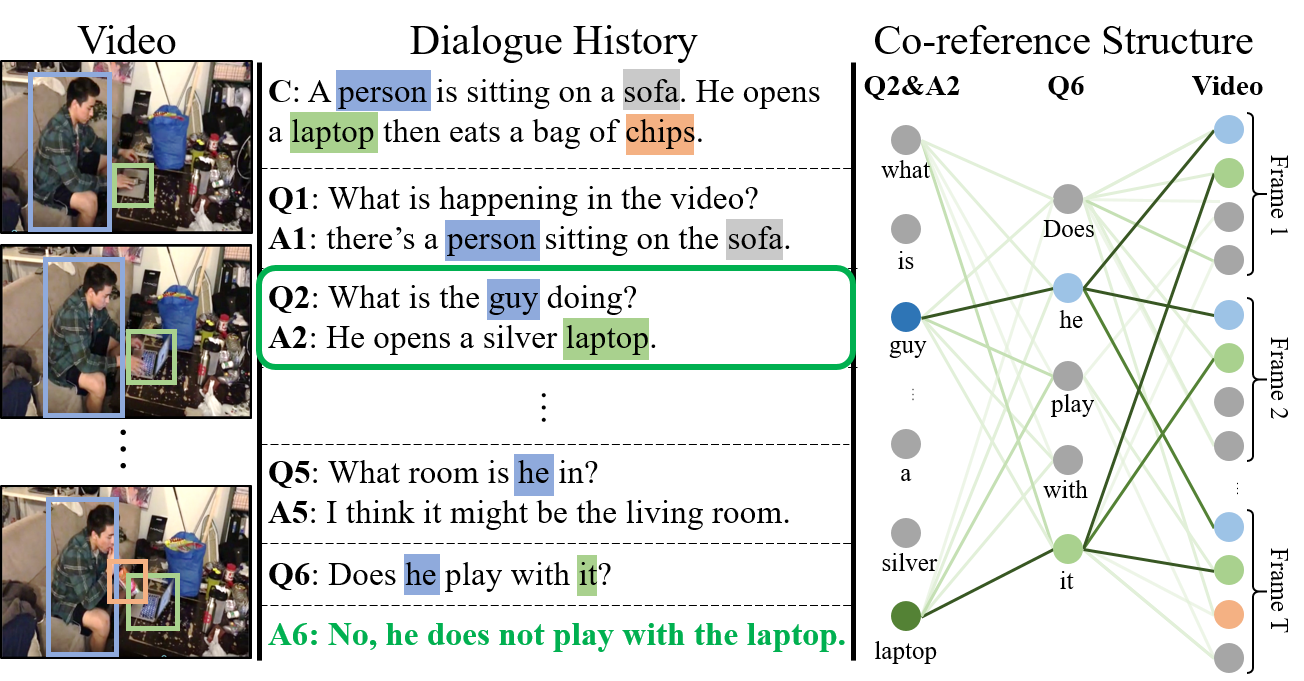
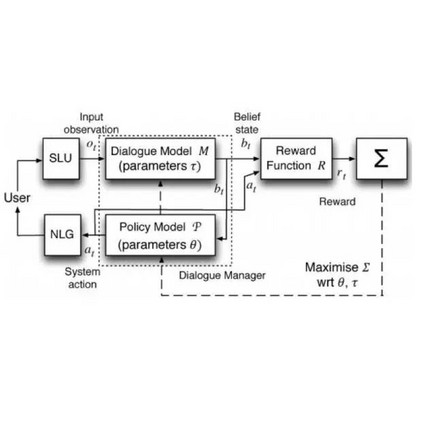
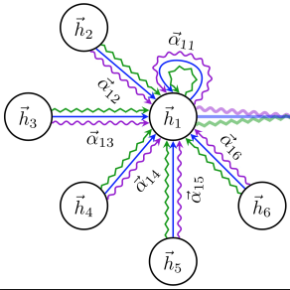
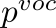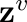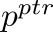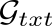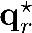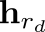A video-grounded dialogue system referred to as the Structured Co-reference Graph Attention (SCGA) is presented for decoding the answer sequence to a question regarding a given video while keeping track of the dialogue context. Although recent efforts have made great strides in improving the quality of the response, performance is still far from satisfactory. The two main challenging issues are as follows: (1) how to deduce co-reference among multiple modalities and (2) how to reason on the rich underlying semantic structure of video with complex spatial and temporal dynamics. To this end, SCGA is based on (1) Structured Co-reference Resolver that performs dereferencing via building a structured graph over multiple modalities, (2) Spatio-temporal Video Reasoner that captures local-to-global dynamics of video via gradually neighboring graph attention. SCGA makes use of pointer network to dynamically replicate parts of the question for decoding the answer sequence. The validity of the proposed SCGA is demonstrated on AVSD@DSTC7 and AVSD@DSTC8 datasets, a challenging video-grounded dialogue benchmarks, and TVQA dataset, a large-scale videoQA benchmark. Our empirical results show that SCGA outperforms other state-of-the-art dialogue systems on both benchmarks, while extensive ablation study and qualitative analysis reveal performance gain and improved interpretability.
翻译:以视频为基础的对话系统,称为结构化共同参考图表(SCGA),用于解码对特定视频问题的答案序列,同时跟踪对话背景。虽然最近的努力在提高答复质量方面取得了长足进步,但业绩仍然远远不令人满意。两个主要挑战性问题如下:(1) 如何推算多种模式之间的共同参照,和(2) 如何解释具有复杂空间和时间动态的视频的丰富基本语义结构。为此,SCGA基于:(1) 结构化共同解码器,通过建立多模式结构化图表进行参考;(2) Spatio-时间性视频解释器,通过逐步临近图示关注捕捉到视频在本地到全球的动态;SCGA利用指示器网络动态复制问题的某些部分以解析答案序列。拟议的SCGA的有效性在AVSD@DSTC7和AVSDSD@DTC8数据集上展示,具有挑战性的视频背景对话基准,TVQA数据设置,通过渐进式的图像显示大规模对话结果,同时同时对SCTAAA进行广泛的业绩分析。我们的经验性结果展示了SBA和定性分析。