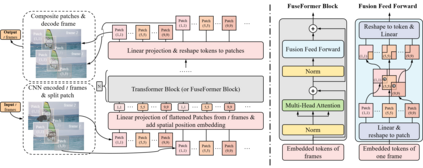
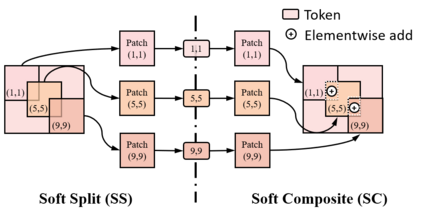
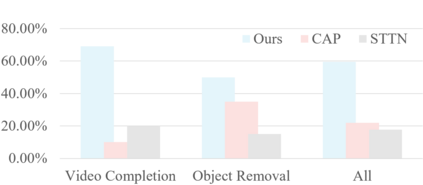
Transformer, as a strong and flexible architecture for modelling long-range relations, has been widely explored in vision tasks. However, when used in video inpainting that requires fine-grained representation, existed method still suffers from yielding blurry edges in detail due to the hard patch splitting. Here we aim to tackle this problem by proposing FuseFormer, a Transformer model designed for video inpainting via fine-grained feature fusion based on novel Soft Split and Soft Composition operations. The soft split divides feature map into many patches with given overlapping interval. On the contrary, the soft composition operates by stitching different patches into a whole feature map where pixels in overlapping regions are summed up. These two modules are first used in tokenization before Transformer layers and de-tokenization after Transformer layers, for effective mapping between tokens and features. Therefore, sub-patch level information interaction is enabled for more effective feature propagation between neighboring patches, resulting in synthesizing vivid content for hole regions in videos. Moreover, in FuseFormer, we elaborately insert the soft composition and soft split into the feed-forward network, enabling the 1D linear layers to have the capability of modelling 2D structure. And, the sub-patch level feature fusion ability is further enhanced. In both quantitative and qualitative evaluations, our proposed FuseFormer surpasses state-of-the-art methods. We also conduct detailed analysis to examine its superiority.
翻译:作为建模长距离关系的强大和灵活的变异器结构,已在愿景任务中进行了广泛探索。然而,当用于制作需要精细代表的视频涂鸦时,由于硬片分割,现有方法仍因细细细的模糊边缘而受到影响。在这里,我们的目标是提出FuseFormer(一个基于新型软片分割和软片构成操作的微小拼图组合为视频涂色设计的变异器模型)来解决这一问题。软分裂使地图在多个相间间隔的补点中具有特征特征。相反,软结构通过将不同的补丁缝合成一个整体特征图,将重叠区域的像素进行总结。这两个模块首先用于变异器层之前的象征化和变异器层之后的脱位化。因此,亚相级信息互动能够更有效地在相邻区之间进行特征传播,从而将感光度内容合成给各洞区。此外,在FuseFormer(FuseFormer)中,我们精细地将软面构成和软质化的变异性分析能力插入了1号结构。我们提出的软体变变变变变的系统结构,将软的变式结构进一步插入了F-rode-rode-toforstal laft-stalalalalalalalalalalalalalalal laction laction ladaldal