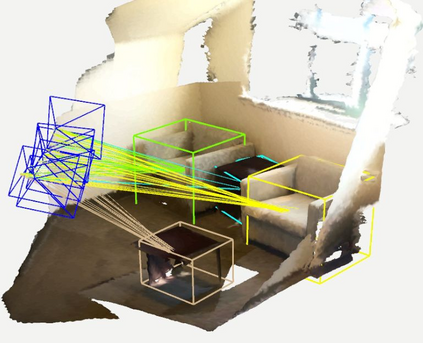
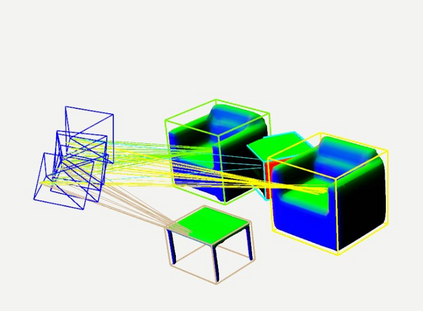
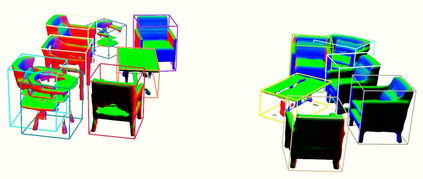
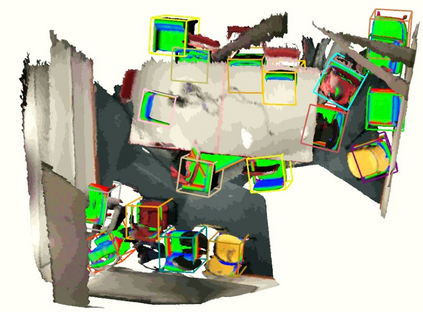
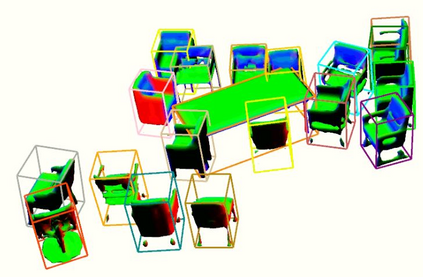
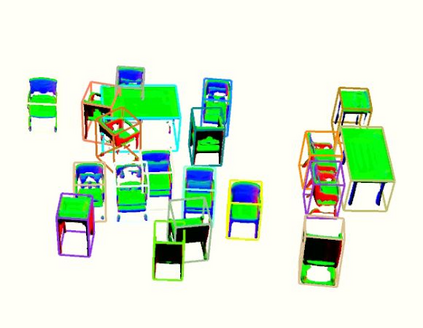
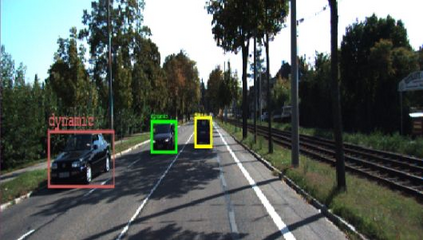
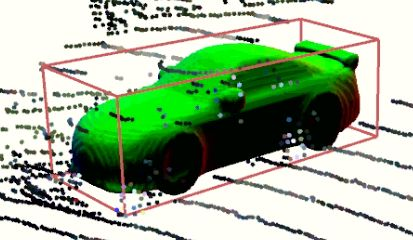
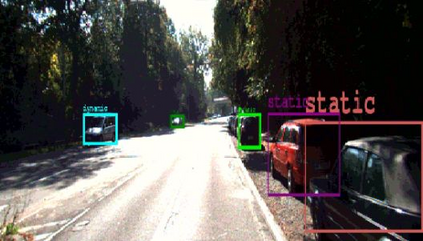
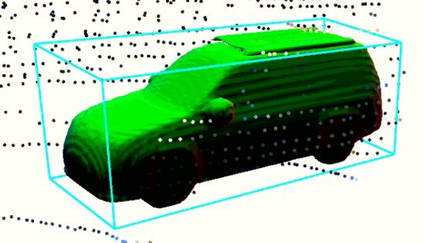
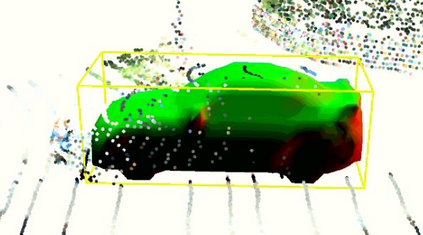
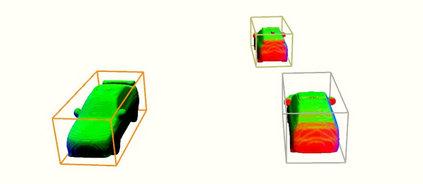
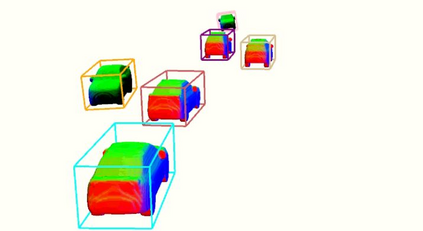
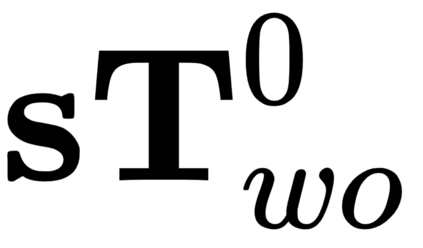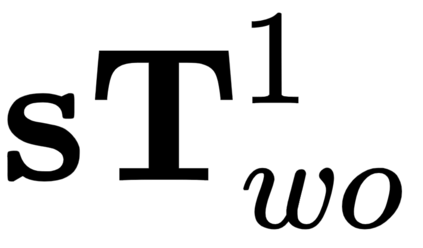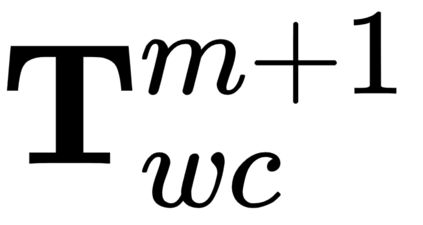Semantic aware reconstruction is more advantageous than geometric-only reconstruction for future robotic and AR/VR applications because it represents not only where things are, but also what things are. Object-centric mapping is a task to build an object-level reconstruction where objects are separate and meaningful entities that convey both geometry and semantic information. In this paper, we present MO-LTR, a solution to object-centric mapping using only monocular image sequences and camera poses. It is able to localize, track, and reconstruct multiple objects in an online fashion when an RGB camera captures a video of the surrounding. Given a new RGB frame, MO-LTR firstly applies a monocular 3D detector to localize objects of interest and extract their shape codes that represent the object shape in a learned embedding space. Detections are then merged to existing objects in the map after data association. Motion state (i.e. kinematics and the motion status) of each object is tracked by a multiple model Bayesian filter and object shape is progressively refined by fusing multiple shape code. We evaluate localization, tracking, and reconstruction on benchmarking datasets for indoor and outdoor scenes, and show superior performance over previous approaches.
翻译:语义意识重建比对未来机器人和AR/VR应用进行仅几何范围的重建更为有利,因为它不仅代表事物所在的位置,而且代表事物所在。 以物体为中心的绘图是一项任务,目的是在物体为独立和有意义的实体,传递几何和语义信息的情况下,建立一个目标级重建。 在本文中, 我们展示了 MO- LTR, 以物体为中心的绘图解决方案, 仅使用单方图像序列和相机配置。 当 RGB 相机拍摄周围的视频时, 它能够以在线方式对多个物体进行本地化、 跟踪和重建。 在新的 RGB 框架下, MO- LTR 首先应用一个单方位 3D 探测器, 将感兴趣的对象定位, 并提取其形状代码, 以在学习的嵌入空间中代表物体形状。 检测结果随后在数据关联后与地图中的现有对象合并。 每个对象的动态状态( 即运动状态和运动状态) 由多个模型贝耶斯过滤器和对象形状通过使用多个形状代码逐步改进。 我们评估了室内和图像的性能显示前镜像像化、 。