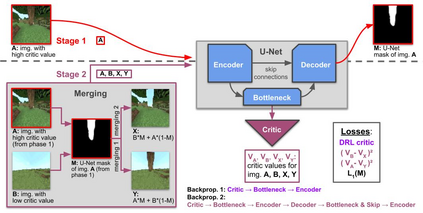
This work discusses a learning approach to mask rewarding objects in images using sparse reward signals from an imitation learning dataset. For that, we train an Hourglass network using only feedback from a critic model. The Hourglass network learns to produce a mask to decrease the critic's score of a high score image and increase the critic's score of a low score image by swapping the masked areas between these two images. We trained the model on an imitation learning dataset from the NeurIPS 2020 MineRL Competition Track, where our model learned to mask rewarding objects in a complex interactive 3D environment with a sparse reward signal. This approach was part of the 1st place winning solution in this competition. Video demonstration and code: https://rebrand.ly/critic-guided-segmentation
翻译:本文讨论使用仿造学习数据集中的微弱奖赏信号在图像中掩盖奖励对象的学习方法。 为此, 我们仅使用来自批评者的反馈来训练沙漏网络。 沙漏网络学会了制作面具, 以减少评论者高分图像的得分, 通过在这两张图像之间互换蒙面区域来增加评论者低分图像的得分。 我们训练了NeurIPS 2020 MineRL 竞赛轨道的模拟学习数据集模型, 我们的模型在复杂的互动的3D环境中以稀有的奖赏信号来掩盖奖励对象。 这种方法是本次竞赛中第1个赢家解决方案的一部分 。 视频演示和代码 : https://rebrand.ly/critic- guided- sectionation