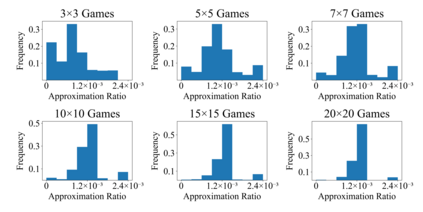
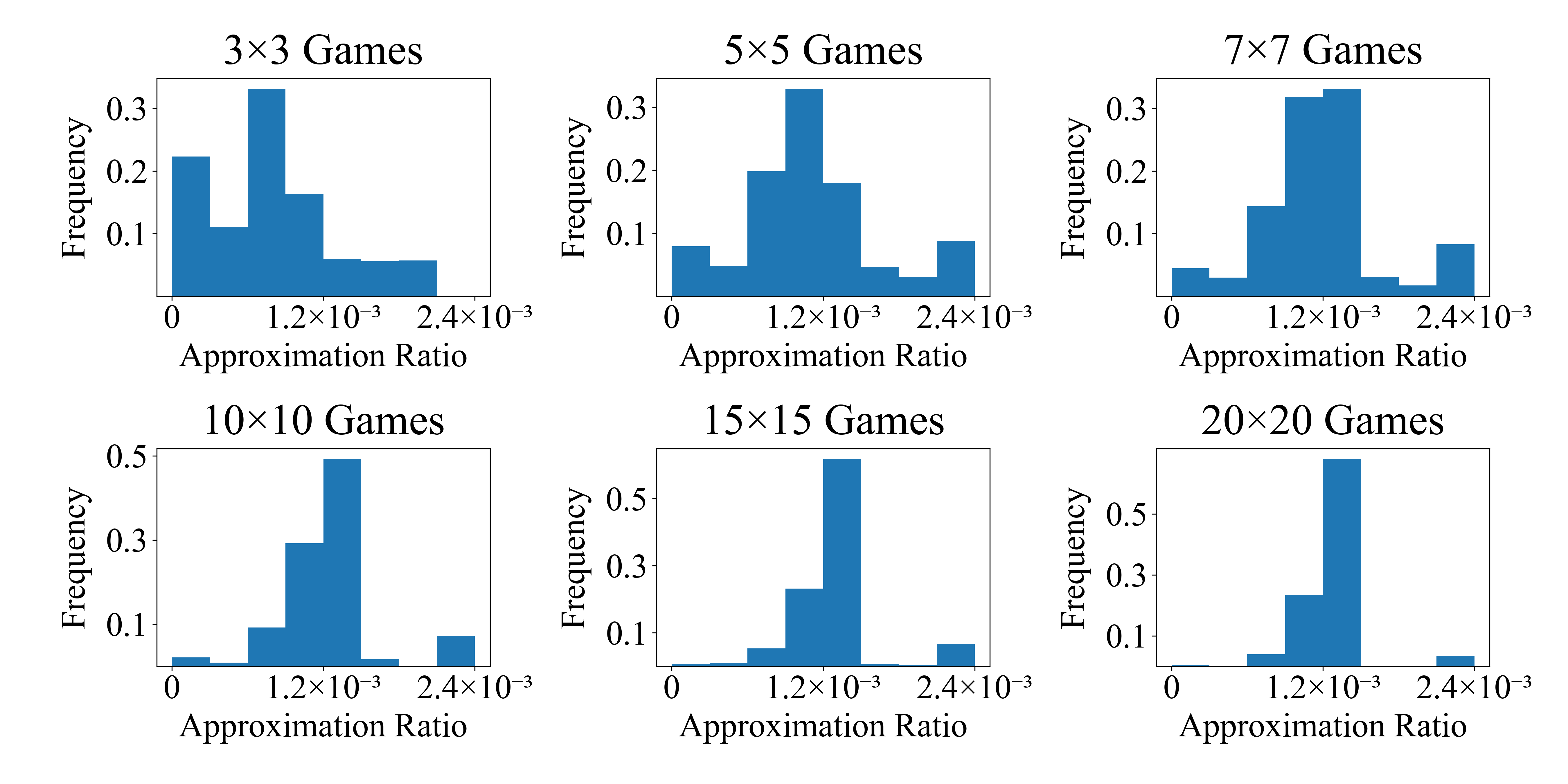
Finding the minimum approximate ratio for Nash equilibrium of bi-matrix games has derived a series of studies, started with 3/4, followed by 1/2, 0.38 and 0.36, finally the best approximate ratio of 0.3393 by Tsaknakis and Spirakis (TS algorithm for short). Efforts to improve the results remain not successful in the past 14 years. This work makes the first progress to show that the bound of 0.3393 is indeed tight for the TS algorithm. Next, we characterize all possible tight game instances for the TS algorithm. It allows us to conduct extensive experiments to study the nature of the TS algorithm and to compare it with other algorithms. We find that this lower bound is not smoothed for the TS algorithm in that any perturbation on the initial point may deviate away from this tight bound approximate solution. Other approximate algorithms such as Fictitious Play and Regret Matching also find better approximate solutions. However, the new distributed algorithm for approximate Nash equilibrium by Czumaj et al. performs consistently at the same bound of 0.3393. This proves our lower bound instances generated against the TS algorithm can serve as a benchmark in design and analysis of approximate Nash equilibrium algorithms.
翻译:找到双方基游戏纳什平衡的最低近似比值得出了一系列研究,先是3/4,然后是1/2,0.38和0.36,最后是Tsaknakis和Spirakis(短程TS算法)的最佳近似比值0.3393。过去14年来,改善结果的努力一直没有成功。这项工作首次取得进展,表明TS算法的0.3393的界限确实十分紧凑。接着,我们确定了TS算法的所有可能的紧凑游戏实例。这使我们能够进行广泛的实验,研究TS算法的性质,并与其他算法进行比较。我们发现,对于TS算法来说,这一较低的约束比值并不顺利,因为任何在初始点的干扰都可能偏离这一紧紧紧的近似解决办法。其他大致的算法,如Fictititis Play和Regret匹配法,也能找到更好的近似解决办法。然而,Czummaj等人为接近纳什平衡而采用的新的分布式算法,在0.3393的同一约束下始终执行。这证明了我们为TS算法所生成的较低约束的例子。