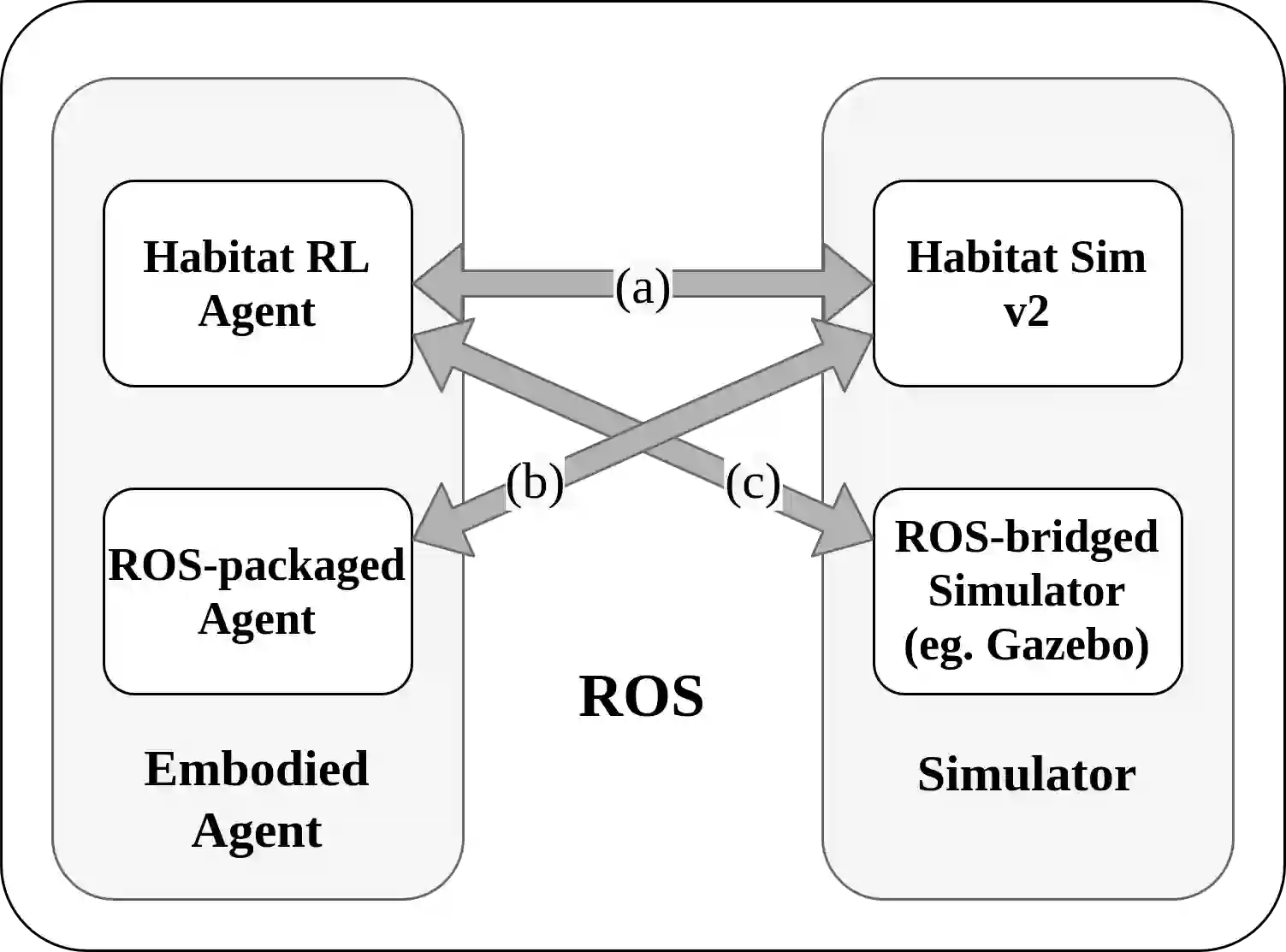
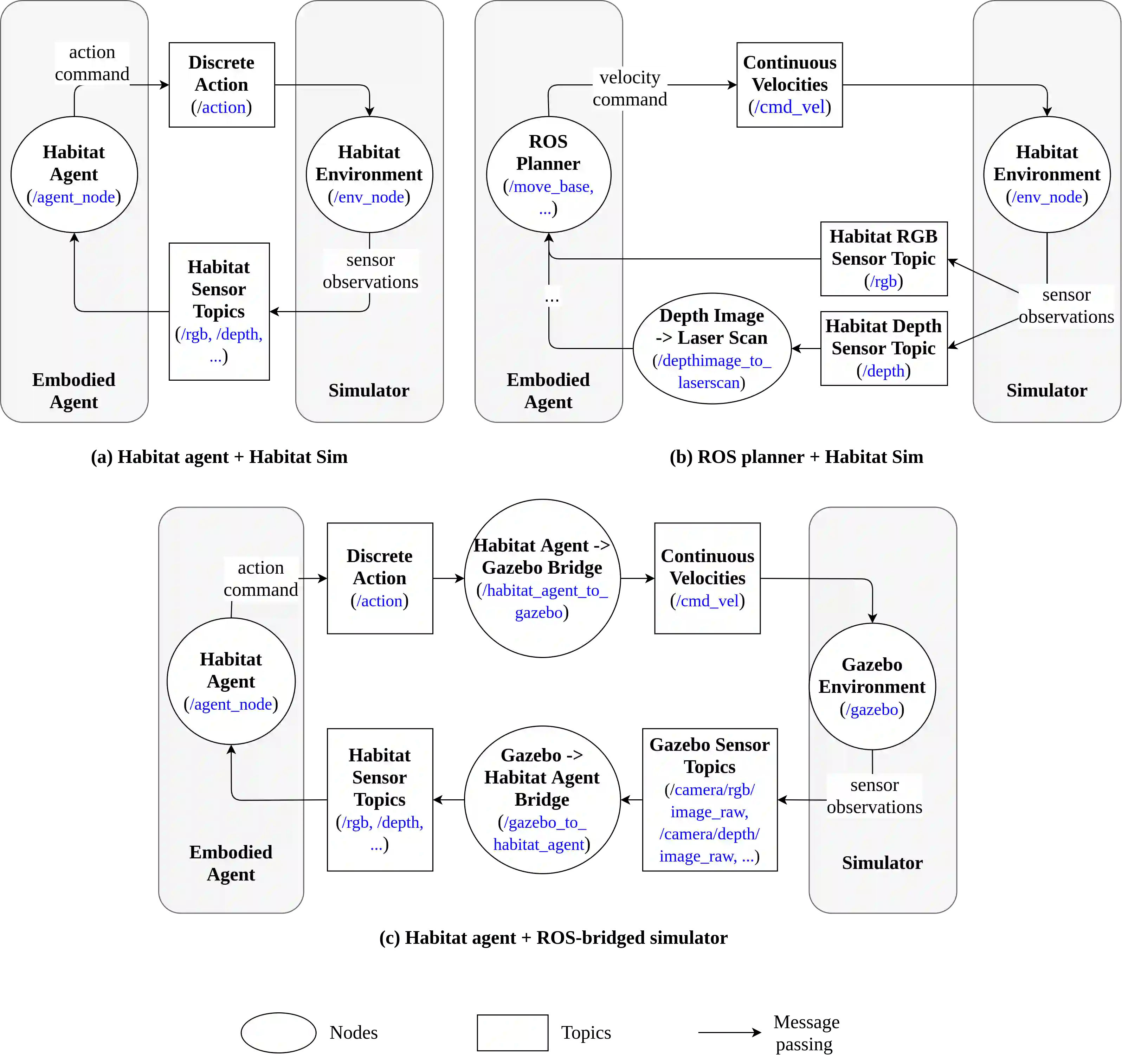
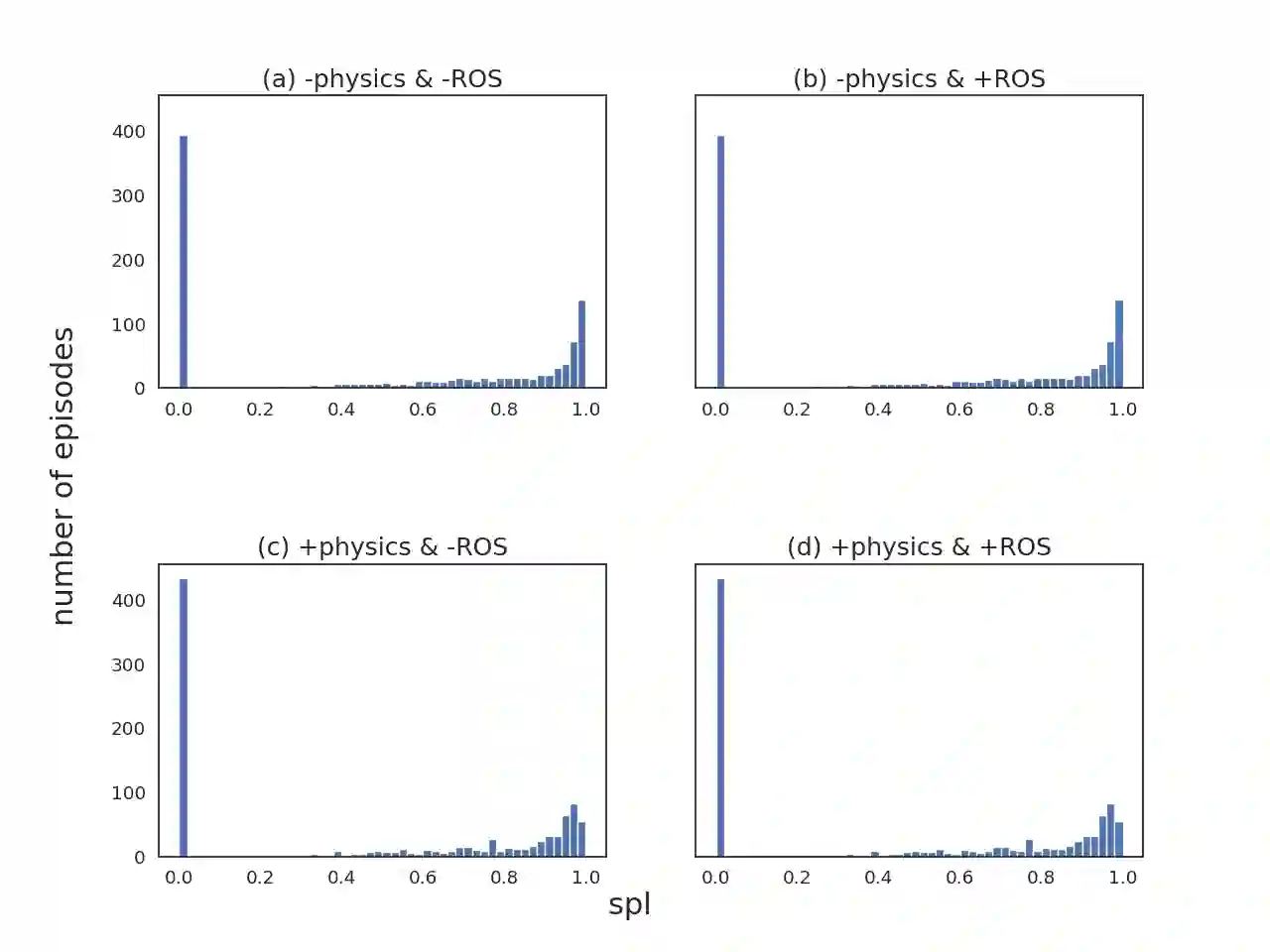
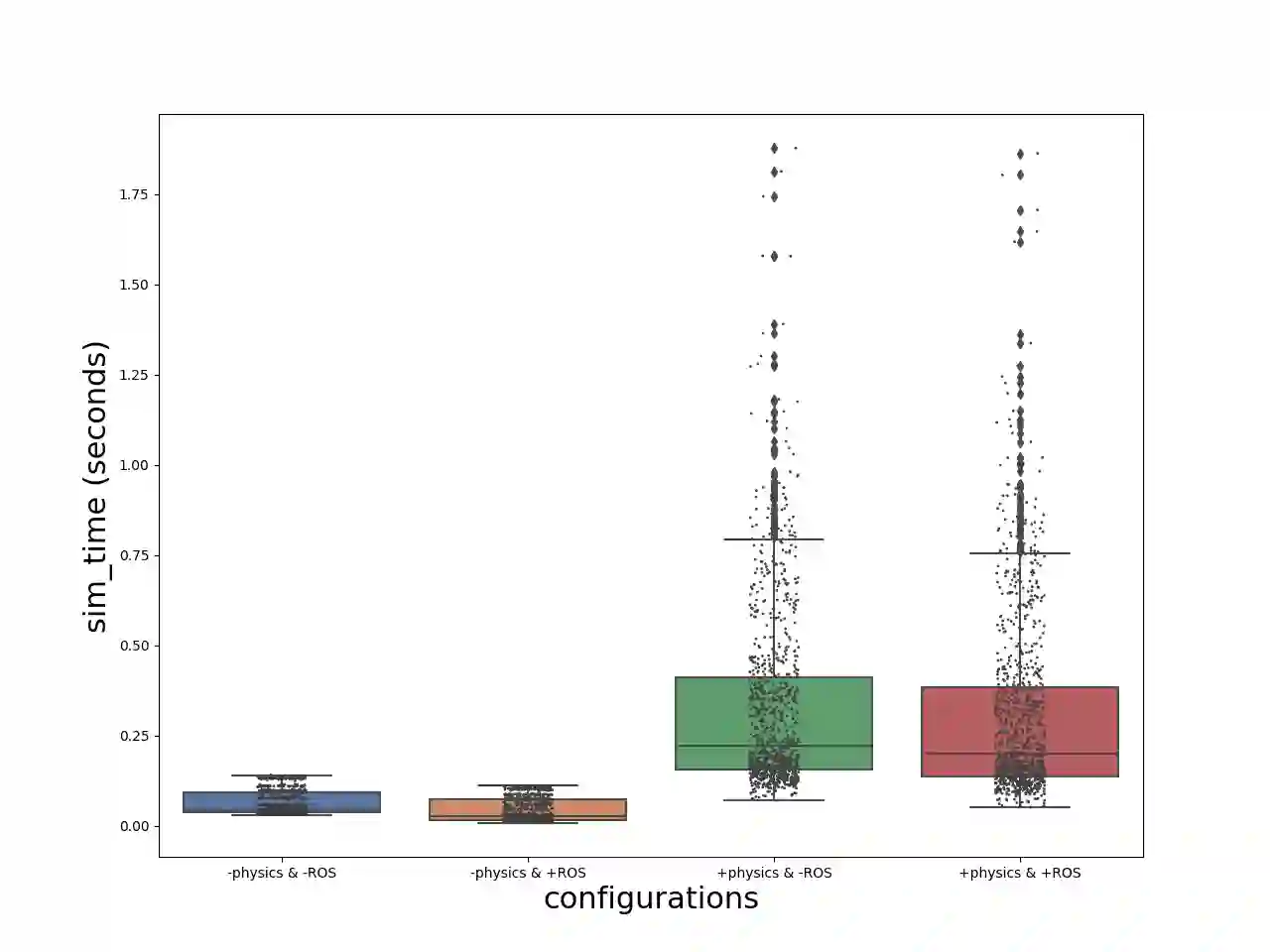
We introduce ROS-X-Habitat, a software interface that bridges the AI Habitat platform for embodied reinforcement learning agents with other robotics resources via ROS. This interface not only offers standardized communication protocols between embodied agents and simulators, but also enables physics-based simulation. With this interface, roboticists are able to train their own Habitat RL agents in another simulation environment or to develop their own robotic algorithms inside Habitat Sim. Through in silico experiments, we demonstrate that ROS-X-Habitat has minimal impact on the navigation performance and simulation speed of Habitat agents; that a standard set of ROS mapping, planning and navigation tools can run in the Habitat simulator, and that a Habitat agent can run in the standard ROS simulator Gazebo.
翻译:我们引入了ROS-X-Higend,这是一个软件界面,将AI-Habit平台连接成强化学习剂,通过ROS与其他机器人资源连接起来。这个界面不仅提供装有物剂和模拟器之间的标准化通信协议,而且能够进行基于物理的模拟。有了这一界面,机器人学家能够在另一个模拟环境中培训自己的HCDRL代理器,或者在Hente Sim内部开发自己的机器人算法。通过硅实验,我们证明ROS-X-Habitment对生境代理器的导航性能和模拟速度影响极小;一套标准的ROS绘图、规划和导航工具可以在生境模拟器中运行,而且生境代理器可以在标准的ROS模拟器 Gazebo运行。