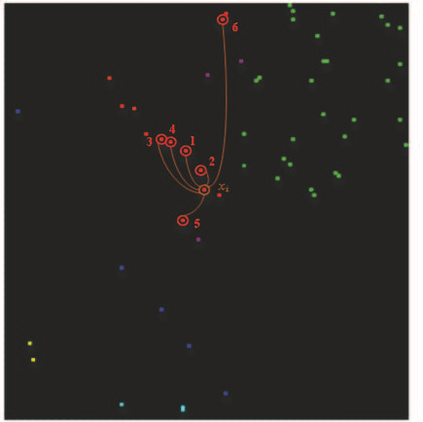
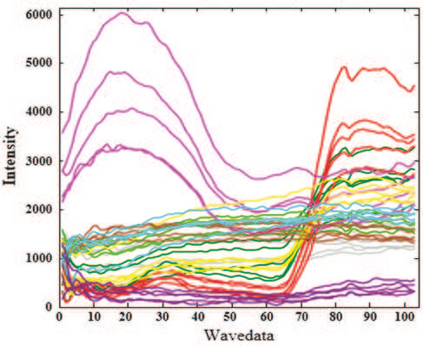
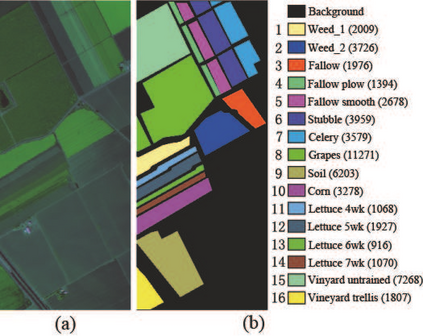
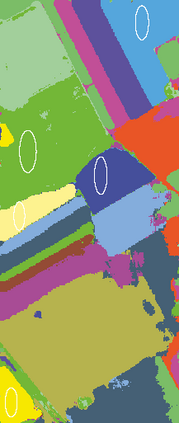
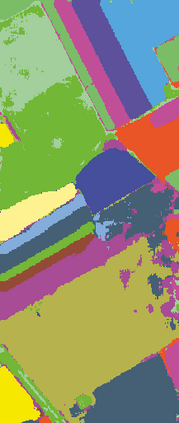
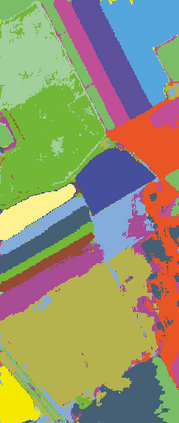
The graph embedding (GE) methods have been widely applied for dimensionality reduction of hyperspectral imagery (HSI). However, a major challenge of GE is how to choose proper neighbors for graph construction and explore the spatial information of HSI data. In this paper, we proposed an unsupervised dimensionality reduction algorithm termed spatial-spectral manifold reconstruction preserving embedding (SSMRPE) for HSI classification. At first, a weighted mean filter (WMF) is employed to preprocess the image, which aims to reduce the influence of background noise. According to the spatial consistency property of HSI, the SSMRPE method utilizes a new spatial-spectral combined distance (SSCD) to fuse the spatial structure and spectral information for selecting effective spatial-spectral neighbors of HSI pixels. Then, it explores the spatial relationship between each point and its neighbors to adjusts the reconstruction weights for improving the efficiency of manifold reconstruction. As a result, the proposed method can extract the discriminant features and subsequently improve the classification performance of HSI. The experimental results on PaviaU and Salinas hyperspectral datasets indicate that SSMRPE can achieve better classification accuracies in comparison with some state-of-the-art methods.
翻译:在超光谱图像的维度减少方面,已广泛应用了图嵌入方法(GE)来减少超光谱图像(HSI)的维度。然而,GE面临的一个主要挑战是如何选择适当的近邻来绘制图和探索HSI数据的空间信息。在本文中,我们提议了一种不受监督的维度减少算法,称为空间光谱复变算法(SSMRPE)来进行HSI分类。首先,使用加权平均过滤法(WMF)来预处理图像,目的是减少背景噪音的影响。根据HSI的空间一致性特性,SSMRPE方法使用新的空间光谱组合距离(SSCD)来结合空间结构和光谱信息,以选择有效的HSI像素的空间光谱邻居。然后,我们探索了每个点及其近邻之间的空间关系,以调整重建重量,提高多光谱重建效率。因此,拟议方法可以提取相距特征,随后改进HSI的分类性性。PaviaU和Salinas 超光谱数据集的实验结果表明,SAMPAR方法可以实现更好的分类。